
Репликация баз данных — это процесс копирования и синхронизации данных на нескольких серверах. Основная цель репликации заключается в обеспечении высокой доступности данных и повышении производительности системы.
В современном мире, где пользователи ожидают мгновенного доступа к информации, репликация баз данных играет ключевую роль. Представьте крупный интернет-магазин: миллионы пользователей одновременно отправляют запросы, покупают товары и обновляют данные. Благодаря репликации каждый запрос может быть обработан быстро, независимо от того, где находится пользователь, а данные остаются доступными даже в случае сбоя на одном из серверов.
Этот метод помогает предотвратить потерю данных и минимизировать время простоя, что особенно важно для приложений с высокими требованиями к доступности и скорости отклика. Кроме того, репликация позволяет распределять нагрузку между серверами, что особенно полезно для систем с большим количеством запросов. Например, один сервер может обрабатывать операции чтения, тогда как другой сосредоточится на записи, повышая общую производительность системы.
В рамках репликации обычно существует ведущая копия, называемая master, и несколько ведомых реплик, называемых slave. Стоит отметить, что репликация не отменяет первичное копирование базы данных: для создания новой реплики сначала необходимо сделать полную копию данных с основного сервера. Это может быть дамп базы или инкрементальное копирование, после чего запускается процесс репликации, и изменения начинают синхронизироваться.
Для чего делают репликацию?
- Отказоустойчивость: Если один сервер выходит из строя, другие реплики продолжают обслуживать запросы, обеспечивая непрерывный доступ к данным.
- Масштабирование чтения: Нагрузка на чтение может быть распределена между несколькими репликами, что улучшает производительность системы.
- Распределение нагрузки. Сложные аналитические запросы для построения отчётов и асинхронное резервное копирование базы данных могут выполняться на отдельных репликах, не нагружая основной сервер, который продолжает обрабатывать пользовательские запросы.
- Географическое распределение: Реплики могут быть размещены ближе к пользователям в разных регионах, уменьшая задержки доступа к данным.
Недостатки репликации
- Сложность управления: Управление несколькими репликами требует дополнительных ресурсов и сложной конфигурации. Это включает настройку синхронизации данных, мониторинг состояния реплик и разрешение конфликтов при одновременном обновлении данных на разных серверах.
- Ресурсозатратность: Поддержание нескольких копий данных требует дополнительных серверных ресурсов, что увеличивает расходы на инфраструктуру. Кроме того, обслуживание и поддержка такой системы требуют больших затрат на администрирование и мониторинг.
- Проблемы консистентности: В асинхронной репликации данные на разных репликах могут быть несогласованными. Это может привести к тому, что пользователь получит разные результаты для одного и того же запроса, если изменения на основном сервере ещё не были реплицированы на все копии.
Чем репликация не является
- Репликация не заменяет резервные копии базы данных.
- Репликация в основном направлена на масштабирование чтения и обеспечение отказоустойчивости. Для улучшения производительности записи рекомендуется использовать шардирование БД.
Прежде чем углубляться в тему репликации, важно иметь базовое представление о том, как работают базы данных "под капотом". Это включает понимание того, как базы данных управляют транзакциями, обеспечивают целостность данных и обрабатывают запросы.
Журнал БД
Журнал базы данных — это ключевой элемент работы системы. Его основная цель заключается в том, чтобы фиксировать все изменения, происходящие в базе данных, до их окончательного применения. Это необходимо для обеспечения надёжности транзакций и реализации механизмов репликации.
Перед тем как выполнить SQL-запрос, база данных записывает в журнал все действия, которые планируется произвести с данными. После того как запись в журнале подтверждена и зафиксирована на диске, база данных вносит изменения в оперативную память. Спустя некоторое время эти данные окажутся на диске в хранилище.
Такой процесс даёт два ключевых преимущества:
- Надежность: В случае сбоя системы можно восстановить данные, используя журнал, который содержит информацию о последних зафиксированных транзакциях. Это позволяет вернуть базу данных в состояние, близкое к тому, в котором она находилась до сбоя.
- Консистентность: Все транзакции, записанные в журнал, будут применены в том порядке, в котором они были зафиксированы. Это гарантирует, что данные не потеряются, а целостность базы данных будет сохранена даже в случае одновременного выполнения множества запросов.
Роль журнала БД в репликации
Журнал базы данных играет ключевую роль в процессе репликации. Прямой способ организовать репликацию — это скопировать журнал транзакций с master-сервера на slave-реплику и применить все команды, записанные в нём. Это позволяет точно воспроизвести последовательность изменений, произошедших в основной базе данных, на других серверах.
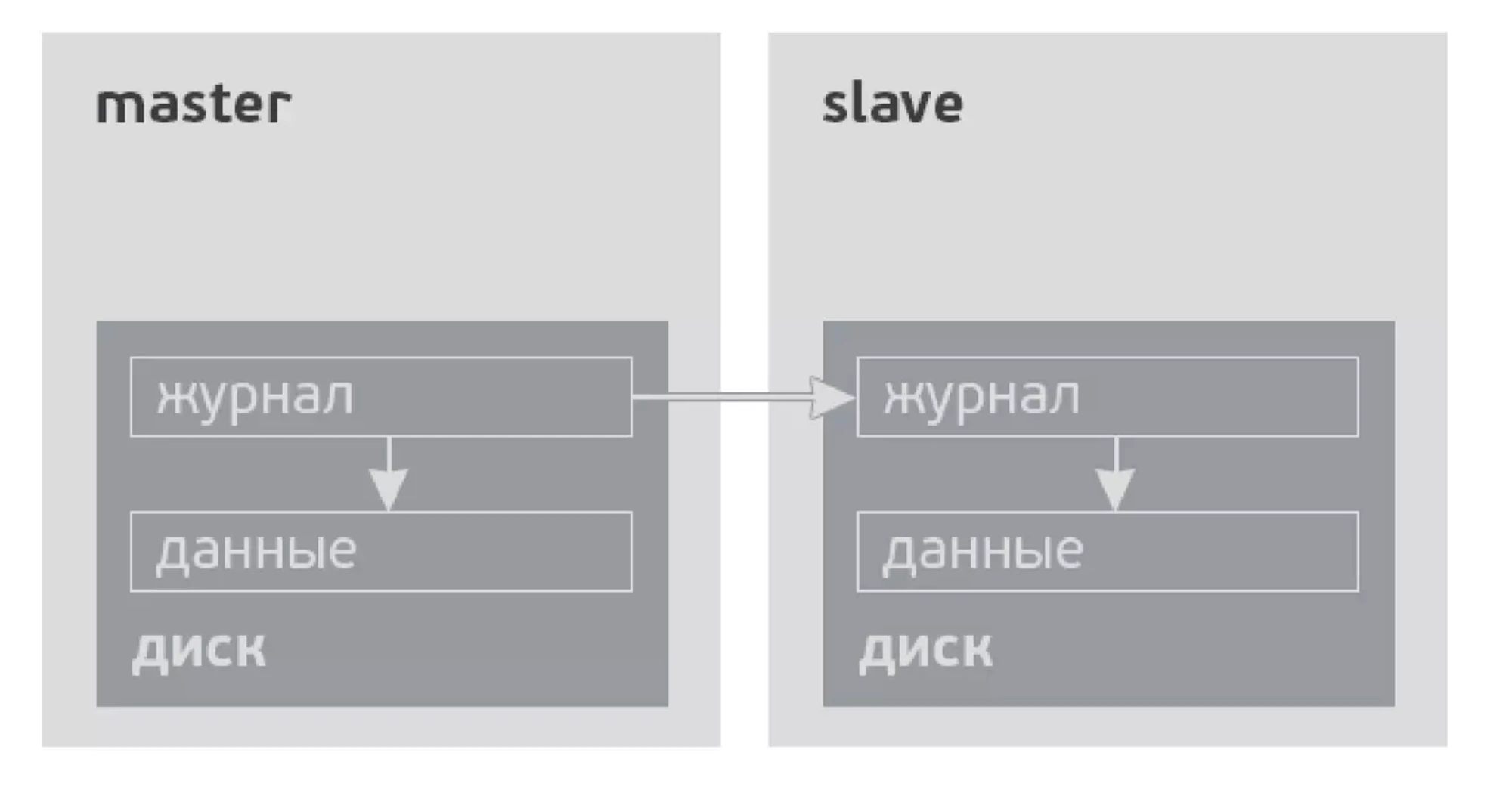
Однако не всё так просто. Формат и возможности журнала напрямую зависят от конкретной СУБД.
Репликация в PostgreSQL
В PostgreSQL репликация строится на основе Write-Ahead Log (WAL), журнала, в который записываются все изменения данных. Этот журнал фиксирует все операции, включая обновление таблиц, создание триггеров и хранимых процедур. WAL фиксирует не сами SQL-запросы, а физические изменения — бинарные модификации хранилища.
В PostgreSQL используется push-модель распространения изменений. Это значит, что master сервер активно отправляет записи WAL на реплики, а те применяют их, внося изменения физически, согласно записанным в журнале данным. Если остановить все операции на master-сервере, дождаться синхронизации всех реплик и сделать бинарное сравнение master и slave серверов, они будут идентичны.
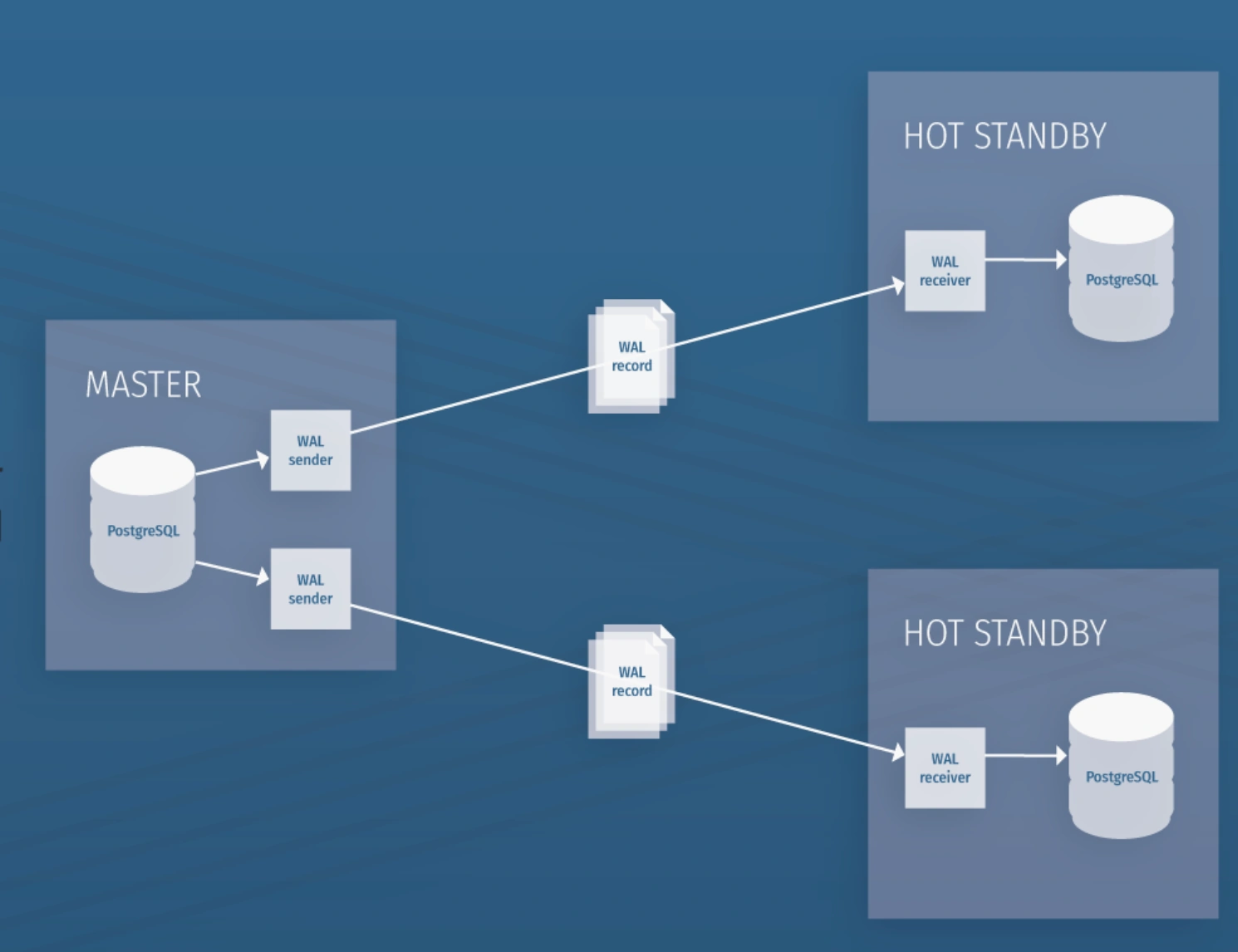
Когда требуется добавить новую реплику, обычно нужно приостановить работу приложения, чтобы база данных не менялась во время процесса подключения. Однако, если запись данных происходит не очень часто, новая реплика может догнать отставание, которое возникло за время подключения.
Производительность репликации в PostgreSQL в значительной степени зависит от производительности дисков. Это связано с тем, что операции записи в WAL и его распространение требуют активного взаимодействия с дисковым хранилищем. Поэтому для оптимизации рекомендуется выделить отдельный диск для WAL, особенно при использовании традиционных жёстких дисков (HDD), которые медленнее по сравнению с SSD.
Логическая репликация
Помимо физической репликации, PostgreSQL поддерживает логическую репликацию, которая позволяет более гибко управлять копированием данных. Логическая репликация позволяет реплицировать не всю базу данных целиком, а отдельные таблицы или схемы. Это особенно полезно для частичного копирования данных или интеграции с внешними системами, где требуется передача лишь определённых частей информации.
Полезные материалы:
Репликация в MySQL
Исторически в MySQL существует несколько типов журналов, что связано с её архитектурой. В MySQL есть два ключевых слоя:
- Логический слой, который отвечает за операции, не зависящие от физического хранилища данных, такие как выполнение запросов, построение планов выполнения, кэширование.
- Физический слой, который занимается непосредственным хранением данных. Этот слой может быть реализован разными механизмами (например, InnoDB, MyISAM и другие).
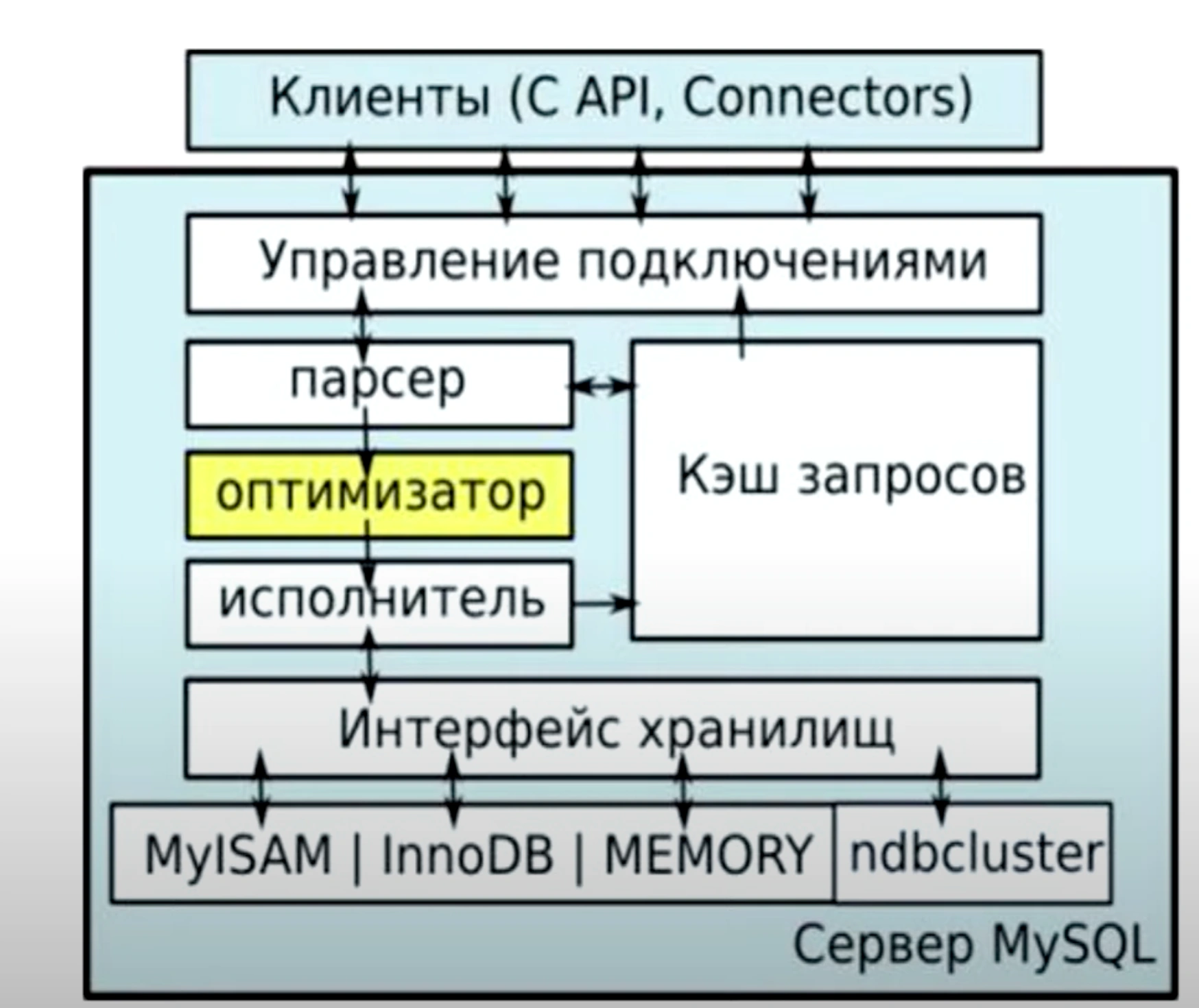
Для работы транзакций физический слой должен вести журнал, аналогичный Write-Ahead Log (WAL) в PostgreSQL. Теоретически его можно было бы использовать для репликации, но логический слой не имеет доступа к физическому слою напрямую. Поэтому для репликации в MySQL на логическом уровне создаётся отдельный журнал — Binary Log.
Механизм работы
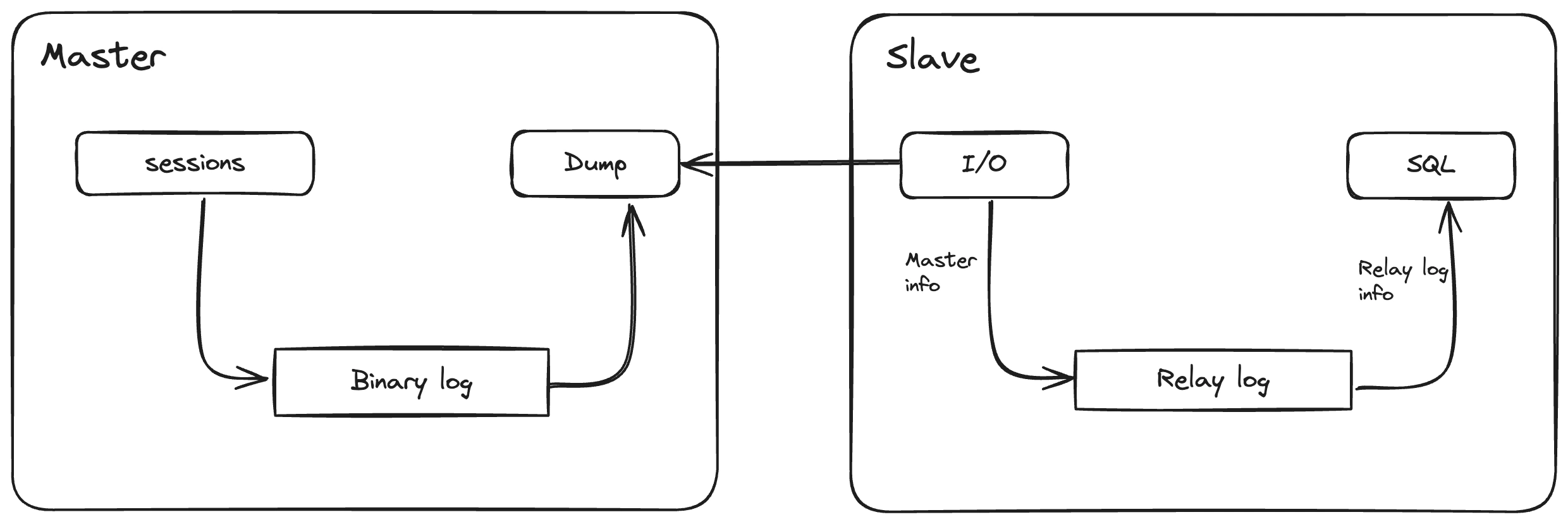
- Запись изменений в Binary Log: Все изменения данных, влияющие на состояние базы, записываются в бинарный лог на master-сервере.
- Передача бинарного лога на реплики: в MySQL применяется pull-модель. Это означает, что реплики сами забирают изменения с master-сервера. Для этого на master используется поток binlog dump, который отправляет данные, а на репликах — поток I/O, который принимает эти данные и записывает их.
- Применение изменений на репликах: После того как реплики получают бинарный лог, они применяют записанные в нём изменения к своим копиям данных.
Репликация в MySQL может работать по разным механизмам в зависимости от того, как фиксируются изменения в Binary Log. Существует несколько подходов к записи данных: на уровне SQL-запросов, на уровне изменённых строк или их комбинации. Каждый из этих методов имеет свои особенности, преимущества и ограничения, влияющие на производительность, точность репликации и объём передаваемых данных. Далее мы рассмотрим три основных формата репликации в MySQL.
Statement Based Replication (SBR)
Один из самых простых подходов к репликации — это запись в Binary Log непосредственно SQL-запросов. Такой формат называется Statement-Based Binary Log, а репликация на его основе — Statement Based Replication (SBR). В этой модели master сервер сохраняет в журнал сами SQL-запросы, а slave серверы получают этот список запросов и выполняют их у себя.
Плюсы:
- Экономия на передаче данных: В случае однотипных изменений объём передаваемых данных может быть минимальным. Например, если запрос изменяет 5 миллионов строк одним SQL-запросов, как в случае
UPDATE users SET bonus=bonus+100, в журнал записывается всего одна строка запроса. Это значительно экономит место по сравнению с тем, если бы приходилось передавать информацию о каждой строке отдельно. - Прозрачность и читаемость журнала: Все запросы в Binary Log сохраняются в привычном для разработчика виде SQL-запросов. Это упрощает анализ журнала — его можно прочитать и проанализировать без необходимости преобразования данных.
Проблемы:
- Недетерминированность выполнения: Один из основных минусов SBR заключается в том, что запросы выполняются на slave независимо от времени их исполнения на master. Это может стать проблемой для функций, которые зависят от текущего состояния системы, таких как
NOW(),RAND(),UUID(), или для вызовов пользовательских функций (UDF). Например, если на master запрос использовалNOW(), то на slave это уже будет другое время, что приведёт к несоответствиям данных между серверами. Проблемы могут возникать и с триггерами,AUTO_INCREMENTи другими конструкциями, зависящими от состояния сервера. Прочие проблемы описаны в документации. - Долгое выполнение сложных запросов. Если запрос на master-сервере выполнялся долго (например, 10 минут), то на slave он будет занимать столько же времени. Это может замедлить процесс репликации и привести к значительным задержкам в синхронизации данных между серверами.
Row Based Replication (RBR)
Второй формат репликации называется Row-Based Binary Log. В Binary Log записываются конкретные строки, которые были изменены запросами. Этот журнал включает две части: BEFORE image (состояние строки до изменения) и AFTER image (состояние строки после изменения).
RBR имеет три режима работы:
- full: При изменении строки сохраняются все её колонки (и до изменения, и после), даже если некоторые из них не были изменены. Это приводит к значительному увеличению объёма передаваемых данных и потребления памяти, но обеспечивает полный снимок изменений.
- noblob: Этот режим похож на full, но с исключением колонок типа BLOB и TEXT. Эти данные не передаются, что позволяет сэкономить ресурсы, если таблицы содержат большие двоичные или текстовые данные.
- minimal: В этом режиме сохраняются только те колонки, которые были изменены, а также ключевые поля, такие как Primary Key. Это самый экономичный режим с точки зрения памяти и пропускной способности.
Плюсы:
- Детерминированность: В RBR реплики получают уже готовые результаты изменений, а не исходные SQL-запросы. Это устраняет проблемы, связанные с недетерминированными функциями, такими как
NOW(),UUID(),RAND(), которые создавали сложности в Statement-Based Replication. Поскольку данные передаются в готовом виде, результат на slave всегда будет таким же, как на master.
Минусы:
- Бинарный формат: Данные в RBR записываются в бинарном виде. Это делает его менее удобным для ручного анализа. Однако для чтения такого журнала существует утилита
mysqlbinlog -v, которая позволяет вывести данные в человекочитаемом формате. - Большое потребление памяти: RBR потребляет больше памяти, чем SBR, так как нужно сохранять и передавать как исходные данные строки, так и изменения. Это особенно заметно в режиме full, где передаются все колонки строки, даже если некоторые из них не изменились.
Mixed binlog format
Mixed binlog format — это гибридный формат, который пытается объединить сильные стороны Statement-Based Replication (SBR) и Row-Based Replication (RBR). В зависимости от характера запроса и его детерминированности, MySQL автоматически выбирает подходящий формат репликации.
Принципы работы
- SBR используется для простых и детерминированных запросов, таких как
UPDATEилиINSERT, которые не зависят от текущего состояния данных и могут быть выполнены на slave точно так же, как и на master. - RBR применяется для сложных запросов или запросов, результаты которых могут быть недетерминированными. Это особенно важно при использовании функций, таких как
NOW(),RAND(), или при выполнении запросов, изменяющих большое количество строк. В таких случаях передача результатов в формате строк (RBR) помогает избежать несоответствий данных.
Плюсы
- Гибкость: Система автоматически выбирает между SBR и RBR в зависимости от типа запроса, что позволяет использовать преимущества обоих форматов.
- Оптимизация: В теории, такой подход позволяет оптимально использовать ресурсы системы.
Минусы
- Редкое использование: Несмотря на свои преимущества, этот формат используется довольно редко, так как не всегда работает корректно. Это может привести к неожиданным проблемам с репликацией, особенно в сложных сценариях.
- Сложность: Автоматическое переключение между форматами увеличивает сложность как настройки репликации, так и диагностики проблем.
Классификация репликаций по количеству точек записи
Репликация master-slave
Master-slave репликация — это классическая схема, в которой одна ведущая реплика (master) отвечает за все операции записи, а несколько ведомых реплик (slave) получают копии этих изменений и служат для чтения данных. В такой конфигурации операции записи выполняются исключительно на master-сервере, а реплики поддерживают актуальные данные для чтения.
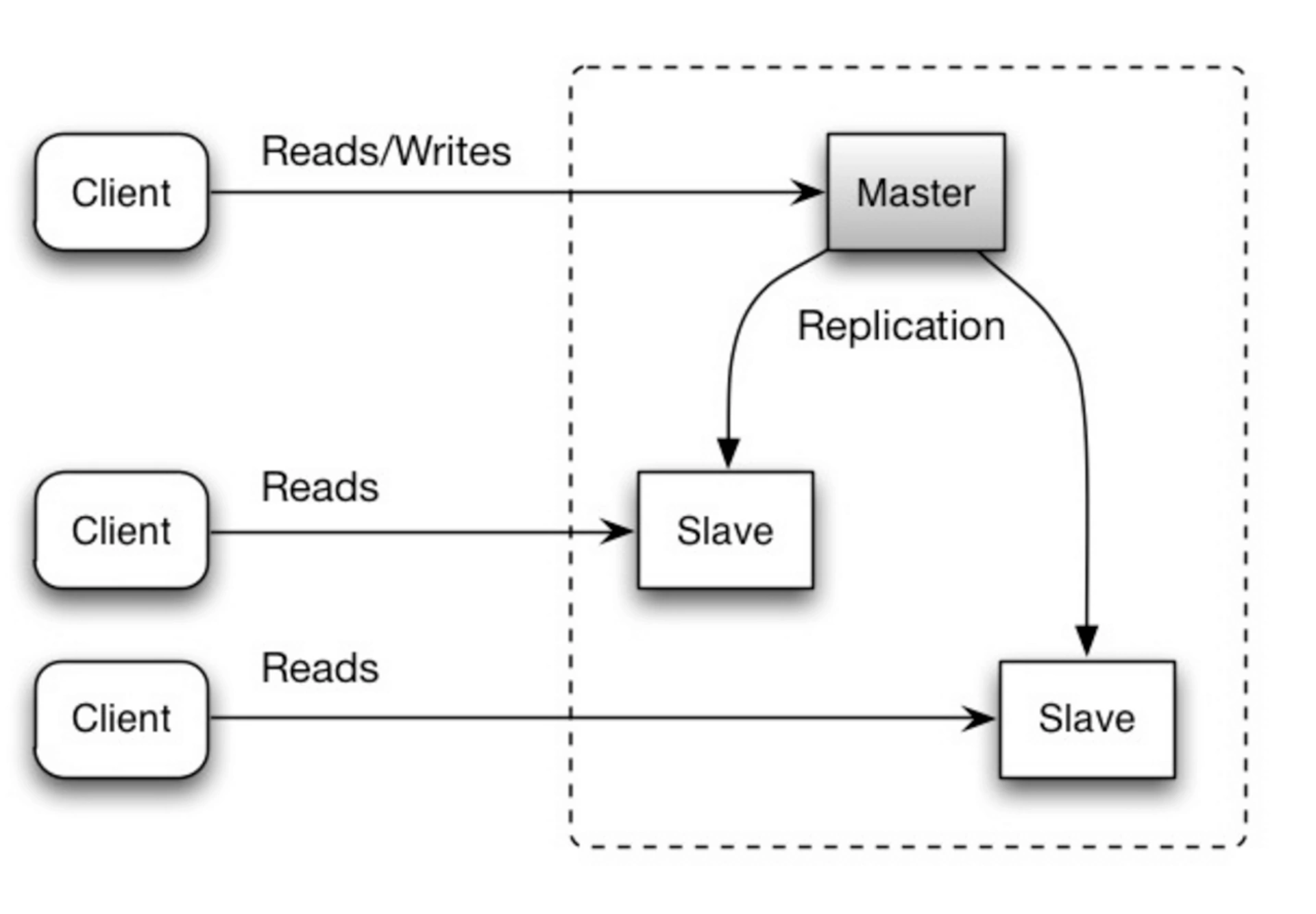
Этот подход является одним из самых распространённых, поскольку он относительно прост в настройке и понятен для администрирования.
Проблемы и недостатки:
- Мастер обязательно упадёт: Как бы надёжно ни был настроен master-сервер, со временем он всё равно может выйти из строя. В таком случае нужно будет вручную или автоматически выбрать одну из slave-реплик в качестве нового master. Этот процесс может занять время и привести к временному простою системы.
- Не ускоряет операции вставки данных: Все операции записи по-прежнему выполняются только на master, и его производительность может стать узким местом системы.
- Ограниченная доступность: Несмотря на отказоустойчивость системы, схема master-slave не способна обеспечить гарантированный уровень доступности 99,999% (High Availability). Основная причина в том, что даже при наличии нескольких slave-реплик система всё ещё зависит от одного master-сервера, и его сбои могут привести к значительным задержкам или простою.
Репликация master-master
В master-master репликации каждая реплика является ведущей (master), что означает, что на все серверы можно выполнять операции записи. Эти изменения синхронизируются между репликами, обеспечивая отказоустойчивость и распределённую обработку данных.
В этой схеме возможна комбинация с master-slave репликацией, когда ведущие реплики имеют дополнительные ведомые серверы, используемые только для чтения.
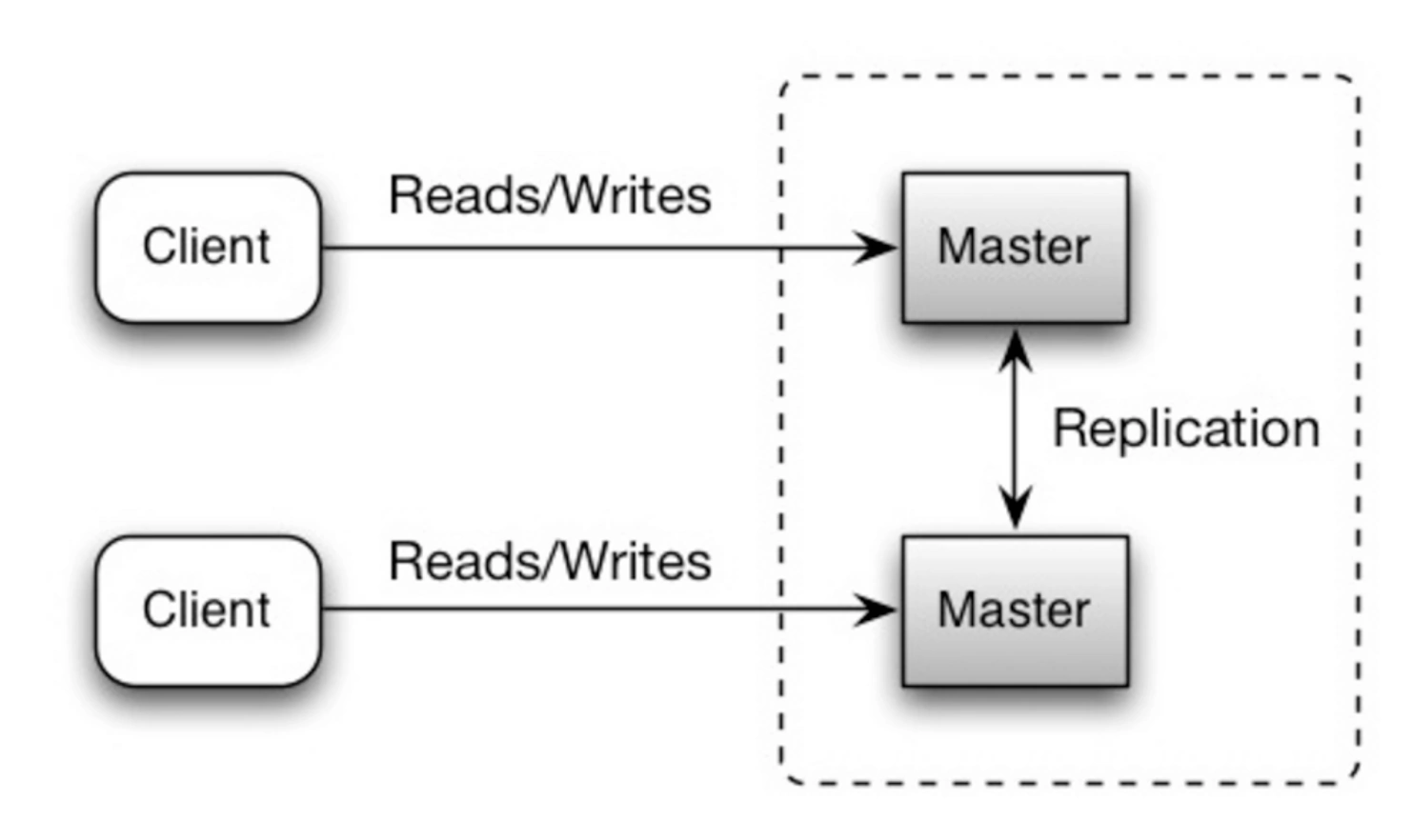
Плюсы
- Нет единой точки отказа: В такой схеме отсутствует один главный сервер, от которого зависят все записи. Это повышает отказоустойчивость системы, так как при выходе из строя одного master можно продолжать работу с другими репликами.
- Теоретически максимальная High Availability: Система может обеспечить высокий уровень доступности, так как несколько серверов одновременно могут принимать и обрабатывать запросы.
Минусы
- Проблемы с консистентностью: Основной недостаток этой схемы — возможность конфликтов. Если два разных master сервера одновременно изменяют один и тот же набор данных, могут возникнуть конфликты, которые сложно разрешить автоматически. Это требует дополнительных механизмов для управления конфликтами и сохранения целостности данных.
- Не масштабирует запись: Несмотря на возможность записи в несколько реплик, этот метод не масштабирует запись, так как данные всё равно должны синхронизироваться между всеми master-серверами. Это может привести к задержкам при интенсивных операциях записи.
Варианты применения
- Географическая распределенность. Один из лучших сценариев применения master-master репликации — это распределённые системы с центрами обработки данных (ЦОД) в разных странах. Пользователи работают с ближайшими к ним серверами, что уменьшает задержки и повышает производительность. В случае сбоя одного ЦОД система продолжает работу, так как данные доступны на других серверах.
- Hot-standby репликация. В этом сценарии второй master сервер находится в режиме ожидания. Он не используется в обычной работе, но всегда готов принять нагрузку, если основной master выйдет из строя.
- Offline клиенты. В системах, где клиенты могут временно потерять подключение к сети (например, мобильные приложения с нестабильным интернетом), master-master репликация позволяет асинхронно объединять данные, когда соединение восстанавливается. Примером такой базы данных является CouchDB, которая поддерживает асинхронную репликацию для offline клиентов.
Решение конфликтов
- Предотвращение конфликтов: Лучший способ справиться с конфликтами — организовать архитектуру приложения таким образом, чтобы они не возникали. Например, можно распределить данные между репликами так, чтобы разные master сервера обрабатывали разные наборы данных.
- Last write wins: В случае конфликта применяется правило, что «выигрывает последняя запись». Однако, определение порядка записей может быть сложным и может привести к потере данных.
- Ранг реплик: Приоритет отдаётся данным с реплики с более высоким рангом, например, старейшему master серверу.
- Решение на клиенте: Конфликты можно разрешать на уровне клиента, когда приложение принимает решение о том, какие данные сохранять.
- Conflict-free replicated data types (CRDT): CRDT — это структуры данных, которые автоматически синхронизируются между репликами без риска конфликтов. Это сложный, но эффективный способ управления конфликтами в распределённых системах.
- Слияние: Автоматическое объединение конфликтных данных. Например, при слиянии двух версий одного документа может быть создана новая версия, содержащая элементы обеих исходных версий.
Безмастерная репликация
Безмастерная репликация — это метод репликации, при котором отсутствует главный master. Все узлы системы являются равноправными, и клиентские приложения могут записывать данные на любой из них. Запросы на запись отправляются сразу на все реплики, но применяются только на тех, которые доступны в данный момент.
Для успешного завершения операции записи требуется подтверждение от определённого количества узлов, обозначенного как W. Если количество успешных записей превышает значение W, операция считается завершённой успешно. В случае, если подтверждений меньше, но не 0, откат транзакции не производится.
Клиентские приложения также читают данные с любых доступных реплик. Для успешного выполнения операции чтения необходимо получить подтверждение от определённого количества узлов, обозначенного как R. Если количество ответивших реплик превышает значение R, операция считается успешной.
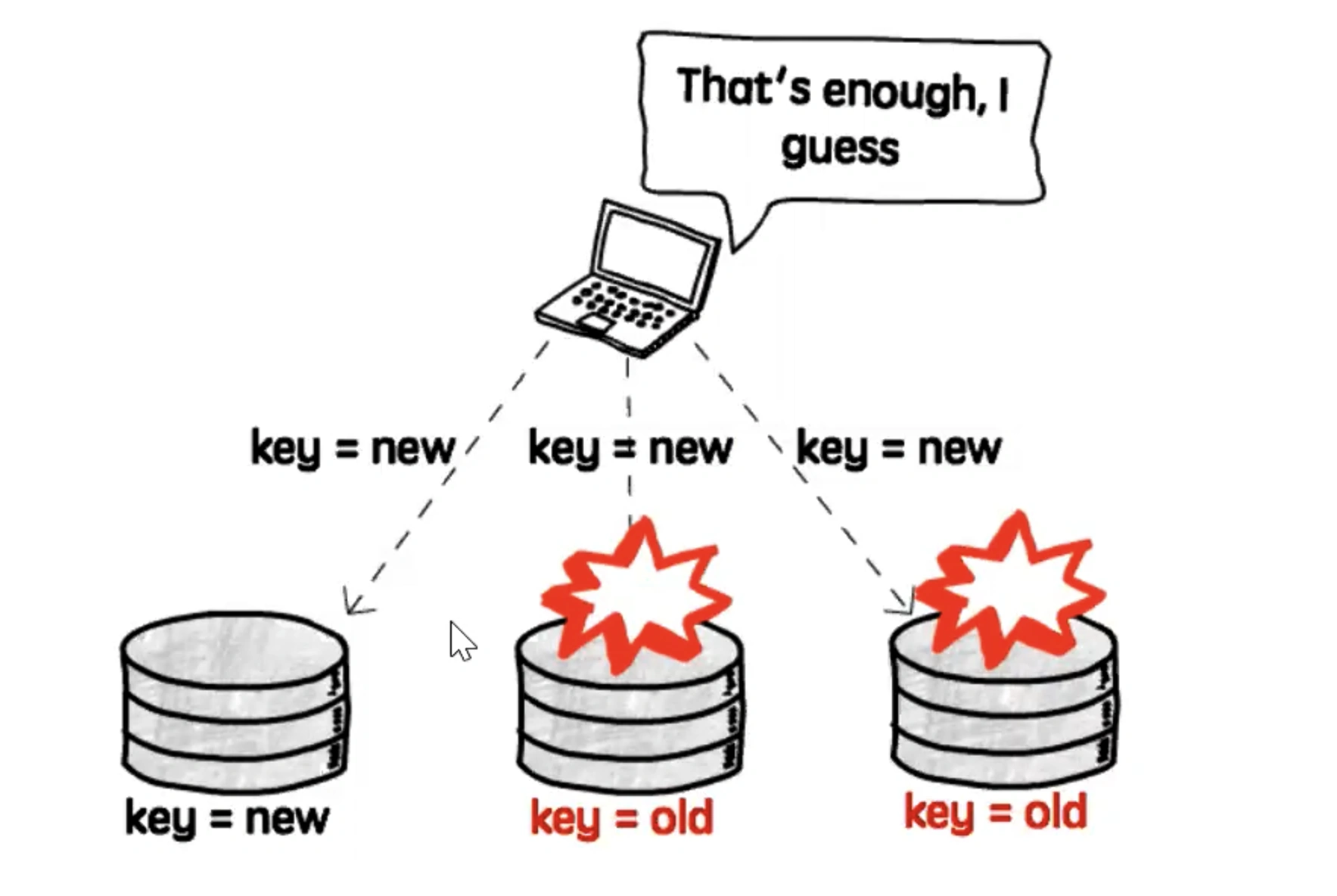
Преимущества:
- Высокая доступность: Поскольку все узлы равноправны, система не имеет единой точки отказа. Даже если несколько узлов выйдут из строя, остальные продолжают обслуживать запросы.
- Горизонтальное масштабирование: Безмастерная репликация легко масштабируется. Новые узлы можно добавлять без необходимости изменять основную архитектуру системы.
- Гибкость конфигурации: Система позволяет настраивать различные уровни консистентности и доступности, исходя из требований приложений. Можно выбирать между высокой доступностью или строгой консистентностью данных, в зависимости от приоритетов системы.
Недостатки:
- Проблемы с консистентностью данных: Из-за того, что запись данных может происходить на нескольких узлах одновременно, существует риск возникновения конфликтов и несогласованности данных. Для разрешения таких конфликтов применяются различные методы, такие как Last Write Wins или версионирование данных.
- Сложность управления: Управление системой без master-узла требует сложных механизмов синхронизации и разрешения конфликтов. Это может усложнять её настройку и сопровождение, так как необходимо следить за синхронизацией данных между множеством узлов.
- Проблемы с откатом транзакций: В безмастерной репликации отсутствует полноценный механизм отката транзакций. Это может усложнить управление ошибками и восстановление данных в случае сбоев, особенно если не все узлы подтвердили успешную запись.
Для обеспечения согласованности данных в безмастерных системах могут использоваться следующие механизмы:
- Периодическая синхронизация реплик: Реплики могут периодически синхронизироваться друг с другом, чтобы устранить расхождения в данных.
- Обновление клиентом: Внешний клиент может опрашивать все узлы, находить устаревшие данные и инициировать их обновление для достижения консистентности.
- Обновление при чтении (Set on read): При чтении данных система получает последнюю версию, после чего обновляет устаревшие данные на остальных репликах.
Безмастерная репликация широко используется в распределённых системах и NoSQL базах данных, таких как Amazon DynamoDB, Apache Cassandra и Riak.
Классификация по типу синхронизации реплик
Синхронная репликация
Синхронная репликация — это метод репликации, при котором master-сервер, получив запрос от клиента, ожидает, пока все реплики получат и применят изменения. Только после этого master сообщает клиенту, что запрос успешно выполнен. Такой подход обеспечивает высокую надёжность данных, так как изменения одновременно фиксируются на всех репликах.
Механизм работы
- Подготовка транзакции в движке БД: Транзакция начинается на master-сервере, где собираются все изменения данных. Это подготовительный этап перед записью в журнал транзакций.
- Запись транзакции в лог: Все изменения записываются в журнал транзакций, что гарантирует возможность восстановления данных в случае сбоя системы.
- Пересылка лога репликам: Записанные транзакции отправляются на все реплики для синхронного применения. Этот шаг обеспечивает, что реплики всегда получают данные в том же порядке, что и master.
- Выполнение транзакций на репликах: Реплики применяют полученные изменения к своим копиям данных, синхронизируясь с master-сервером.
- Завершение транзакции в движке БД: После успешного применения всех изменений на всех репликах транзакция завершается на master-сервере.
- Возврат результата клиенту: Клиент получает подтверждение только после того, как изменения успешно применены на всех репликах, что гарантирует консистентность данных во всей системе.
Преимущества
- Высокая надежность данных: Все реплики получают и применяют изменения одновременно, что предотвращает потерю данных даже в случае сбоя одного из серверов.
- Консистентность данных: Данный метод обеспечивает строгую консистентность между master и всеми репликами. Все узлы имеют одинаковые данные, что исключает возможность получения разных результатов для одного и того же запроса.
Недостатки
- Увеличенное время отклика: Поскольку подтверждение возвращается клиенту только после завершения транзакции на всех репликах, время отклика системы увеличивается. Это может негативно сказываться на производительности, особенно при большом количестве реплик.
- Высокая вероятность сбоев: Чем больше реплик в системе, тем выше вероятность того, что хотя бы одна реплика не ответит вовремя. Если хотя бы одна реплика недоступна или не завершила операцию, вся транзакция будет отклонена или задержана.
Примеры использования
Синхронная репликация применяется в системах, где критична консистентность и надёжность данных. Она используется в банковских системах, финансовых приложениях или других сценариях, где необходимо гарантировать целостность и точность выполнения операций, даже если это снижает общую производительность.
Асинхронная репликация
Асинхронная репликация — это метод репликации, при котором изменения сначала записываются на master-сервер, а затем с некоторой задержкой пересылаются на slave-реплики. В отличие от синхронной репликации, подтверждение транзакции возвращается клиенту до того, как изменения применены на всех репликах. Это повышает производительность, но может привести к временной несогласованности данных.
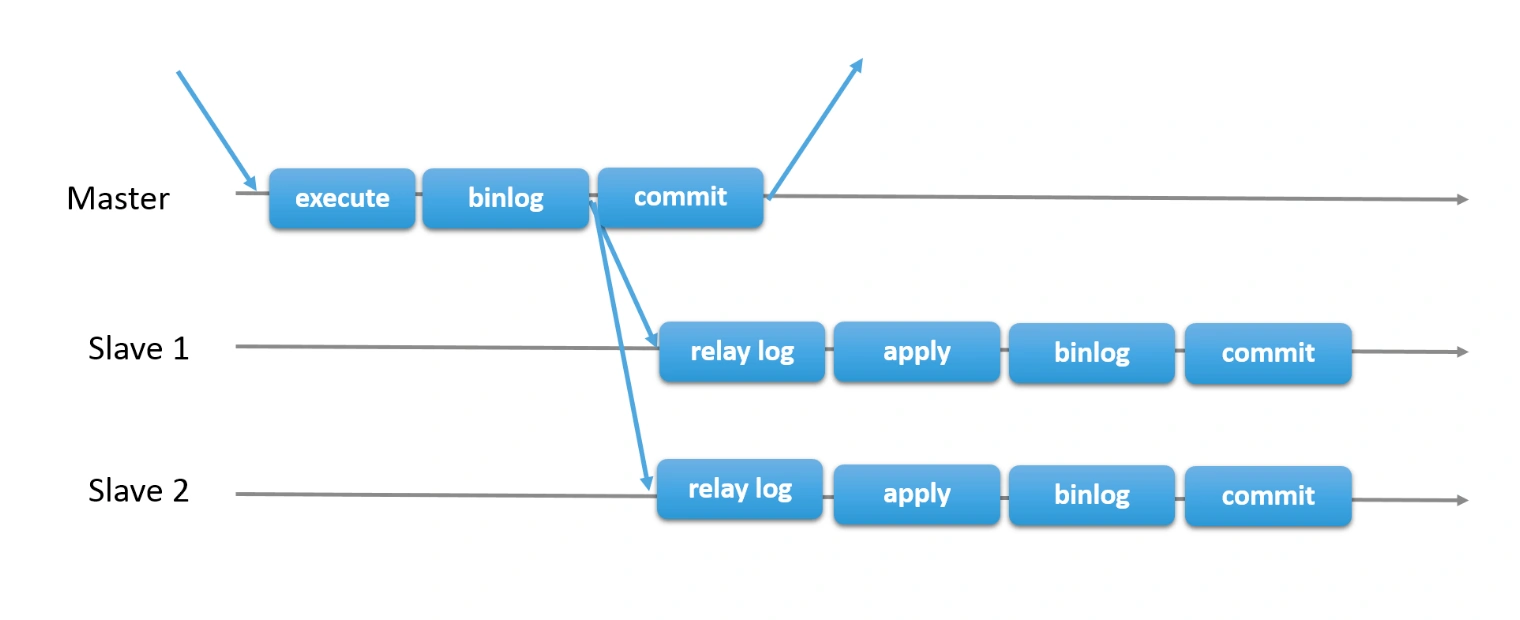
Механизм работы
- Подготовка транзакции в движке БД: Транзакция начинается на master-сервере, где собираются все изменения данных.
- Запись транзакции в лог: Все изменения записываются в журнал транзакций.
- Завершение транзакции в движке БД: Транзакция считается завершённой на master, даже если реплики ещё не получили обновления.
- Возврат результата клиенту: Клиент получает подтверждение о завершении транзакции сразу после её завершения на master, что ускоряет отклик системы.
- Пересылка лога репликам: Журнал транзакций отправляется на реплики для асинхронного применения изменений. Это может происходить с небольшой задержкой, в зависимости от настроек системы.
- Воспроизведение транзакции на репликах: Реплики получают журнал и применяют изменения к своим копиям данных, но с задержкой относительно master-сервера. Это позволяет использовать реплики для операций чтения и отчётности, даже если данные не полностью синхронизированы.
Преимущества
- Высокая производительность: Поскольку клиент получает подтверждение транзакции до её применения на репликах, система быстрее реагирует на запросы. Это особенно полезно для систем с высокой нагрузкой на запись.
- Уменьшенная нагрузка на сеть: Пересылка данных на реплики происходит асинхронно, что снижает сетевую нагрузку. Реплики могут получать данные с задержкой, не влияя на производительность основного сервера.
- Гибкость в использовании: Реплики можно использовать для различных задач, таких как выполнение отчётов, аналитики или резервного копирования, не замедляя работу master-сервера. Это позволяет разгрузить master и распределить задачи по разным узлам.
Недостатки
- Потеря данных при сбое: Если master выйдет из строя до того, как данные будут пересланы на реплики, изменения могут быть потеряны. Это может привести к несоответствию данных между master и репликами и потребовать восстановления системы.
- Отставание реплик: Поскольку реплики получают обновления с задержкой, их данные могут отставать от актуального состояния на master-сервере. Это затрудняет выполнение операций, которые требуют точных и актуальных данных в реальном времени.
- Проблемы с консистентностью данных: Из-за разной степени отставания реплик данные могут быть несогласованными между ними. Это может привести к тому, что пользователи будут получать разные результаты для одного и того же запроса в зависимости от того, к какой реплике они обращаются.
Примеры использования
Асинхронная репликация широко применяется в системах, где приоритет отдается высокой производительности и быстрому времени отклика, а полная консистентность данных не критична. Например, она часто используется в системах аналитики и отчётности, где небольшая задержка в обновлении данных допустима. Реплики могут обрабатывать сложные запросы и отчёты, разгружая основной master-сервер и минимизируя его нагрузку.
Полу-синхронная репликация
Полу-синхронная репликация — это компромиссный метод между синхронной и асинхронной репликацией. Он обеспечивает более высокую надёжность данных по сравнению с асинхронной репликацией, при этом сокращая время отклика системы по сравнению с синхронной.
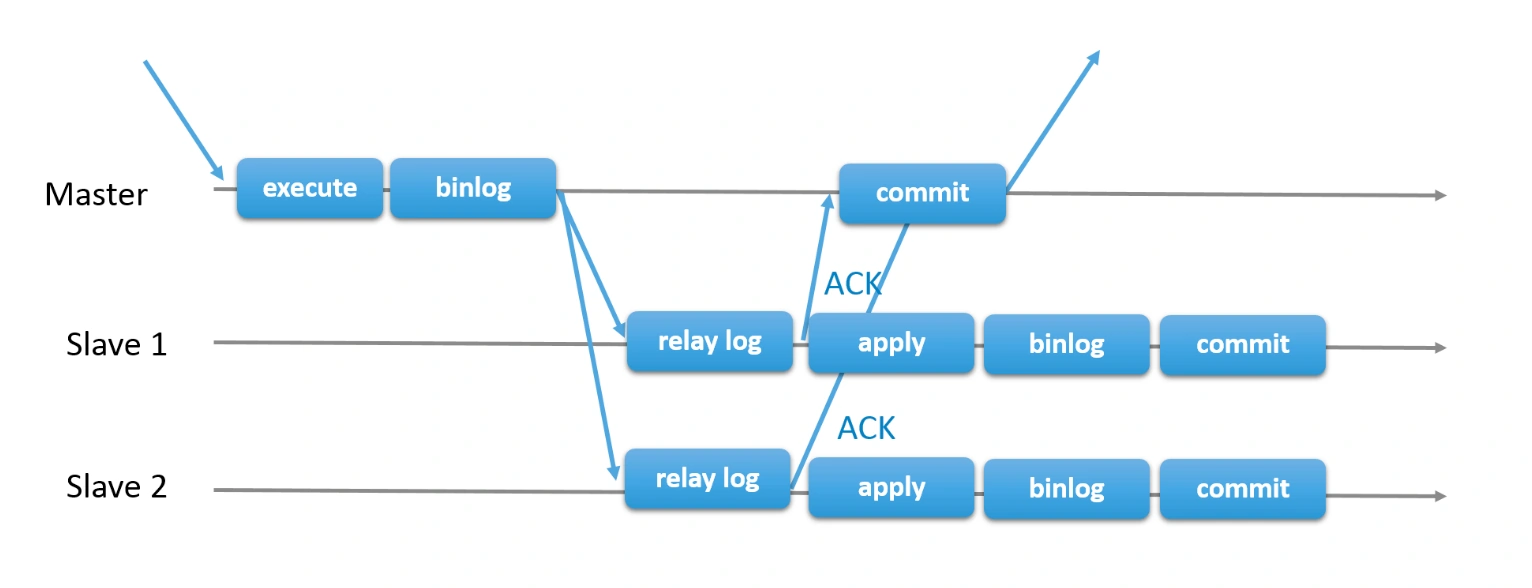
Механизм работы
- Подготовка транзакции в движке БД: Транзакция начинается на master-сервере, где собираются все изменения данных.
- Запись транзакции в лог: Все изменения записываются в журнал транзакций.
- Пересылка лога репликам: Журнал транзакций отправляется на все доступные реплики. Однако master ожидает подтверждения получения журнала только от одной или нескольких реплик, но не обязательно их применения.
- Завершение транзакции в движке БД: После получения подтверждения от одной или нескольких реплик транзакция завершается на master-сервере, и клиент получает уведомление об успешном завершении операции.
- Воспроизведение транзакции на репликах: Реплики применяют полученные изменения к своим копиям данных, но это может произойти с задержкой, в зависимости от загрузки системы и настроек репликации.
Преимущества
- Баланс между надежностью и производительностью: Полу-синхронная репликация обеспечивает более высокую надёжность данных по сравнению с асинхронной репликацией, так как master ждёт подтверждения хотя бы от одной реплики. Это снижает риск потери данных при сбое.
- Сниженное время отклика: В отличие от синхронной репликации, master не дожидается подтверждения от всех реплик, что сокращает время отклика системы и повышает её производительность.
- Меньшая вероятность отставания данных: Поскольку master ожидает подтверждения перед завершением транзакции, вероятность значительного отставания данных на репликах снижается, что делает их более актуальными.
Недостатки
- Проблемы с консистентностью данных: Хотя master ожидает подтверждения от одной или нескольких реплик, другие реплики могут отставать и не иметь актуальных данных, что приводит к временному несоответствию данных между узлами.
- Сложность управления: Полу-синхронная репликация требует более сложной настройки и мониторинга по сравнению с асинхронной, так как необходимо отслеживать подтверждения от реплик и управлять задержками в применении данных.
- Увеличенное время отклика по сравнению с асинхронной репликацией: Полу-синхронная репликация хоть и быстрее синхронной, всё же медленнее асинхронной, так как требует ожидания подтверждений от реплик перед завершением транзакции.
Примеры использования
Полу-синхронная репликация часто используется в системах, где требуется компромисс между надёжностью данных и производительностью. Например, она популярна в финансовых системах, где необходимо обеспечить высокую доступность и консистентность данных, но при этом важно минимизировать время отклика для обеспечения комфортной работы клиентов.
Частые проблемы репликации
Отставание реплики
Отставание реплики (или лаг репликации) возникает, когда изменения, внесённые на master-сервере, не успевают вовремя применяться на репликах. Это может привести к несогласованности данных между master и репликами, что особенно затрудняет выполнение операций, требующих актуальных данных. В нормальных условиях отставание реплики обычно не превышает 1 секунды, но при высоких нагрузках оно может значительно увеличиваться.
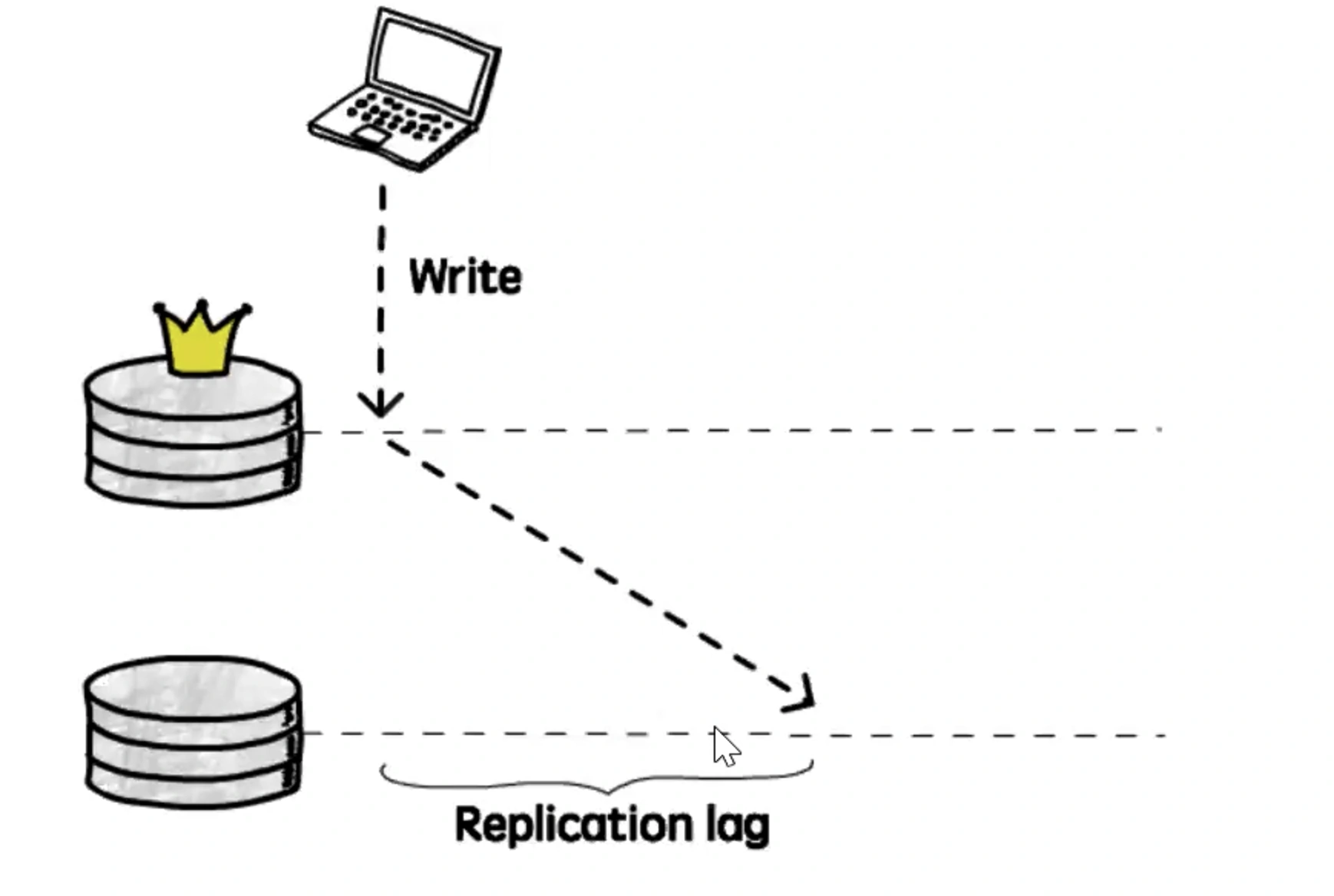
Особенно заметна разница между различными СУБД: в PostgreSQL передаются не сами запросы, а блоки данных через Write-Ahead Log (WAL), что теоретически снижает отставание по сравнению с MySQL, где могут использоваться другие методы передачи изменений.
Причины отставания реплики
- Медленные и сложные запросы: Если реплики выполняют ресурсоёмкие или сложные запросы, это может замедлить процесс применения изменений.
- Сетевые проблемы: Задержки в сети могут замедлить передачу журнала транзакций от master к репликам, увеличивая лаг репликации.
- Размер журнала транзакций: Большие объёмы изменений могут перегружать систему репликации. Чем больше данных нужно передать, тем больше времени занимает их обработка и синхронизация.
- Проблемы с дисковой подсистемой: Медленные дисковые операции на репликах могут замедлить процесс записи и применения изменений. Это особенно важно в системах, где используется устаревшее оборудование или недостаточно производительные диски.
Методы устранения отставания реплики
- Оптимизация запросов: Оптимизация сложных запросов на репликах может снизить нагрузку и ускорить процесс применения изменений. Это включает улучшение индексации, оптимизацию SQL-запросов. В некоторых случаях можно прибивать медленные запросы, которые висят дольше 10 секунд.
- Настройка параметров репликации: Оптимизация параметров репликации, таких как размер и частота отправки WAL, может помочь уменьшить отставание. Например, в PostgreSQL можно настроить параметры
wal_levelиmax_wal_sendersдля оптимизации процесса репликации и уменьшения задержек. - Мониторинг и диагностика: Регулярный мониторинг состояния репликации помогает выявить и устранить проблемы на ранних этапах. В MySQL для этого можно использовать Performance Schema, а в PostgreSQL — встроенные инструменты мониторинга и сторонние утилиты.
- Использование выделенных реплик для отчетности: В системах с высокой нагрузкой можно выделить отдельные реплики для выполнения отчётов и аналитических операций. Это разгружает основные реплики, позволяя им сосредоточиться на синхронизации данных с master.
Отставание реплики — это одна из самых распространённых проблем в системах репликации, но её можно эффективно устранить при правильной настройке и оптимизации системы.
Монотонное чтение
Монотонное чтение — это проблема, возникающая при репликации данных, когда пользователи получают несогласованные результаты при выполнении последовательных запросов. Это случается, когда изменения, внесённые на master-сервере, не успевают синхронизироваться с репликами, и разные запросы одного и того же пользователя могут попадать на реплики с различными состояниями данных.
Рассмотрим ситуацию, когда пользователь запрашивает список комментариев к статье. Если новый комментарий был добавлен и записан на мастер, но ещё не успел синхронизироваться со всеми репликами, пользователь может столкнуться с несогласованными результатами:
- Пользователь делает первый запрос и получает список комментариев, где нет нового комментария, так как изменения ещё не были синхронизированы с репликой.
- Пользователь делает второй запрос и видит список с новым комментарием.
- Однако при следующем запросе пользователь может снова не увидеть новый комментарий, если его запрос попадает на другую реплику, которая ещё не получила изменения.
Методы решения проблемы монотонного чтения
- Привязка пользователя к конкретной реплике (stickiness): Один из эффективных способов решения проблемы — привязать пользователя к конкретной реплике для всех последовательных запросов. Это можно реализовать с помощью сессий или токенов, чтобы пользователь всегда обращался к одной и той же реплике, пока она доступна. Это обеспечит консистентность данных для одного пользователя.
- Настройка задержек при чтении: Можно внедрить искусственные задержки перед тем, как разрешить чтение данных с реплик. Это даст репликам время для синхронизации с master-сервером. Задержка может быть настроена так, чтобы реплики всегда отставали от master на фиксированное время, достаточное для того, чтобы данные успели синхронизироваться.
- Использование кворумных чтений: В системах с безмастерной репликацией можно применять кворумные чтения, когда запрос обрабатывается одновременно несколькими репликами. Результат считается успешным только в том случае, если он подтверждён большинством реплик (кворумом). Это повышает вероятность получения более актуальных данных, так как система учитывает состояние нескольких реплик.
Согласованное префиксное чтение
Согласованное префиксное чтение — это ситуация, которая возникает при наличии нескольких master-серверов (например, в конфигурациях с master-master репликацией или групповой репликацией) или в системах с шардированием БД. Проблема заключается в том, что при распределённой обработке данных пользователь может получить сообщения или данные в неправильном порядке, нарушая логическую последовательность событий.
Представим чат с двумя участниками и одним сторонним наблюдателем:
- Первый пользователь отправляет сообщение в чат.
- Второй пользователь отправляет своё сообщение в чат.
- Наблюдатель читает сообщения с одной из реплик, но реплика получила данные в неправильном порядке — сначала сообщение второго пользователя, затем первого. В итоге наблюдатель видит перепутанную хронологию сообщений.
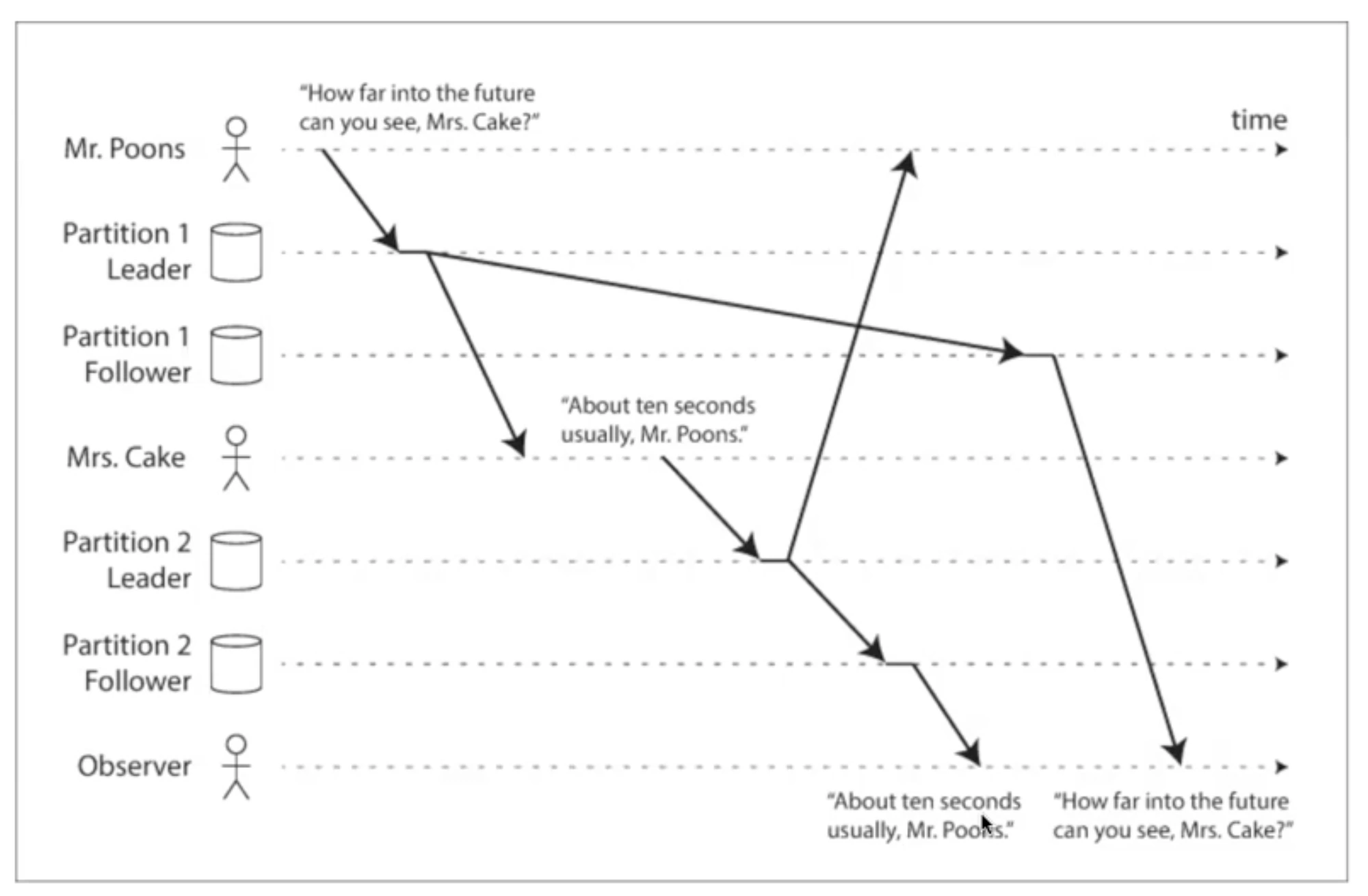
Эта проблема возникает из-за того, что изменения могут распространяться на разные реплики или шарды с небольшой задержкой, а синхронизация не всегда гарантирует правильную последовательность данных.
Возможные решения
- Сортировка по монотонному полю: Одним из простейших решений является использование поля, которое отслеживает порядок операций, например, временной метки или монотонного счётчика. Все сообщения сортируются по этому полю, что гарантирует, что данные будут отображаться в правильной последовательности.
Сравнение с другими методами
Помимо репликации, существуют и другие методы обеспечения отказоустойчивости и масштабирования баз данных. Среди наиболее популярных — шардирование и кластеризация. Эти методы могут работать самостоятельно или в сочетании с репликацией, обеспечивая различные уровни производительности и доступности.
- Шардирование: это процесс разделения базы данных на отдельные части, называемые шарды, которые могут быть распределены по разным серверам. Каждый шард хранит уникальный набор данных, и запросы на чтение и запись распределяются по этим шардам. Шардирование позволяет масштабировать запись, так как операции распределяются между разными серверами, но оно увеличивает сложность управления данными и требует дополнительной логики для маршрутизации запросов.
- Кластеризация: Это объединение нескольких серверов в один кластер, где они работают совместно для распределения нагрузки и обеспечения высокой доступности. Все сервера в кластере работают как единое целое, что позволяет системе продолжать работу даже при сбое одного из узлов.
Резюмирую
Репликация баз данных — это один из самых эффективных методов для обеспечения высокой доступности и масштабируемости современных систем. Она позволяет создавать копии данных на нескольких серверах, обеспечивая устойчивость к сбоям, равномерное распределение нагрузки и отказоустойчивость. В сочетании с шардированием и кластеризацией репликация становится мощным инструментом для построения надёжной и производительной инфраструктуры.
Однако важно учитывать возможные сложности, такие как задержки синхронизации или конфликты данных, и выбирать правильную стратегию репликации в зависимости от конкретных требований системы.
