
The release of Java 8 brought significant improvements, especially in the realm of working with collections, thanks to new features like the Stream API. This addition allows for data processing in a functional style, making code simpler, more expressive, and concise.
Why is the Stream API Needed?
Before the introduction of the Stream API, working with collections in Java often involved using loops and conditional operators for filtering, transforming, and aggregating data. This approach was cumbersome, hard to read, and often error-prone. Consider the following example:
public void printSpecies(List<SeaCreature> seaCreatures) {
Set<Species> speciesSet = new HashSet<>();
for (SeaCreature sc : seaCreatures) {
if (sc.getWeight() >= 10)
speciesSet.add(sc.getSpecies());
}
List<Species> sortedSpecies = new ArrayList<>(speciesSet);
Collections.sort(sortedSpecies, new Comparator<Species>() {
public int compare (Species a, Species b) {
return Integer.compare(a.getPopulation(), b.getPopulation());
}
});
for (Species s : sortedSpecies)
System.out.println(s.getName());
}This code looks overloaded, even though it performs fairly simple operations: filtering, sorting, and printing. With the introduction of the Stream API, such tasks can be handled much more easily and elegantly. Let’s rewrite the example using the Stream API:
public void printSpecies(List<SeaCreature> seaCreatures) {
seaCreatures.stream()
.filter(sc -> sc.getWeight() >= 10)
.map(SeaCreature::getSpecies)
.distinct()
.sorted(Comparator.comparing(Species::getPopulation))
.map(Species::getName)
.forEach(System.out::println);
}The Stream API provides a functional style of working with data, offering more compact, expressive, and readable code, while also facilitating parallel execution of operations.
Basics of Stream API
The Stream API is a powerful tool for data processing, ideal for a range of tasks, but it is not a one-size-fits-all solution. Its use is justified when your task fits the following pattern:
- Data Source: A collection or another structure containing elements.
- Transformation Operations: This includes filtering, sorting, mapping, and other operations on the elements.
- Result Saving: This involves placing the transformed data into a new structure (such as a list, set, etc.).
There is a humorous “conditional ailment” called “stream brain syndrome.” It occurs in developers who have just learned Stream API and feel a strong urge to use it everywhere, even when it is inappropriate. Symptoms include overcomplicating the code and applying Stream API in situations where simpler methods would be more effective.
Real-World Example
You can think of the Stream API as a conveyor belt on a fishing vessel:
- Data Source: The river, full of various sea creatures, symbolizes the raw data we are going to process.
- Filter: This is like the fishermen who pick only the desired types of fish from the catch, excluding unwanted species. In code, this corresponds to filtering elements using the
filter()method. - Map: This step is akin to packing the fish into containers. It transforms the elements (fish) into another form of data—“packages.” In the Stream API, this is done using the
map()method. - Collect: This is the stage where all the packed fish are loaded onto a truck for further transportation. In the Stream API, this is the final
collect()operation, which gathers all the results into a final data structure.
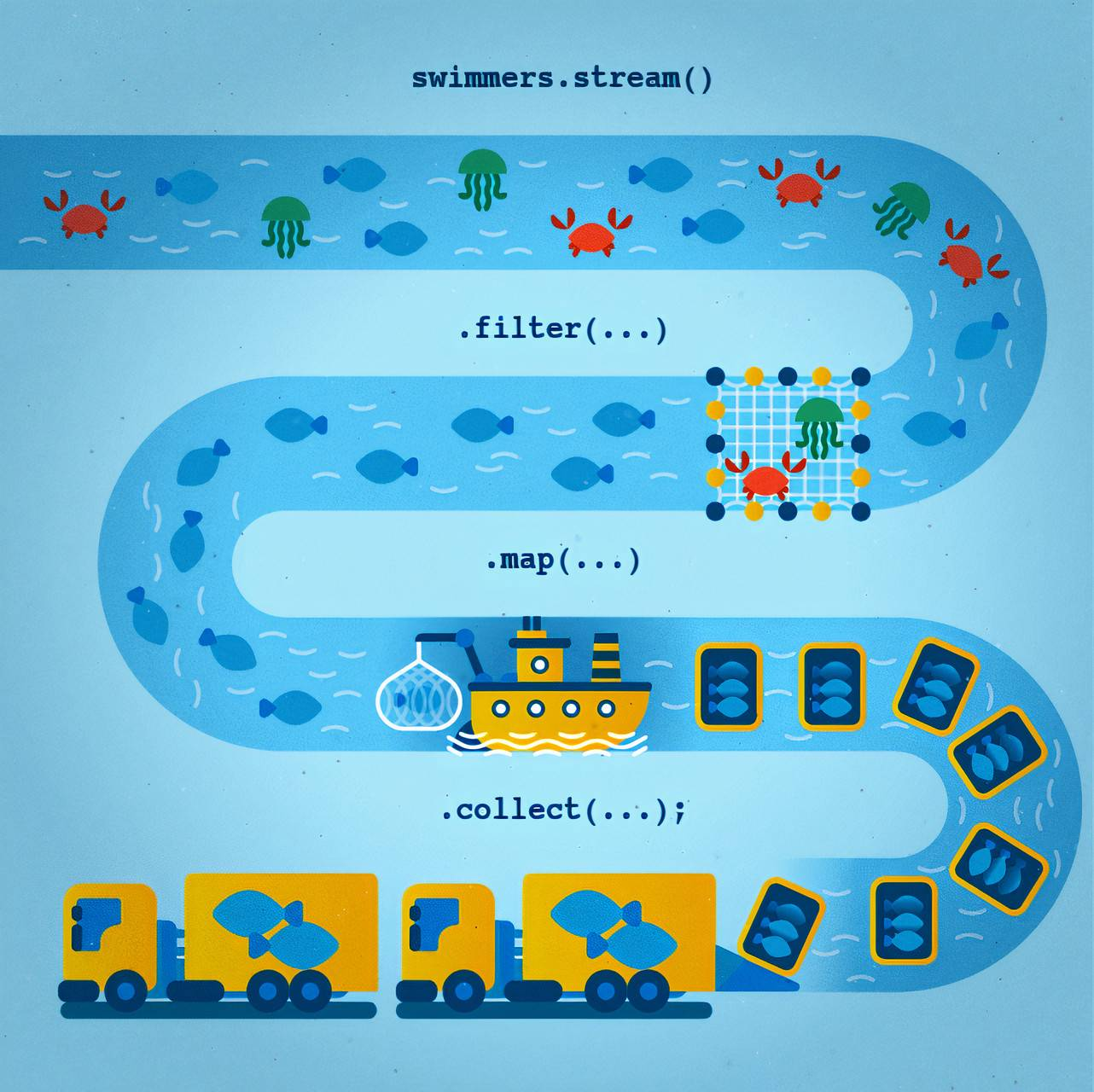
Thus, the Stream API creates a “flow” where each element passes through specific stages, much like on a conveyor belt, making the process efficient and consistent.
Components of the Stream API
The main components of the Stream API work together to organize an efficient and declarative data processing workflow.

- Source: This is the starting point from which data is fed into the processing stream. A source can be a collection, array, string, file, generator, or another data source.
- Operations: These are transformations and/or manipulations performed on the data in the stream, categorized into intermediate and terminal operations.
- Stream: A sequence of elements to be processed. The stream can be processed either in a single-threaded or multi-threaded manner.
- Pipeline: A chain of intermediate operations applied to the data, forming a sequence of transformations.
- Terminal: The final operation that closes the stream, producing output or converting the data into a final structure.
Data Sources for Streams
The Stream API supports many types of data sources. A stream can be created from collections, arrays, strings, files, and other structures. For example:
List<String> list = Arrays.asList("one", "two", "three");
Stream<String> streamFromList = list.stream();
String[] array = {"one", "two", "three"};
Stream<String> streamFromArray = Arrays.stream(array);Thus, two different data sources (a list and an array) can be transformed into streams.
Stream Operations
Stream API operations can be divided into two types: intermediate and terminal.
Intermediate Operations
Intermediate operations are declared, often using lambda expressions. They return a new stream, allowing you to build “chains” of operations (a pipeline). Intermediate operations are not executed immediately—they are deferred until a terminal operation is invoked. For example:
List<String> list = Arrays.asList("one", "two", "three", "two");
Stream<String> distinctStream = list.stream().distinct();Here, distinct() is an intermediate operation that removes duplicates from the stream. Intermediate operations follow the Fluent API principle, allowing you to build chains of data transformations.
Terminal Operations
Terminal operations complete the stream processing and return a result. They may involve actions such as counting, collecting into a collection, searching, or iterating over the elements:
List<String> list = Arrays.asList("one", "two", "three");
long count = list.stream().count();In this example, count() is a terminal operation that returns the number of elements in the stream. Once a terminal operation is called, the stream cannot be used again, which would lead to an error:
Stream<String> stream = Stream.of("one", "two", "three");
stream.forEach(System.out::println); // This is a terminal operation.
// Attempting to reuse the stream will cause an error.
// For example, the following line will throw an IllegalStateException.
stream.forEach(System.out::println);How Stream Works
The Stream API in Java processes data through chains of intermediate and terminal operations, but an important feature is that each element of the stream passes through the entire pipeline step-by-step. Operations are not applied to the collection as a whole; rather, they work on each element sequentially.
Consider the following code:
public static void main(String[] args) {
final List<String> list = List.of("one", "two", "three");
list.stream()
.filter(s -> {
System.out.println("filter: " + s);
return s.length() <= 3;
})
.map(s1 -> {
System.out.println("map: " + s1);
return s1.toUpperCase();
})
.forEach(x -> {
System.out.println("forEach: " + x);
});
}In this example, three operations are applied in sequence:
filter()— filters strings whose length is less than or equal to 3 characters.map()— converts the remaining strings to uppercase.forEach()— prints each element to the console.
At first glance, it might seem that the entire list is first filtered, then transformed, and finally printed to the console. However, thanks to lazy processing, this is not the case. Instead of processing all elements at each stage, the Stream API processes each element step-by-step through the entire pipeline.
filter: one
map: one
forEach: ONE
filter: two
map: two
forEach: TWO
filter: threeThis output shows the following:
- The first element, "one", passes through the
filter()method, then gets converted to uppercase viamap(), and finally is printed to the console. - The second element, "two", is processed similarly: filtering, transformation, and printing.
- The third element, "three", does not pass the filter because its length is greater than 3, so its processing stops after the
filter()call.
Thus, the first element is fully processed through the pipeline, followed by the second, while the third does not pass the filter and its processing halts at that stage. This approach is important for the efficiency and proper functioning of streams in Java. Why?
This step-by-step approach simplifies and makes parallel processing safer. Since each element is processed independently, it is easy to transition from a sequential stream to a parallel stream.
Stateless and Stateful Operations
Operations in the Stream API are divided into two types: stateless (without state) and stateful (with state), depending on how they process the stream elements.
- Stateless operations, such as
map()andfilter(), process each stream element independently of others. They don’t require information about previous or subsequent elements to function, making them ideal for parallel processing. For example, in the filter() method, each element is checked against a condition individually, and its result does not depend on other elements. - Stateful operations, such as
sorted(),distinct(), or limit(), require information about other elements in the stream. These operations cannot begin to return results until they process part or all of the stream. For example, sorted() needs to collect all the elements first to sort them, and only then can it pass them to the subsequent stages.
If the pipeline consists only of stateless operations, the stream can be processed “in one pass,” which makes the execution fast and efficient. However, when stateful operations are added, the stream is divided into sections, and each section must complete its processing before the next one can begin.
Let’s add a sorting operation to our example and see how it changes the execution:
public static void main(String[] args) {
final List<String> list = List.of("one", "two", "three");
list.stream()
.filter(s -> {
System.out.println("filter: " + s);
return s.length() <= 3;
})
.map(s1 -> {
System.out.println("map: " + s1);
return s1.toUpperCase();
})
.sorted()
.forEach(x -> {
System.out.println("forEach: " + x);
});
}filter: one
map: one
filter: two
map: two
filter: three
forEach: ONE
forEach: TWOBefore performing the sorting, all elements of the stream must first pass through the filter. Unlike the previous example, where each element was processed immediately as it passed through, here, filtering happens for all elements before moving to the next operations.
After filtering, the stream gathers all the elements that passed the check. Only after that does the sorting occur, followed by the execution of map() for each element. The order of output in the forEach() method changes according to the result of the sorting.
Thus, the sorted() operation creates a “synchronization point,” where all elements must be processed first before the pipeline can complete. This can be useful in some cases but may also slow down processing, especially for large datasets.
Spliterator
At the core of all collections in Java lies the Iterator interface, which allows elements to be traversed sequentially. However, for working with data streams in the Stream API, a more powerful mechanism is used — Spliterator, essentially an “iterator on steroids.” Its key feature is the ability to split data for independent processing by multiple threads.
Spliterator Methods
The Spliterator interface defines four key methods:
long estimateSize(): Returns an estimate of the number of elements remaining in the collection.boolean tryAdvance(Consumer<? super T> action): Processes the next element in the collection by applying aConsumerfunction to it. If the element exists, it returnstrue; otherwise, it returnsfalse.int characteristics(): Returns a set of bitwise flags that describe the characteristics of the currentSpliterator. These flags help optimize the stream’s processing based on the properties of the data, such as order or uniqueness.Spliterator<T> trySplit(): This method attempts to split the currentSpliteratorinto two parts. It returns a newSpliteratorthat will handle part of the data, while the originalSpliteratorreduces its size to handle the remaining portion. If the split is not possible, it returnsnull.
Characteristics of Spliterator
A Spliterator has a set of characteristics that describe the data it works with. These characteristics help the Stream API plan and execute operations more efficiently, especially in parallel processing. Here are the main characteristics:
ORDERED: The elements have a specific order that must be preserved.DISTINCT: All elements are unique, as determined by theequals()method.SORTED: The elements are already sorted.SIZED: The size of the data source is known in advance.NONNULL: All elements are guaranteed to be non-null.IMMUTABLE: The elements cannot be changed during processing.CONCURRENT: The data can be modified by other threads without affecting the Spliterator’s operation.SUBSIZED: All childSpliteratorswill know the exact size of the data they have left to process.
These characteristics help optimize stream processing. For example, if the data is already sorted (SORTED), there’s no need to sort it again. Or, if the collection contains unique elements (DISTINCT), additional uniqueness checks can be skipped.
Each operation in the stream can modify these characteristics. For instance, the map() operation typically resets the SORTED and DISTINCT flags because transforming the elements may disrupt their ordering or uniqueness. However, the SIZED flag remains because the map() operation does not change the number of elements in the stream.
Parallel Execution
The Java Stream API provides the ability to process data in parallel, which can significantly improve performance on multi-core processors. However, it’s important to remember that parallel execution adds complexity and overhead, such as thread management and data synchronization. Therefore, using parallel streams should be carefully justified and applied only in cases where there is a clear benefit from parallelization.
To enable parallel stream processing, you can use the parallelStream() or parallel() methods. By default, streams are executed sequentially, but with an explicit call to one of these methods, the stream switches to parallel mode.
For dividing collections into parts that can be processed in parallel, Java uses Spliterator and its trySplit() method. This method divides the data into sub-tasks, which can then be distributed across multiple threads. Each part is processed independently, and the results are merged once all threads have completed their work.
From an execution standpoint, parallel stream processing is similar to sequential processing. The difference is that instead of a single set of operations, multiple copies of the operations are created—each copy runs on its own segment of data. For example, filtering, mapping, and aggregation operations are applied in parallel to each fragment of data, and once completed, the results are combined into a final output.
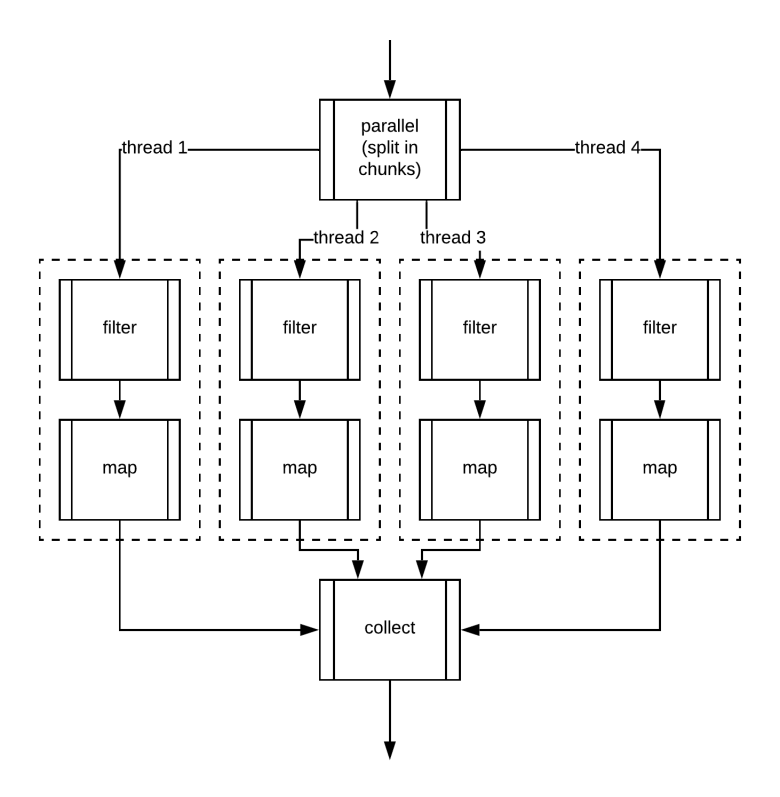
Placement of .parallel() in the Pipeline
You might wonder: is the position of the parallel() method in the pipeline important?
The answer is no. The placement of the method in the chain does not affect the behavior of the stream. Calling parallel() merely sets the CONCURRENT characteristic, which switches the stream to parallel mode. Similarly, calling sequential() removes this characteristic and returns the stream to sequential mode.
Java uses the ForkJoinPool to distribute tasks for parallel streams. This is a common thread pool where tasks are broken down into smaller fragments and distributed across threads. The same approach is used in CompletableFuture. If necessary, you can specify your own thread pool if the default pool is overloaded or if you need to modify its behavior.
What is a Stream?
At the heart of the Stream API is the concept of streams, which represent a sequence of operations performed on data. Streams enable data collections to be processed at a higher level of abstraction, providing convenient and efficient tools for manipulating data.
Key Properties of Streams:
- Declarativeness: Streams in Java allow developers to specify what should be done with the data, rather than how it should be implemented. Instead of explicitly using loops and conditions, a developer can define a set of operations that Java will execute under the hood. This approach improves the readability and simplicity of code, as it hides the complex implementation details.
- Laziness: Operations in a stream are not executed immediately—they are “deferred” until a terminal operation is invoked. This allows Java to optimize the execution of operations, processing data as needed and avoiding unnecessary work.
- Single-Use: Streams can be used only once. Once a terminal operation has been called, the stream is considered exhausted and can no longer be used. If another operation needs to be performed on the same data, a new stream must be created.
- Parallelism: By default, streams are executed sequentially, but they can easily be parallelized using the
parallelStream()orparallel()methods. This can significantly speed up the processing of large data sets on multi-core systems. Parallel streams automatically split the data into chunks and distribute tasks across multiple threads, ensuring more efficient use of CPU resources.
Stream Methods
Now that we have covered the core principles of how streams work, let’s explore how to create a stream and work with it using various methods provided by the Stream API.
Creating a Stream
There are several ways to create a stream in Java. For example, you can obtain a stream from a collection using the stream() method, or create one from an array using Arrays.stream(). Once a stream is created, you can perform various operations on it using the methods offered by the Stream API.
From a Collection
You can create a stream from any collection, such as a list or a set, using the stream() method.
Collection<Integer> list = new ArrayList<>();
Stream<Integer> stream = list.stream();From an Array
To create a stream from an array, you can use the Arrays.stream() method.
int[] numbers = {1, 2, 3};
Stream<Integer> stream = Arrays.stream(numbers).boxed();boxed() method.From a String
To create a stream of characters from a string, you can use the chars() method, which returns a stream of type IntStream.
Path path = Paths.get("file.txt");
Stream stream = Files.lines(path);From a File
A stream can be created from the lines of a file using the Files.lines() method. This method reads a file line by line and returns a stream of strings.
Path path = Paths.get("file.txt");
Stream stream = Files.lines(path);Many methods, such as Files.lines(), Files.find(), Pattern.splitAsStream(), and others, use Iterator to retrieve data, which is then converted into a Spliterator for parallel processing. However, Iterator lacks information about the size of the data, which can negatively affect the efficiency of parallel processing. Without accurate size information, Spliterator cannot efficiently divide the data, leading to a potential reduction in the performance of parallel operations.
Generating Streams
A stream can also be created using the Stream.generate() method, which takes a Supplier interface. The Supplier returns a new value with each invocation. This is convenient for generating infinite streams of data.
Stream stream = Stream.generate(() -> new Random().nextInt());Builder
For more flexible stream creation, you can use the Stream.Builder. This allows you to add elements to the stream step by step and then create the stream using the build() method.
Stream.Builder builder = Stream.builder();
builder.add(1);
builder.add(2);
builder.add(3);
Stream stream = builder.build();Intermediate Methods
After covering stream creation, let’s explore the intermediate methods of the Stream API, which allow you to process elements within a stream and produce new streams for further operations.
filter(Predicate)
The filter() method is used to create a new stream containing only those elements that satisfy a specified condition. This method takes a functional interface Predicate, which defines the condition for filtering.
Example: Filtering a list of numbers to keep only even numbers.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Stream<Integer> evenNumbersStream = numbers.stream()
.filter(n -> n % 2 == 0);
evenNumbersStream.forEach(System.out::println); // prints 2, 4, 6, 8, 10Characteristics:
- Stateless: The operation is stateless because each element is evaluated independently.
ORDERED: The order of elements is typically preserved.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Retained if present in the originalSpliterator.SIZED,SUBSIZED: Lost because the number of elements after filtering is not known in advance.
map(Function)
The map() method transforms each element of the stream using a function provided as a lambda expression or method reference. As a result, a new stream is created containing the transformed elements, while the original stream remains unchanged.
Example: Transforming strings into their lengths.
List<String> words = Arrays.asList("apple", "banana", "orange", "peach");
Stream<Integer> lengthsStream = words.stream()
.map(String::length);
lengthsStream.forEach(System.out::println); // prints 5, 6, 6, 5Characteristics:
- Stateless: The operation is stateless because each element is transformed independently.
ORDERED: Order is preserved.DISTINCT,SORTED: These characteristics may be lost because transformed data can affect uniqueness or order.SIZED,SUBSIZED: Typically retained.NONNULL: May be lost if the transformed value allows null.IMMUTABLE,CONCURRENT: Retained.
flatMap(Function)
The flatMap() method is used to transform each element of the stream into a stream itself and “flatten” all these streams into one unified stream. This is particularly useful when working with nested data structures such as lists of lists.
Example: Converting a list of lists into a flat stream.
List<List<Integer>> listOfLists = Arrays.asList(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9)
);
Stream<Integer> flattenedStream = listOfLists.stream()
.flatMap(Collection::stream);
flattenedStream.forEach(System.out::println); // prints 1, 2, 3, 4, 5, 6, 7, 8, 9Characteristics:
- Stateless: The operation is stateless because each element is flattened independently
ORDERED: Order is typically preserved.DISTINCT,SORTED: Lost because merging streams can affect uniqueness or order.SIZED,SUBSIZED: Lost because the number of elements after flattening is not known in advance.NONNULL: May be lost if one of the nested streams containsnull.IMMUTABLE,CONCURRENT: Retained.
The map() method transforms each element of the stream into a new element. In contrast, the flatMap() method transforms each element into a stream and then “flattens” all these streams into one flat stream. This makes flatMap() useful for working with nested data structures, such as lists of lists.
distinct()
The distinct() method returns a new stream that contains only the unique elements from the original stream. The uniqueness of elements is determined based on their natural order (using the equals() method if they are objects) or a custom comparator. This operation is useful when you need to eliminate duplicates from a dataset.
Example: Removing duplicates from a stream of numbers.
List<Integer> numbers = Arrays.asList(1, 2, 3, 2, 1, 4, 5, 3, 5);
List<Integer> uniqueNumbers = numbers.stream()
.distinct()
.collect(Collectors.toList());
System.out.println(uniqueNumbers); // prints [1, 2, 3, 4, 5]Characteristics:
- Stateful: Requires knowledge of all elements in the stream to determine uniqueness.
ORDERED: The order is preserved if the original stream was ordered.DISTINCT: This characteristic is always set after performing the operation.SORTED: Retained if the original stream was sorted.SIZED,SUBSIZED: Lost because the number of unique elements is not known in advance.NONNULL,IMMUTABLE,CONCURRENT: Retained if these characteristics were present in the original stream.
limit(n)
The limit(n) method returns a new stream containing at most n elements from the original stream. If the original stream contains fewer than n elements, the stream will contain all available elements. This method is useful for limiting the size of a sample or result set.
Example: Limiting the stream to the first five elements.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> limitedNumbers = numbers.stream()
.limit(5)
.collect(Collectors.toList());
System.out.println(limitedNumbers); // prints [1, 2, 3, 4, 5]Characteristics:
- Stateful: The operation requires knowing the exact count of elements to limit the stream.
ORDERED: The order is preserved if the original stream was ordered.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Retained if these characteristics were present in the original stream.SIZED,SUBSIZED: May be retained if the original stream’s size was known and exceeds the limit value. If the size was unknown, these characteristics are lost.
skip(n)
The skip(n) method returns a new stream that excludes the first n elements from the original stream. If the original stream contains fewer than n elements, the returned stream will be empty. This method is useful when you need to skip a specific number of elements from the start of the stream.
Example: Skipping the first five elements of the stream.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> skippedNumbers = numbers.stream()
.skip(5)
.collect(Collectors.toList());
System.out.println(skippedNumbers); // prints [6, 7, 8, 9, 10]Characteristics:
- Stateful: The operation requires tracking the number of skipped elements.
ORDERED: The order is preserved if the original stream was ordered.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Retained if these characteristics were present in the original stream.SIZED,SUBSIZED: May be lost if the number of skipped elements is unknown or the original stream was not sized (i.e.,SIZEDorSUBSIZED). If the size of the original stream is known and exceeds the skip value, these characteristics are retained.
sorted()
The sorted() method creates a new stream containing the elements of the original stream, sorted in their natural order (for objects implementing the Comparable interface) or in the order specified by a provided comparator. This operation is useful for sorting elements in a stream before performing further operations such as filtering or aggregation.
Example: Sorting a list of strings in alphabetical order.
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");
List<String> sortedNames = names.stream()
.sorted()
.collect(Collectors.toList());
System.out.println(sortedNames); // prints ["Alice", "Bob", "Charlie", "David"]Comparable interface, a ClassCastException will be thrown. To avoid this, you can pass a custom comparator to the sorted() method.Characteristics:
- Stateful: Requires tracking all elements to perform the sorting.
ORDERED: Set after sorting, as the elements are now ordered.DISTINCT: Retained if it was present in the originalSpliterator.SORTED: Always set because the stream is now ordered.SIZED,SUBSIZED: Retained if present in the originalSpliterator.NONNULL,IMMUTABLE,CONCURRENT: Retained if present in the originalSpliterator.
takeWhile(Predicate)
The takeWhile() method creates a new stream that includes elements from the original stream as long as they satisfy the specified condition (Predicate). As soon as the condition becomes false, the stream terminates. If the first element does not match the predicate, an empty stream is returned.
Example: Returning numbers less than 5 from a stream of numbers.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> takenNumbers = numbers.stream()
.takeWhile(n -> n < 5)
.collect(Collectors.toList());
System.out.println(takenNumbers); // prints [1, 2, 3, 4]Characteristics:
- Stateful: Requires tracking stream elements as long as the condition holds true.
ORDERED: Retained if the original stream was ordered.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Retained if present in the original Spliterator.SIZED,SUBSIZED: May be lost since the number of elements aftertakeWhile()is unknown.
dropWhile(Predicate)
The dropWhile() method returns a new stream that excludes all elements from the original stream that satisfy the specified condition (Predicate) until an element is found that does not satisfy the condition. Once the first element that doesn’t meet the predicate is encountered, all subsequent elements are included in the new stream, regardless of whether they satisfy the condition.
Example: Dropping numbers less than 5 from the stream. In this example, all numbers less than 5 are skipped, and the stream starts from 5.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> droppedNumbers = numbers.stream()
.dropWhile(n -> n < 5)
.collect(Collectors.toList());
System.out.println(droppedNumbers); // prints [5, 6, 7, 8, 9, 10]Characteristics:
- Stateful: Requires tracking elements until they no longer satisfy the condition.
ORDERED: Retained if the original stream was ordered.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Retained if present in the original Spliterator.SIZED,SUBSIZED: May be lost since the number of elements afterdropWhile()is unknown.
peek(Consumer)
The peek() method allows you to add an intermediate operation to a stream that performs an action on each element without altering the stream itself. It is useful for tasks such as logging, debugging, or profiling.
Example: Logging stream elements.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream()
.peek(System.out::println)
.collect(Collectors.toList());In this example, the peek() method prints each element to the console, but the stream and its elements remain unchanged.
Characteristics:
- Stateless: The operation is performed for each element independently.
ORDERED,DISTINCT,SORTED,SIZED,SUBSIZED,NONNULL,IMMUTABLE,CONCURRENT: All characteristics are retained because the operation does not modify the elements of the stream.
peek() method is useful for performing non-modifying operations on stream elements, such as logging or debugging. However, improper use of peek() can lead to undesirable results, especially during parallel processing.Since
peek() is an intermediate operation, modifying elements within it can cause unpredictable behavior. In general, it’s recommended to use peek() only for auxiliary tasks, such as debugging. If you need to modify elements, it’s better to use map() instead.Terminal Methods
Terminal methods in the Stream API trigger the processing of the stream and terminate it. Once a terminal method is invoked, the stream can no longer be used. Let’s look at some of the main terminal methods frequently used in Java.
forEach(Consumer)
The forEach() method applies the provided function (a Consumer interface object) to each element of the stream.
It is not recommended for production use because it does not return a result and relies solely on “side effects.” This makes it inconvenient and potentially problematic in parallel stream execution, where synchronization issues may arise.
Example of poor usage of forEach():
public int getSum (Stream<Integer> s) {
int [] sum = new int [1];
s.forEach ( i -> sum [0] += i);
return sum [0];
}Example of a side effect caused by forEach() usage. Never do this.
This example demonstrates a side effect: modification of external state (sum[0]). If parallel execution is applied, synchronization issues will arise because multiple threads may modify the same array element simultaneously, resulting in incorrect outcomes.
collect(Collector)
The collect() method is one of the most useful and frequently used terminal methods. It is used to transform stream elements into a specific data structure (such as List, Set, or Map), a string, or an aggregated value.
Stream<String> stream = Stream.of("Alice", "Bob", "Charlie");
List<String> list = stream.collect(Collectors.toList());
System.out.println(list); // выводит [Alice, Bob, Charlie]The collect() method gathers elements into a list, but it can be configured to collect data into any other structure, such as sets or strings. This method accepts a Collector object, which defines how the elements will be collected.
Collector Class
The Collector interface encapsulates the process of combining stream elements into a single result structure.
The Collectors class provides a set of predefined static methods for performing common operations, such as transforming elements into lists, sets, and other data structures.
Some popular methods in the Collectors class:
toList(): Returns a collector that collects elements into a list.toSet(): Collects elements into a set.joining(): Joins stream elements into a single string.counting(): Counts the number of elements in the stream.
The following example shows how to create a custom collector that accumulates elements into a list. In this case, a lambda expression is used to define the collector’s behavior:
Stream<?> stream;
List<?> list = stream.collect(Collectors.toList());
// The above collector is equivalent to this code:
list = stream.collect(
() -> new ArrayList<>(), // defines the structure
(list, t) -> list.add(t), // defines how to add elements
(l1, l2) -> l1.addAll(l2) // defines how to merge two structures into one
);Optional<T> findFirst()
The findFirst() method returns the first element of a stream wrapped in an Optional<T>. This method is useful when it’s important to retrieve the first element (for example, in an ordered stream), usually in combination with filtering.
Example: Extracting the first element that satisfies a condition.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> first = numbers.stream()
.filter(n -> n > 3)
.findFirst();
System.out.println(first.get()); // выводит 4Optional<T> findAny()
The findAny() method returns any element from the stream wrapped in an Optional<T>. In single-threaded scenarios, its behavior is identical to findFirst(), but in parallel stream processing, it can return any element, which can improve performance by not requiring the first element in the sequence.
findAny() is useful when the order of elements does not matter, and you just want to obtain a result as quickly as possible.
reduce()
The reduce() method is used to combine all elements of a stream into a single result. It differs from collect() in that it works with a binary associative function, which takes two values and returns one. reduce() is particularly useful for tasks such as summing numbers or finding the maximum or minimum value in a stream.
Example: Summing numbers using reduce().
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> sum = numbers.stream().reduce((a, b) -> a + b);
System.out.println(sum.get());The method returns an Optional<T> because the stream could be empty, and this prevents errors when working with missing elements.
To simplify, you can use the version of reduce() that provides an initial value, avoiding the need to handle Optional:
int sum = numbers.stream().reduce(0, Integer::sum);
System.out.println(sum); // prints 15anyMatch(Predicate)
The anyMatch() method checks if at least one element in the stream matches the given condition. If at least one element satisfies the predicate, it returns true; otherwise, it returns false.
Example: Checking if the stream contains even numbers.
boolean hasEven = numbers.stream().anyMatch(n -> n % 2 == 0);
System.out.println(hasEven); // prints trueallMatch(Predicate)
The allMatch() method returns true if all elements in the stream match the given predicate. If at least one element does not satisfy the predicate, the method returns false.
Example: Checking if all elements in the stream are positive numbers.
boolean allPositive = numbers.stream().allMatch(n -> n > 0);
System.out.println(allPositive); // prints trueShort-Circuiting
Short-circuiting operations in the Stream API allow data stream processing to stop as soon as the first suitable result is found, without processing the remaining elements. This significantly improves performance, especially when working with large streams, as it eliminates the need to process all elements.
Examples of short-circuiting operations include methods such as anyMatch(), allMatch(), noneMatch(), findFirst(), and findAny().
The behavior of short-circuiting operations can vary depending on whether the stream is sequential or parallel:
- In sequential streams, methods like
findFirst()orfindAny()return the first element in order, since the processing occurs sequentially. - In parallel streams, the
findAny()method can return any element because each stream thread processes its own segment of data independently. This allows for faster completion without waiting for all elements to be processed, as is the case in sequential streams.
Advanced Tips and Usage
This section gathers advanced approaches and tips for working with the Stream API, which can help make your code more flexible and secure.
Returning Stream<T> Instead of Collections
One useful approach is returning a Stream<T> instead of a collection (e.g., List, Set, etc.) in API methods. This helps protect internal data from modification and gives the consumer the freedom to choose which collection to gather the data into.
public Stream<Worker> getWorkers() {
return workers.stream();
}The consumer of this method can then decide which data structure to collect the stream into:
List<Worker> workerList = service.getWorkers().collect(Collectors.toList());
Set<Worker> workerSet = service.getWorkers().collect(Collectors.toSet());In this way, you ensure both data protection and flexibility for the users of your API.
Grouping Elements
For complex data processing, it’s often necessary to group elements by a certain attribute. You can achieve this using the collect() method along with Collectors.groupingBy(). This method allows you to group elements by various parameters and even perform additional operations on the grouped data.
To group data by some attribute, you need to use the collect() method and Collectors.groupingBy().
Grouping by Position (into Lists):
Map<String, List<Worker>> map1 = workers.stream()
.collect(Collectors.groupingBy(Worker::getPosition));Grouping by Position (into Sets):
Map<String, Set<Worker>> map2 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition, Collectors.toSet()
)
);Counting Workers for Each Position:
Map<String, Long> map3 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition, Collectors.counting()
)
);Grouping by Position, Collecting Only Names:
Map<String, Set<String>> map4 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition,
Collectors.mapping(
Worker::getName,
Collectors.toSet()
)
)
);Calculating Average Salary by Position:
Map<String, Double> map5 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition,
Collectors.averagingInt(Worker::getSalary)
)
);Grouping by Position, With Names in a String Format:
Map<String, String> map6 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition,
Collectors.mapping(
Worker::getName,
Collectors.joining(", ", "{","}")
)
)
);Grouping by Position and Age:
Map<String, Map<Integer, List<Worker>>> collect = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition,
Collectors.groupingBy(Worker::getAge)
)
);Conclusion
Overall, the Stream API in Java is a powerful tool for data processing, which can significantly change your approach to programming. It allows you to organize your code into readable and concise sequences of operations, making it ideal for working with large datasets.
However, it’s important to remember that the Stream API is not suitable for every task. If your task doesn’t fit the “source-transformation-collection” pattern, you may want to consider other Java tools.
In any case, understanding and knowing how to use the Stream API is a vital skill for every Java developer, and this tool is definitely worth the time invested in learning it.
