Java Collection Framework (JCF) представляет собой набор классов и интерфейсов, предназначенных для хранения и обработки данных в оперативной памяти. JCF предоставляет удобные абстракции для работы с коллекциями объектов, что позволяет эффективно решать различные задачи в программировании.
JCF включает несколько ключевых интерфейсов, таких как Collection, List, Set, Queue, Deque и Map. Каждый из этих интерфейсов имеет свои особенности и способы работы с данными. Например, интерфейс List используется для работы с упорядоченными коллекциями, Set – для хранения уникальных элементов, а Map – для пар ключ-значение.
🌳 Иерархия интерфейсов JCF
Для эффективного использования JCF важно понимать его иерархию интерфейсов и классов. Это знание поможет вам выбирать наиболее подходящий тип коллекции для конкретных задач.
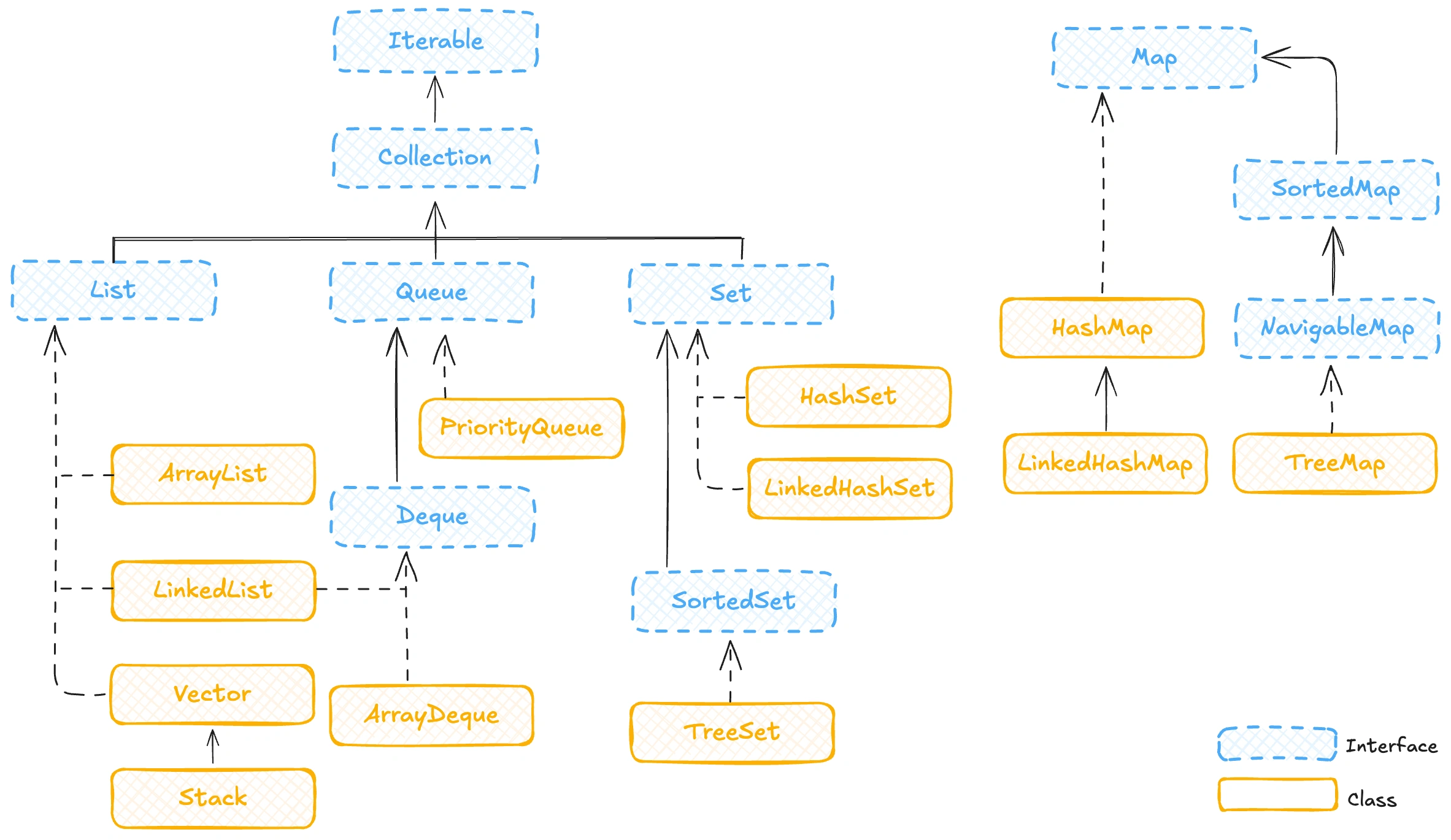
Корневым интерфейсом в JCF является Iterable, который позволяет перебирать элементы коллекции.
От Iterable наследуется интерфейс Collection, который служит основой для большинства других коллекций. Он предоставляет базовые методы, такие как add(), remove(), contains(), size() и другие.
Интерфейс Collection делится на три основных подинтерфейса: List, Set и Queue.
Listпредставляет упорядоченную коллекцию, которая может содержать дубликаты. Реализациями этого интерфейса являются классыArrayListиLinkedList.Set– коллекция, которая не содержит дубликатов. Примеры реализации:HashSet,LinkedHashSet,TreeSet.Queueиспользуется для хранения элементов в порядке их обработки. Примеры реализации:PriorityQueue,LinkedList.
Интерфейс Deque расширяет возможности Queue, позволяя добавлять и удалять элементы с обоих концов очереди.
Ещё один важный интерфейс – Map. Хотя он не является наследником Collection, он является неотъемлемой частью JCF. Map хранит данные в виде пар ключ-значение, причём ключи должны быть уникальными. Примеры реализации: HashMap, TreeMap, LinkedHashMap.
Интерфейс Iterable и Iterator
Iterable – это базовый интерфейс для всех коллекций в Java. Он предоставляет метод iterator(), который возвращает объект типа Iterator, необходимый для перебора элементов коллекции.
Интерфейс Iterator предоставляет три ключевых метода для работы с элементами:
E next()– возвращает следующий элемент коллекции.boolean hasNext()– возвращает true, если в коллекции есть следующий элемент.void remove()– удаляет текущий элемент коллекции.
Эти интерфейсы позволяют коллекциям быть целевыми для использования в цикле “for-each”, что упрощает итерацию по элементам.
final List<String> names = List.of("mark", "mike", "kate");
for (String name : names) { // цикл for-each
System.out.println(name);
}Если открыть байт-код этого примера, то можно увидеть, что именно Iterator используется в процессе выполнения цикла “for-each”.
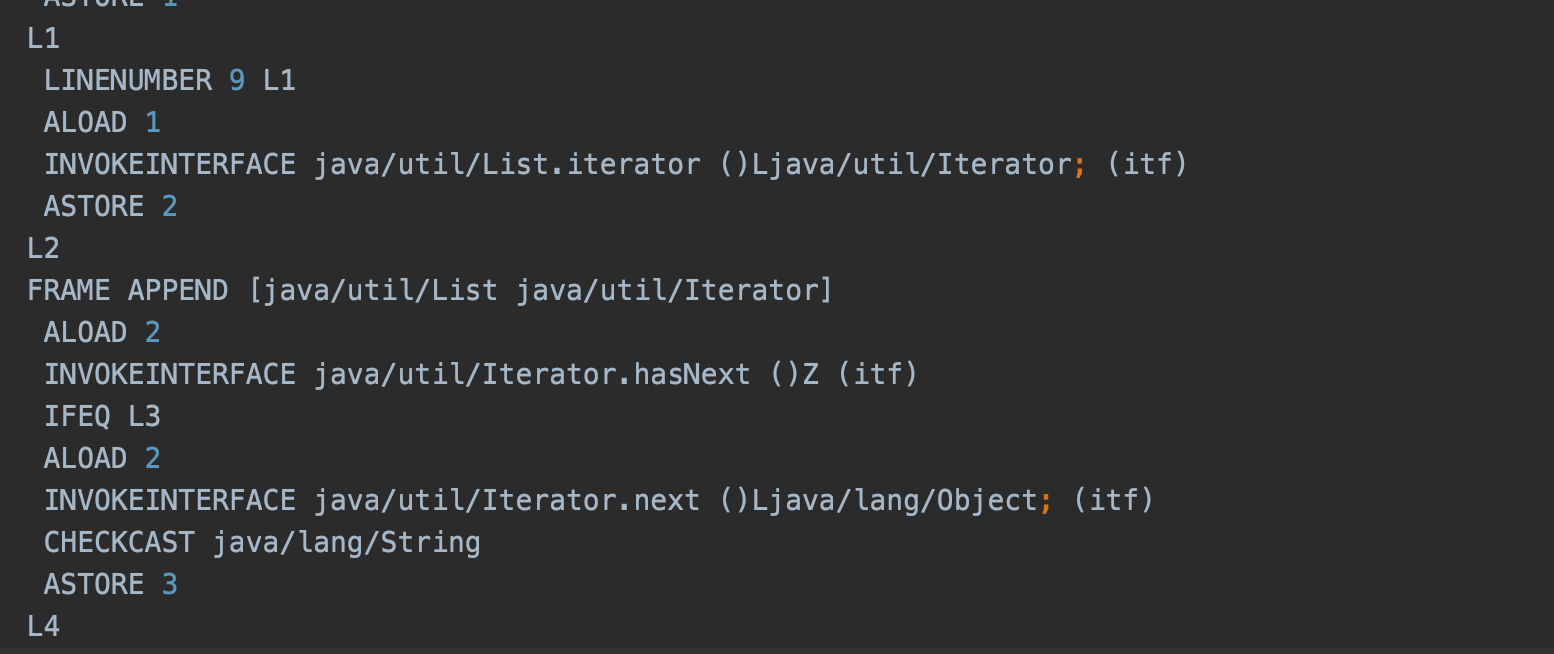
Даже без глубокого знания байт-кода легко распознать вызов метода iterator(), который возвращает объект Iterator.
Исключение ConcurrentModificationException
Исключение ConcurrentModificationException возникает, когда структура коллекции изменяется во время её итерации. Это может произойти, если коллекция модифицируется через другой поток или даже в том же потоке.
Рассмотрим пример, когда может возникнуть ConcurrentModificationException:
List<String> list = new ArrayList<>();
list.add("Java");
list.add("Python");
for (String item : list) {
if (item.equals("Python")) {
list.remove(item); // Это вызовет ConcurrentModificationException
}
}Причина возникновения ConcurrentModificationException
В этом примере исключение возникает, потому что во время итерации по списку он изменяется напрямую с помощью метода remove(). Однако проблема не в самом методе remove(), а в том, что итерация по коллекции выполняется через скрытый вызов Iterator в цикле for-each.
Хотя for-each выглядит как упрощённый способ обхода коллекции, на самом деле компилятор преобразует его в цикл с использованием итератора. Рассмотрим это на примере компилированного байткода:
ALOAD 1
INVOKEINTERFACE java/util/List.iterator ()Ljava/util/Iterator; (itf)
ASTORE 2
ALOAD 2
INVOKEINTERFACE java/util/Iterator.hasNext ()Z (itf)
IFEQ L5
ALOAD 2
INVOKEINTERFACE java/util/Iterator.next ()Ljava/lang/Object; (itf)
CHECKCAST java/lang/String
ASTORE 3В процессе работы for-each на основе Iterator происходит проверка на наличие изменений в коллекции, выполненных вне итератора. В нашем примере, для получения следующего элемента вызывается метод ArrayList.Itr#next(), который в свою очередь вызывает метод ArrayList.Itr#checkForComodification(). Посмотрим на его реализацию:
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}modCount— это счётчик изменений коллекции, увеличивающийся при каждом добавлении или удалении элементов.expectedModCount— это ожидаемое значение modCount, сохранённое итератором на момент его создания.
Когда коллекция модифицируется напрямую через метод remove(), значение modCount изменяется, но expectedModCount остаётся прежним. В результате при следующем вызове next() возникает несоответствие этих значений, что приводит к выбросу ConcurrentModificationException.
Как решить проблему?
Чтобы безопасно удалять элементы из коллекции во время её обхода, необходимо использовать метод remove() итератора, который позволяет корректно модифицировать коллекцию без нарушения её структуры. Это позволяет синхронизировать внутренний счётчик изменений с итератором.
Рассмотрим пример, в котором создаётся список имён, и мы удаляем все элементы с именем “mike” с помощью итератора:
final List<String> names = new ArrayList<>(List.of("mark", "mike", "kate"));
final Iterator<String> iterator = names.iterator();
while (iterator.hasNext()) {
final String name = iterator.next();
if ("mike".equals(name)) {
iterator.remove();
}
}
System.out.println(names); // [mark, kate]В этом примере удаление элемента происходит через вызов iterator.remove(), что предотвращает ConcurrentModificationException. Метод remove() итератора корректно обновляет внутренние счётчики modCount и expectedModCount, синхронизируя их между собой.
Исключительная ситуация
Рассмотрим следующий код, который на первый взгляд кажется похожим на ситуацию, когда может возникнуть ConcurrentModificationException:
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("a", "a");
for (String key : map.keySet()) {
map.remove(key);
}
}
}Этот код отработает без исключения, несмотря на то, что мы удаляем элементы во время итерации по ключам. В данном случае map содержит всего один элемент. Цикл for-each инициализирует итератор и сразу же получает единственный элемент “a”. Когда мы вызываем map.remove(key), элемент “a” удаляется, и keySet становится пустым.
Исключение ConcurrentModificationException выбрасывается при следующем вызове метода next() итератора. Однако в данном примере, после удаления элемента, цикл завершает свою работу, так как других элементов в коллекции больше нет. Итератор не вызывает next() второй раз, и проверка на модификации не выполняется.
Если бы в map изначально содержалось больше одного элемента, то после удаления первого элемента при попытке итератора получить следующий, возникло бы исключение ConcurrentModificationException.
Интерфейс Collection<T>
Интерфейс Collection расширяет Iterable и является основой для всех типов коллекций в Java. Он предоставляет универсальные методы для добавления, удаления, поиска элементов и получения размера коллекции, которые могут использоваться для работы с любыми типами коллекций.
Хотя в JDK нет прямых реализаций интерфейса Collection, его наследуют более специализированные интерфейсы, такие как List, Set, и другие. В рамках этих интерфейсов доступны следующие основные методы:
boolean add(E item);– Добавляет элемент в коллекцию. Возвращаетtrue, если коллекция изменилась в результате вызова.void clear()– Удаляет все элементы из коллекции.boolean contains(Object item)– Проверяет, содержит ли коллекция указанный элемент.boolean isEmpty()– Возвращаетtrue, если коллекция пуста.boolean remove(Object item)– Удаляет один экземпляр указанного элемента из коллекции, если он присутствует.int size()– Возвращает количество элементов в коллекции.
Эти методы составляют основу работы с коллекциями в Java.
Интерфейс List
Интерфейс List расширяет Collection и представляет упорядоченную коллекцию, которая может содержать дубликаты элементов. В дополнение к методам из интерфейса Collection, List предоставляет дополнительные методы для работы с индексированными элементами.
Рассмотрим основные методы, предоставляемые интерфейсом List:
void add(int index, object obj)– Вставляет элементobjна позициюindex. Элементы, начиная с этой позиции, сдвигаются вправо.boolean addAll(int index, Collection coll)– Вставляет все элементы коллекцииcollв список, начиная с позицииindex.object get(int index)– Возвращает элемент, находящийся на указанной позиции.int indexOf(Object obj)– Возвращает индекс первого вхождения указанного элемента или -1, если элемент не найден.int lastindexOf(object obj)– Возвращает индекс последнего вхождения указанного элемента или -1, если элемент не найден.Object set(int index, object obj)– Заменяет элемент на указанной позиции на указанный элемент.List subList(int from, int to)– Возвращает часть списка от позицииfromвключительно до позицииtoисключительно.
ListIterator, который позволяет выполнять такие операции, как вставка, замена элементов и двунаправленная навигация по коллекции.Интерфейс Set
Интерфейс Set расширяет интерфейс Collection и предоставляет набор методов для работы с неупорядоченными коллекциями. Каждый элемент в множестве уникален. Уникальность элементов проверяется с использованием метода equals().
Основные методы интерфейса Set:
add(Object o)– Добавляет элемент в множество, если его там ещё нет. Если элемент уже присутствует, множество остаётся неизменным, и метод возвращаетfalse.addAll(Collection c)– Добавляет все элементы коллекции в множество, если они отсутствуют.clear()– Удаляет все элементы из множества.contains(Object o)– Проверяет наличие элемента в множестве. Возвращаетtrue, если элемент найден.containsAll(Collection c)– Проверяет, содержатся ли все элементы переданной коллекции в множестве. Возвращаетtrue, если все элементы присутствуют.isEmpty()– Возвращаетtrue, если множество не содержит элементов.remove(Object o)– Удаляет указанный элемент из множества, если он присутствует.size()– Возвращает количество элементов в множестве.
List, интерфейс Set не предоставляет методов для доступа к элементам по индексу, так как наборы не упорядочены.Следует быть особенно осторожными при добавлении изменяемых объектов в Set. Если объект изменяется после добавления в множество так, что это влияет на результат метода equals(), поведение множества может стать непредсказуемым. Рассмотрим пример, где это может вызвать проблемы:
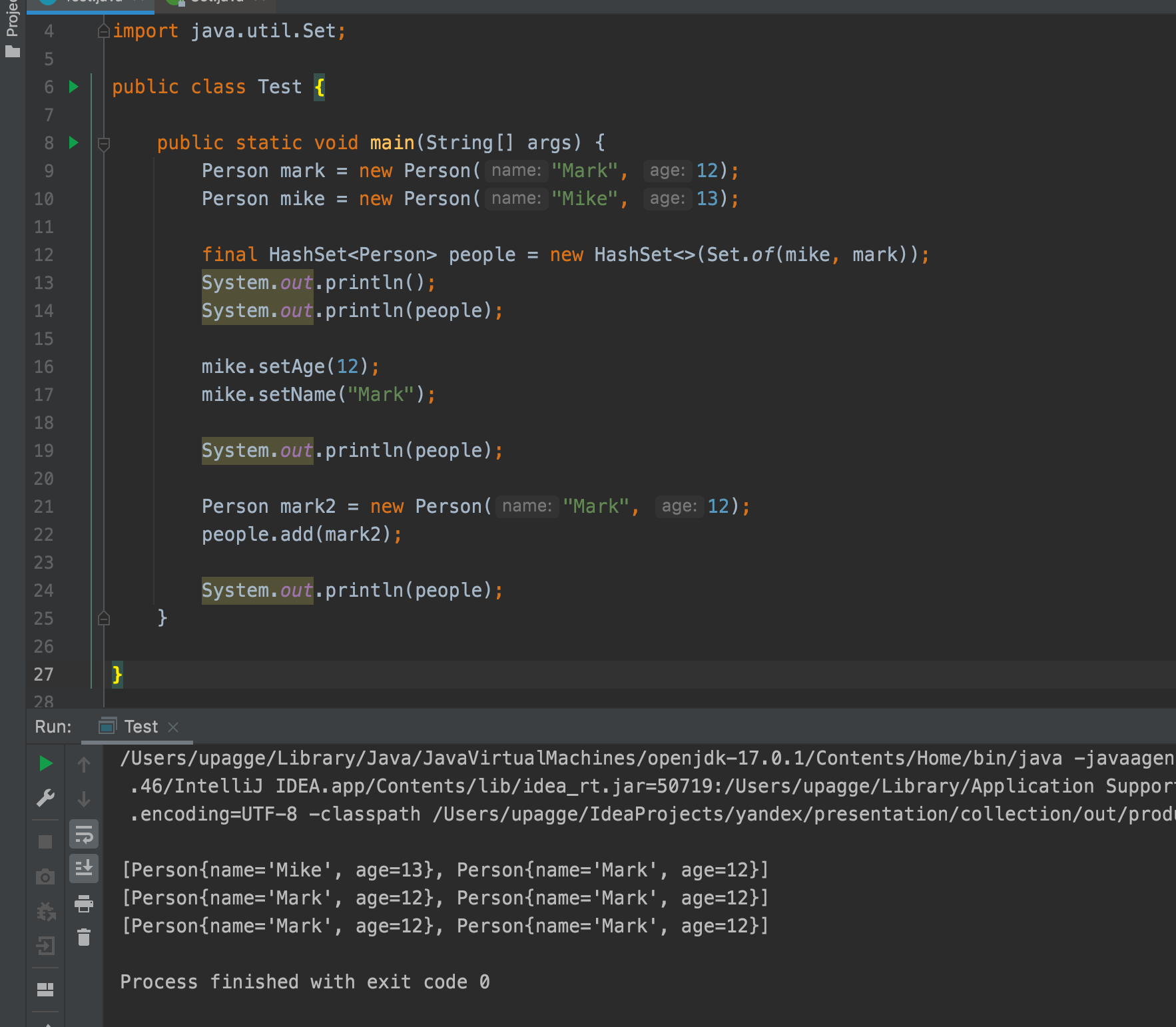
В этом примере мы создаем два объекта с разными именами, добавляем их в множество, а затем изменяем один объект так, что он становится равен другому. В результате может возникнуть ситуация, когда множество содержит дубликаты с точки зрения логики, хотя по правилам Set этого быть не должно.
Интерфейс Queue
Интерфейс Queue в Java Collection Framework предоставляет функциональность очереди — структуры данных, работающей по принципу “первый пришел, первый обслужен” (FIFO). Интерфейс Queue расширяет интерфейс Collection и предоставляет методы для управления элементами в порядке их поступления.
Основные методы интерфейса Queue:
boolean offer(E obj)— Вставляет указанный элемент в очередь, если это возможно сделать немедленно, не нарушая ограничений. Если элемент не может быть добавлен, возвращаетfalse, в отличие от методаadd(), который в такой ситуации генерирует исключение.E peek()— Возвращает, но не удаляет головной элемент очереди, или возвращаетnull, если очередь пуста.E poll()— Удаляет и возвращает головной элемент очереди, или возвращаетnull, если очередь пуста.E remove()— Удаляет и возвращает головной элемент очереди. Если очередь пуста, генерирует исключениеNoSuchElementException.
Интерфейс Deque
Интерфейс Deque (Double Ended Queue) расширяет Queue и представляет двустороннюю очередь, где элементы могут быть добавлены и удалены как с начала, так и с конца.
Основные методы интерфейса Deque:
- Добавление элементов:
void addFirst(E obj)— Вставляет элемент в начало очереди.void addLast(E obj)— Вставляет элемент в конец очереди.boolean offerFirst(E obj)— Добавляет элемент в начало, возвращаяtrue, если элемент успешно добавлен, илиfalse, если добавление не удалось.boolean offerLast(E obj)— Добавляет элемент в конец, возвращаяtrue, если элемент добавлен, илиfalse, если добавление не удалось.
- Получение элементов
E getFirst()— Возвращает первый элемент, не удаляя его. Если очередь пуста, генерирует исключениеNoSuchElementException.E getLast()— Возвращает последний элемент, не удаляя его. Если очередь пуста, генерирует исключениеNoSuchElementException.E peekFirst()— Возвращает первый элемент, не удаляя его. Если очередь пуста, возвращаетnull.E peekLast()— Возвращает последний элемент, не удаляя его. Если очередь пуста, возвращаетnull.
- Удаление элементов
E pollFirst()— Удаляет и возвращает первый элемент. Если очередь пуста, возвращаетnull.E pollLast()— Удаляет и возвращает последний элемент. Если очередь пуста, возвращаетnull.E pop()— Удаляет и возвращает первый элемент. Если очередь пуста, генерирует исключениеNoSuchElementException.E removeFirst()— Удаляет и возвращает первый элемент. Если очередь пуста, генерирует исключениеNoSuchElementException.E removeLast()— Удаляет и возвращает последний элемент. Если очередь пуста, генерирует исключениеNoSuchElementException.boolean removeFirstOccurrence(Object obj)— Удаляет первый встреченный элемент, равныйobj. Возвращаетtrue, если элемент был удалён.boolean removeLastOccurrence(Object obj)— Удаляет последний встреченный элемент, равныйobj. Возвращаетtrue, если элемент был удалён.
Интерфейс Map
Интерфейс Map в Java представляет коллекцию пар “ключ-значение”, где каждому ключу сопоставлено одно значение. Map отличается от других интерфейсов коллекций тем, что не является потомком интерфейса Collection. Однако, он остается частью Java Collection Framework и предоставляет мощные инструменты для работы с ассоциативными массивами.
Основные методы интерфейса Map:
boolean containsKey(Object k)– Возвращаетtrue, если коллекция содержит указанный ключk.boolean containsValue(Object v)– Возвращаетtrue, если коллекция содержит указанное значениеv.Set<Map.Entry<K, V>> entrySet()– Возвращает набор элементов коллекции. Каждый элемент представляет собой объектMap.Entry, содержащий пару “ключ-значение”.V get(Object k)– Возвращает значение, связанное с ключомk. Если такого ключа нет, возвращаетnull.V put(K k, V v)– Добавляет в коллекцию новую пару “ключ-значение” или заменяет значение для уже существующего ключа. Возвращает предыдущее значение для ключа, если оно было, иначе возвращаетnull.V putIfAbsent(K k, V v)– Добавляет пару “ключ-значение” только если такого ключа ещё нет в карте.Set<K> keySet()– Возвращает набор всех ключей коллекции.Collection<V> values()– Возвращает список всех значений коллекции.void putAll(Map<? extends K, ? extends V> map)– Добавляет в коллекцию все элементы из коллекцииmap.V remove(Object k)– Удаляет пару с указанным ключомk.int size()– Возвращает количество пар в коллекции.
Интерфейс Map.Entry
Интерфейс Map.Entry представляет пару “ключ-значение” внутри коллекции. Он предоставляет методы для получения и изменения ключа и значения.
Методы интерфейса Map.Entry:
V getValue()– Возвращает значение.K getKey()– Возвращает ключ.V setValue(V v)– Устанавливает новое значение для текущего ключа.
Предположим, что у вас есть коллекция, которая хранит данные о “холопах” и их богатстве. В какой-то момент вам нужно собрать ренту с тех, чье богатство превышает 100 золотых. Для этого удобно использовать метод entrySet(), чтобы обойти коллекцию и изменить значения.
final Map<String, Integer> customers = new HashMap<>(
Map.of("Холоп 1", 100, "Холоп 2", 20, "Холоп 3", 200)
);
final Set<Map.Entry<String, Integer>> entries = customers.entrySet();
int coffers = 0;
for (Map.Entry<String, Integer> entry : entries) {
final Integer wealth = entry.getValue();
if (wealth > 100) {
entry.setValue(wealth - 10);
coffers += 10;
}
}
System.out.println("\nКазна пополнилась на " + coffers + " золотых, Миллорд!");
System.out.println(customers.values());Этот код использует метод entrySet(), чтобы получить набор элементов карты, затем с помощью цикла проходит по каждому элементу, проверяя, превышает ли богатство “холопа” 100 золотых. Если условие выполняется, у холопа вычитается 10 золотых, и сумма добавляется в казну. Метод setValue() позволяет обновить значение в карте.
Реализации коллекций
После того как мы рассмотрели основные интерфейсы Java Collection Framework, давайте перейдём к обсуждению конкретных реализаций. Начнём с одной из самых популярных реализаций — ArrayList.
ArrayList
ArrayList в Java — это динамический массив, который хранит свои элементы внутри обычного массива объектов (Object[]).

ArrayList обычный массивКаждый экземпляр ArrayList имеет емкость (CAPACITY). Емкость – это размер массива, который используется для хранения элементов. По мере добавления элементов в ArrayList его емкость автоматически увеличивается.
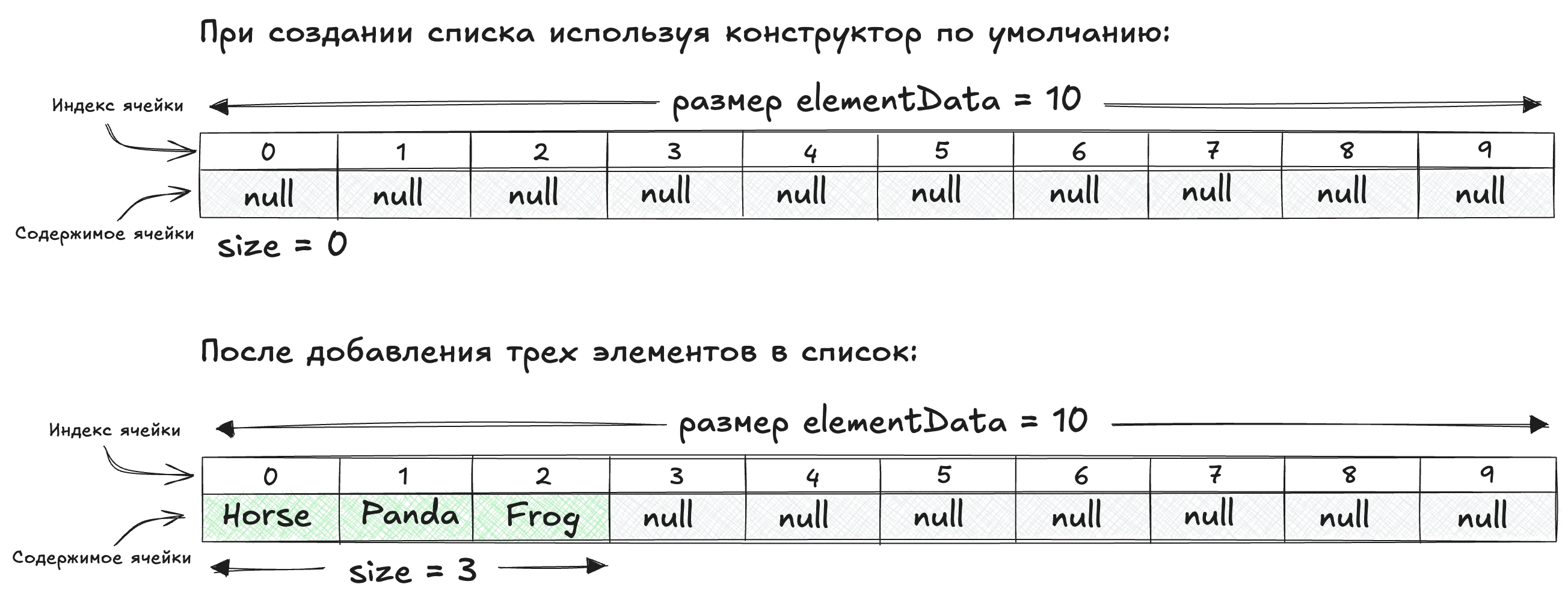
Когда массив заполняется, его ёмкость увеличивается. Новая ёмкость вычисляется по формуле: старая ёмкость * 1.5 + 1. Например, если начальная ёмкость была 10, то после расширения она станет 16.
При увеличении ёмкости создаётся новый массив, и все элементы из старого копируются в новый, что является затратной операцией. Поэтому, если заранее известно, что список будет большим, лучше сразу задать достаточную начальную ёмкость.
capacity равен 10. Вы можете передать свое значение capacity используя конструктор public ArrayList(int initialCapacity).Удаление элементов из середины списка может быть затратной операцией, так как все последующие элементы смещаются влево, что требует копирования данных. Также стоит отметить, что размер внутреннего массива автоматически не уменьшается после удаления элементов.
trimToSize() позволяет уменьшить ёмкость ArrayList до фактического количества элементов. Он полезен, если список часто изменяется и его размер значительно сократился. Этот метод отсутствует в интерфейсе List, он доступен только в ArrayList.ArrayList не синхронизирован, поэтому не является потокобезопасным. Если несколько потоков одновременно изменяют список, его состояние может стать непредсказуемым. Если требуется потокобезопасная структура данных, лучше использовать Vector или вручную синхронизировать доступ к ArrayList через блоки синхронизации.
Выводы
- Внутри используется простой массив.
- Ёмкость увеличивается автоматически, но не уменьшается, если элементы удаляются.
- Не является потокобезопасным.
- Обеспечивает быстрый доступ к элементам по индексу (время доступа — O(1)).
- Поиск элементов по значению осуществляется за линейное время (O(n)).
- Допускает хранение
nullзначений.
LinkedList
LinkedList реализует интерфейсы List и Deque, предоставляя двусвязный список. Каждый элемент списка (узел) содержит ссылки как на следующий, так и на предыдущий элементы, что делает эту структуру данных двусторонне связанной.
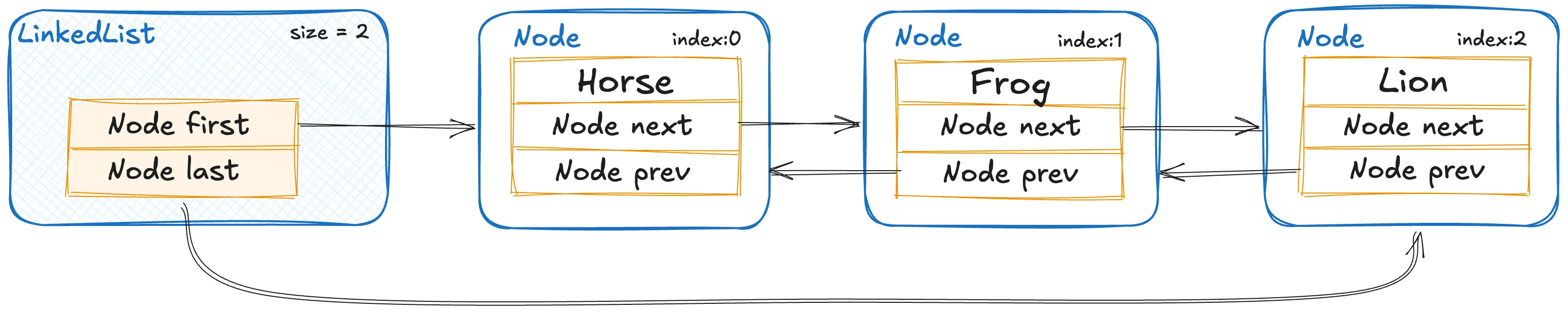
Класс LinkedList содержит три основных поля:
Node<E> first– Ссылка на первый элемент списка.Node<E> last– Ссылка на последний элемент списка.int size– Количество элементов в списке
Каждый узел (Node) хранит два элемента: данные и ссылки на следующий и предыдущий узлы.
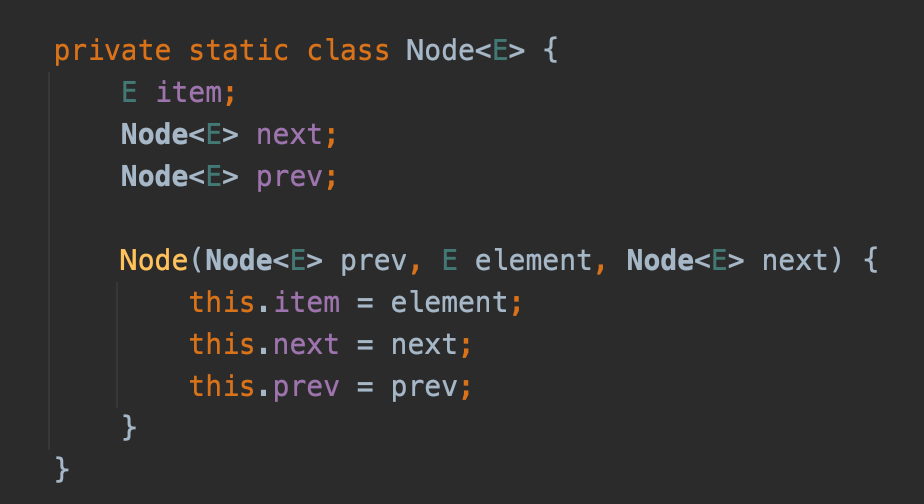
Добавление элементов в конец списка
- Создаётся новый узел (
Node). - Устанавливается значение (
item) для нового узла. - Ссылки узла добавляются в конец списка.
- Устанавливаются ссылки на предыдущий и следующий узлы (для нового и соседних узлов).
Добавление элемента в середину списка
- Проверяется индекс. Если он отрицательный или превышает размер списка, выбрасывается исключение
IndexOutOfBoundsException. - Если индекс равен размеру списка, элемент добавляется в конец.
- Вставка в середину происходит перед элементом с указанным индексом:
- Метод
node(index)находит узел по индексу. - Определяется место вставки (поиск узла идёт с начала или конца списка в зависимости от индекса).
- Создаётся новый узел, и его ссылки устанавливаются между соседними узлами.
- Метод
- Обновляются ссылки на предыдущие и следующие узлы для нового элемента и его соседей.
- Увеличивается размер списка.
Удаление элемента из связного списка по значению:
- Последовательно сравниваются элементы списка с заданным значением, начиная с первого узла.
- Когда найден узел с соответствующим значением, элемент сохраняется в отдельную переменную.
- Ссылки соседних узлов перенаправляются так, чтобы исключить удаляемый элемент.
- Очищаются ссылки и данные узла, который содержал удалённый элемент, и уменьшается размер списка.
Как и ArrayList, LinkedList не синхронизирован, что делает его непригодным для использования в многопоточной среде без дополнительной синхронизации. Если требуется потокобезопасная реализация, можно использовать Collections.synchronizedList.
Выводы
LinkedListне является потокобезопасным.- Позволяет хранить любые объекты, включая
nullи повторяющиеся значения. - Вставка и удаление первого и последнего элементов выполняются за константное время — O(1). Не учитывая время поиска позиции элемента, который осуществляется за линейное время O(n);
- Поиск элементов по индексу или значению выполняется за линейное время — O(n).
HashMap
HashMap — одна из наиболее часто используемых реализаций интерфейса Map в Java, которая хранит данные в виде пар “ключ-значение”.
Внутри HashMap используется массив, где каждый элемент представляет собой связанный список (или “bucket”), состоящий из узлов (Node).

Каждый Node представляет собой связный список, который содержит четыре поля:
int hash– хеш-код ключа.K key– ключ.V value– значение.Node<K,V> next– ссылка на следующий узел в списке (если есть коллизии).
HashMap имеет два ключевых параметра, которые влияют на производительность:
- Начальная ёмкость (capacity) — это количество сегментов (ячейка в массиве) в хеш-таблице. По умолчанию ёмкость равна 16 и должна быть степенью двойки.
- Коэффициент загрузки (load factor) — это отношение, определяющее, насколько заполненной может быть хеш-таблица, прежде чем произойдёт её расширение. По умолчанию коэффициент загрузки равен 0.75. Когда количество элементов превышает произведение коэффициента загрузки и текущей ёмкости, происходит перестройка таблицы (рехеширование).
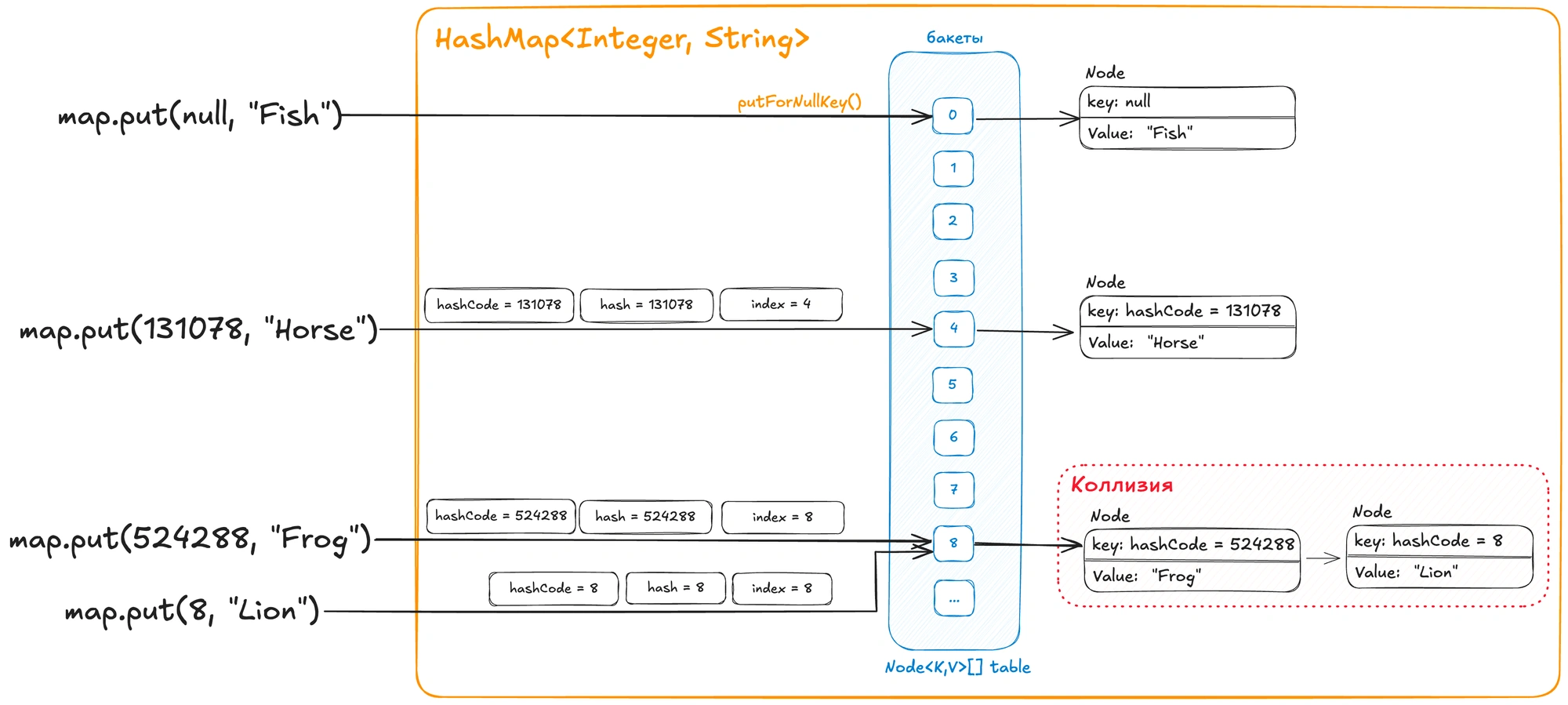
Как добавляется элемент?
- Проверка на
null: Если ключ равенnull, элемент добавляется в нулевую ячейку массива с помощью методаputForNullKey(). - Определение индекса бакета: Для всех остальных ключей происходит вычисление индекса, куда элемент будет помещён в хеш-таблицу.
- Генерация хеш-кода: Сначала генерируется хеш-код с использованием метода
hashCode(). - Перемешанный хеш-код: Затем вызывается код для вычисления “перемешанного” хеш-кода, который выглядит следующим образом:
hash = (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);. Перемешанный хеш-код помогает уменьшить количество коллизий. - После этого переменная
hashиспользуется для вычисления индекса в массиве, где будет храниться элемент:int index = (length - 1) & hash;
- Генерация хеш-кода: Сначала генерируется хеш-код с использованием метода
- Размещение элемента:
- Если ячейка пуста: Создаётся новый узел (
Node), и элемент записывается в массив по вычисленному индексу. - Если в ячейке уже есть элемент: Происходит сравнение ключей с помощью метода
equals().- Если ключ не найден, создаётся новый узел и добавляется в список, что может произойти из-за коллизии (когда разные объекты имеют одинаковый хеш-код).
- Если ключ совпадает, старое значение затирается новым.
- Если ячейка пуста: Создаётся новый узел (
null ключами всегда записываются в нулевую ячейку массива.Идеальный случай для HashMap — когда каждый “bucket” содержит только один элемент, обеспечивая доступ к данным за время O(1). Однако коллизии (когда несколько ключей имеют одинаковый хеш-код) неизбежны. В таких случаях элементы хранятся в виде связного списка, что может ухудшить производительность до O(n).
TreeMap
TreeMap — это реализация интерфейса SortedMap, которая расширяет возможности интерфейса Map и предоставляет возможность хранить пары “ключ-значение” в отсортированном порядке по ключам. В основе TreeMap лежит структура данных под названием красно-чёрное дерево.
Ключи в TreeMap всегда отсортированы, что делает его идеальным выбором, если требуется доступ к элементам в упорядоченном виде. А все операции — вставка, удаление и поиск — выполняются за логарифмическое время O(log(n)), где n — количество элементов в дереве.
Красно-чёрное дерево — это самобалансирующееся бинарное дерево поиска с добавлением атрибута “цвет” для каждого узла, который может быть либо красным, либо чёрным.
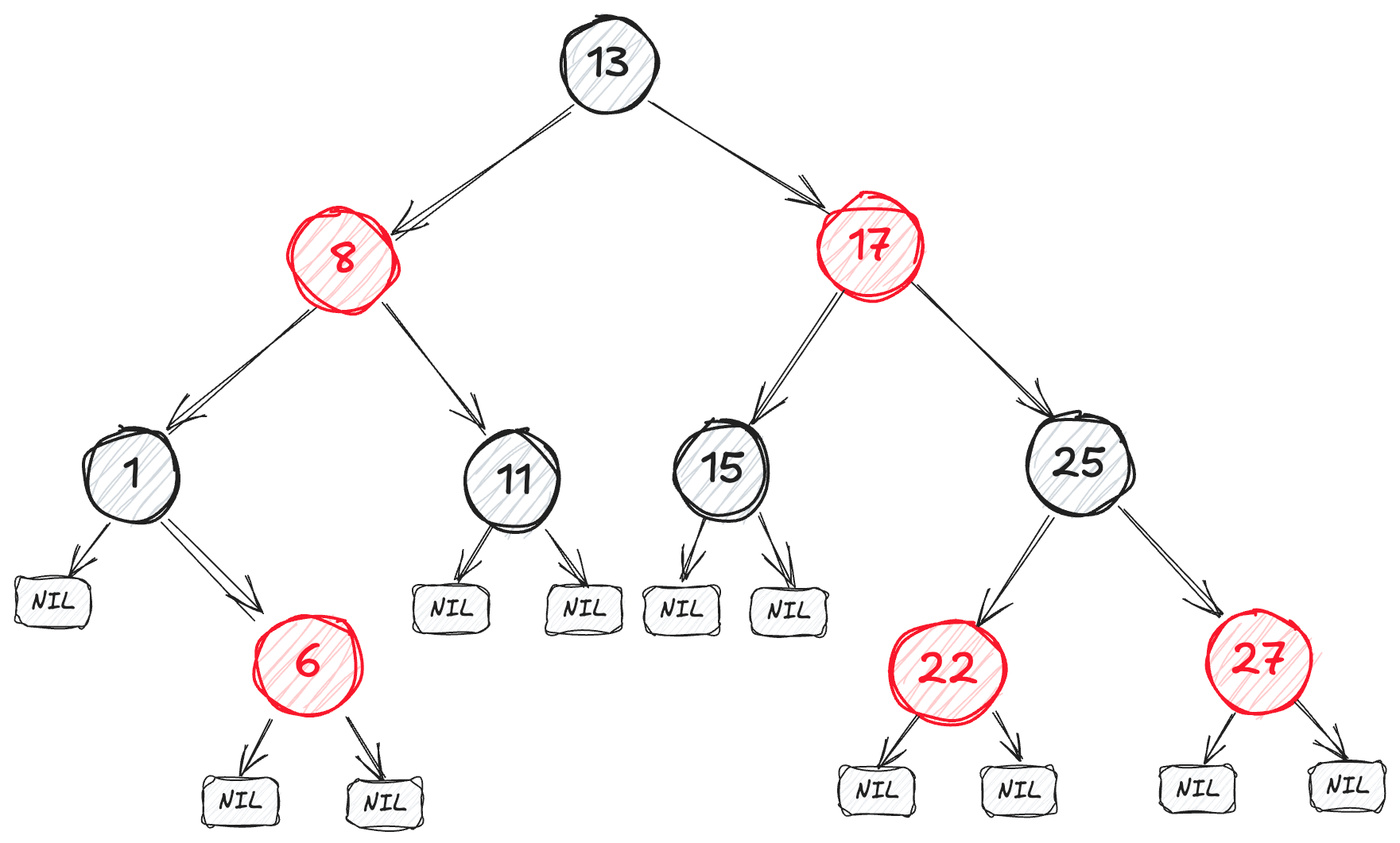
Требования красно-черного дерева:
- Цвет узлов: Каждый узел либо красный, либо чёрный.
- Корень: Корневой узел всегда чёрный.
- Листья: Листья дерева (так называемые null-узлы) всегда чёрные и не содержат данных.
- Красные узлы: У каждого красного узла оба потомка чёрные.
- Чёрный путь: Все пути от любого узла до его листьев содержат одинаковое количество чёрных узлов.
Эти правила обеспечивают сбалансированность дерева, что гарантирует, что высота дерева всегда остаётся близкой к логарифму от количества элементов. Благодаря этому достигается эффективность операций.
Подробнее о работе красно-черных деревьях
HashSet
HashSet — это реализация интерфейса Set, которая использует хеш-таблицу для хранения элементов. Благодаря этому, операции добавления, удаления и поиска выполняются за константное время — O(1) в среднем.
В основе HashSet лежит HashMap, хотя это может показаться неожиданным.

Когда вы добавляете элемент в HashSet, он фактически добавляется как ключ в HashMap, где значением для этого ключа является константа. Таким образом, HashSet использует мощность хеширования HashMap для обеспечения уникальности элементов и быстрого доступа.


Вывод:
- Константное время: Операции добавления, удаления и поиска выполняются за O(1).
- Отсутствие порядка: Порядок элементов в
HashSetне гарантируется. - Уникальность элементов: Элементы считаются одинаковыми, если метод
equals()возвращаетtrue, а их хеш-коды совпадают.
TreeSet
TreeSet — это реализация интерфейса Set, которая использует красно-чёрное дерево для хранения элементов. Под капотом TreeSet работает с использованием TreeMap, аналогично тому, как HashSet использует HashMap.
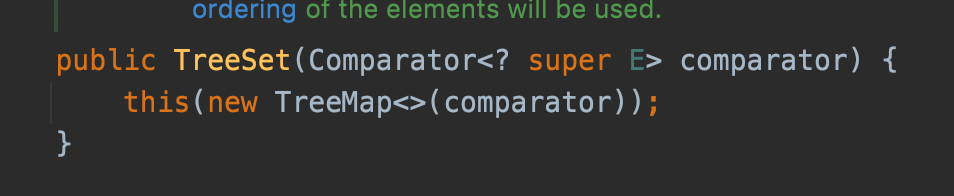
В отличие от HashSet, TreeSet гарантирует упорядоченность элементов по возрастанию (или в соответствии с указанным компаратором). Операции добавления, удаления и поиска выполняются за логарифмическое время — O(log(n)), благодаря сбалансированности красно-чёрного дерева.
Выводы:
- Логарифмическое время: Операции добавления, удаления и поиска выполняются за O(log(n)).
- Упорядоченность: Элементы хранятся в отсортированном порядке.
- Гарантия уникальности: Элементы считаются одинаковыми, если метод
compareTo()или компаратор определяет их как равные.
Производительность различных коллекций
Понимание производительности различных коллекций в Java является важным аспектом при выборе правильной структуры данных для конкретной задачи. Разные коллекции обладают разными характеристиками производительности для различных операций, таких как вставка, удаление, поиск и доступ к элементам. Оптимальный выбор коллекции может значительно улучшить производительность приложения.
ArrayList vs LinkedList
ArrayList:
- Добавление и удаление: Вставка или удаление элементов в середине списка занимает O(n), так как элементы сдвигаются для поддержания порядка.
- Доступ по индексу: Доступ к произвольному элементу по индексу происходит за O(1), так как
ArrayListиспользует массив.
LinkedList:
- Добавление и удаление: Вставка или удаление элементов на краю списка занимает O(1). Однако, для вставки или удаления элемента в середине списка требуется найти его позицию, что занимает O(n).
- Доступ по индексу: Доступ к произвольному элементу выполняется за O(n), так как для этого нужно пройти по элементам списка от начала до нужного индекса.
Несмотря на то, что вставка и удаление элементов в середине списка для ArrayList требует O(n), производительность ArrayList всё же остаётся приемлемой для большинства случаев благодаря нативному методу System.arraycopy(), который используется для копирования массивов. Этот метод оптимизирован на уровне системы, что делает его работу быстрой даже для больших массивов.
Вывод: Используйте ArrayList, если вам важен быстрый доступ по индексу, и LinkedList, если важна эффективность вставки и удаления элементов в начале или конце списка.
HashSet vs TreeSet
HashSet:
- Добавление, удаление и поиск: Основные операции выполняются за O(1) благодаря использованию хеш-таблицы.
- Порядок элементов: Не поддерживает порядок элементов.
TreeSet:
- Добавление, удаление и поиск: Эти операции занимают O(log(n)), так как элементы хранятся в виде красно-чёрного дерева.
- Порядок элементов: Поддерживает естественный порядок элементов или порядок, заданный компаратором.
Вывод: Если порядок элементов важен, стоит использовать TreeSet, несмотря на более медленные операции. В противном случае HashSet является более производительным вариантом.
HashMap vs TreeMap
HashMap:
- Добавление, удаление и поиск: Основные операции выполняются за O(1) благодаря хеш-таблице.
- Порядок ключей: Не поддерживает упорядоченность ключей.
TreeMap:
- Добавление, удаление и поиск: Эти операции выполняются за O(log(n)), поскольку TreeMap использует красно-чёрное дерево.
- Порядок ключей: Поддерживает естественный порядок ключей или порядок, заданный компаратором.
Вывод: Если вам нужно быстрое выполнение операций без учёта порядка ключей, используйте HashMap. Если требуется хранение ключей в отсортированном порядке, следует выбрать TreeMap.
Сортировка коллекций
Ручное написание сложных алгоритмов сортировки, таких как “пузырьковая” сортировка, уже давно осталось в прошлом. В Java сортировка коллекций стала намного проще благодаря интерфейсам Comparator и Comparable.
Интерфейс Comparator<T>
Этот интерфейс позволяет вам создать внешний "сортировщик" (компаратор), который можно передать в методы сортировки.
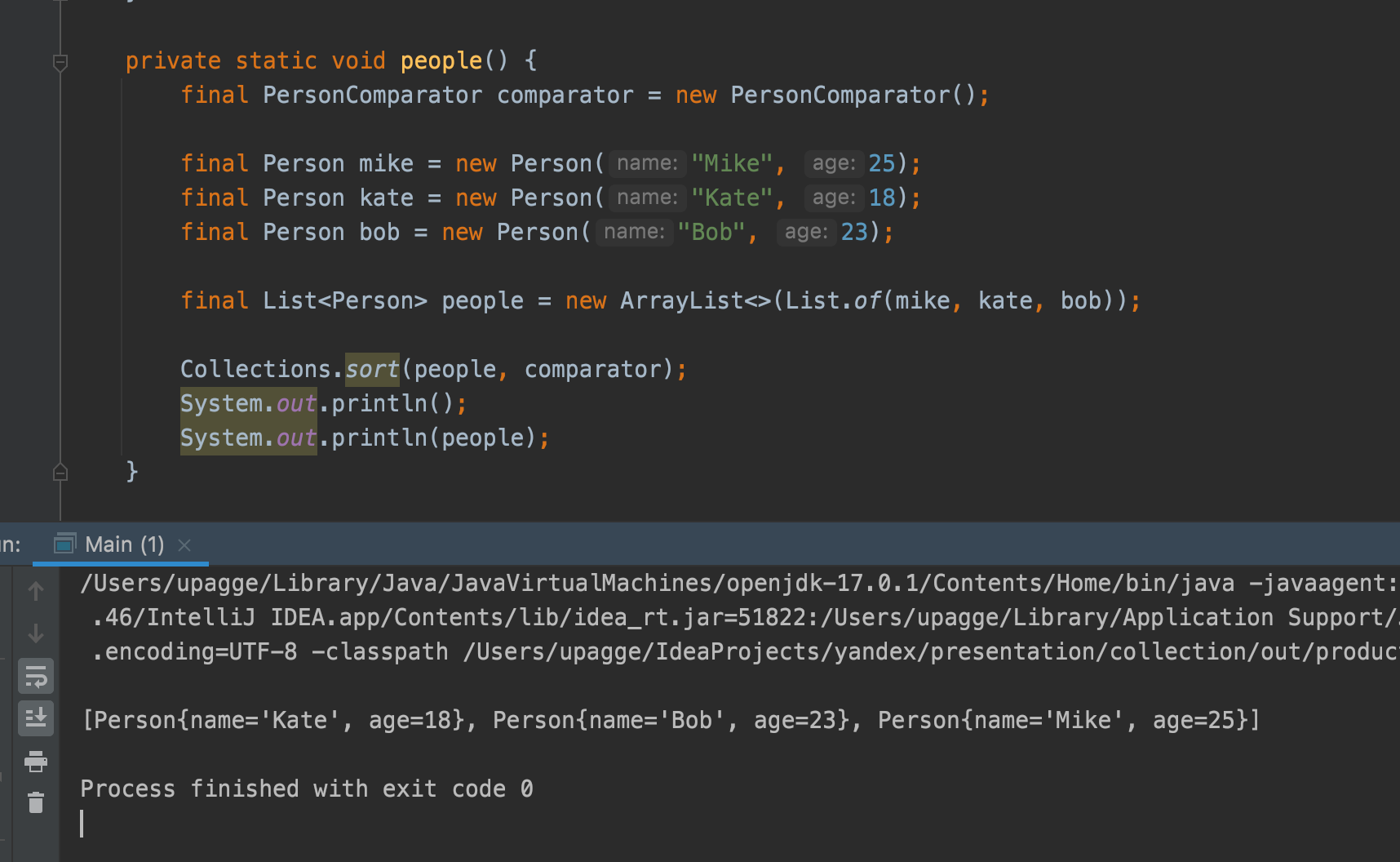
Создайте класс, который реализует интерфейс Comparator, и определите метод compare(T o1, T o2) для сравнения двух объектов.
package dev.struchkov.collection.comparator;
import java.util.Comparator;
public class PersonComparator implements Comparator<Person> {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
}- Если
o1меньшеo2, метод должен вернуть отрицательное число. - Если объекты равны, метод возвращает
0. - Если
o1большеo2, метод возвращает положительное число.
Таким образом, вы можете сами определить, по какому критерию сравнивать объекты (например, по возрасту, имени и т.д.).
Если нужно отсортировать элементы в обратном порядке, вместо создания нового компаратора можно использовать метод reversed():
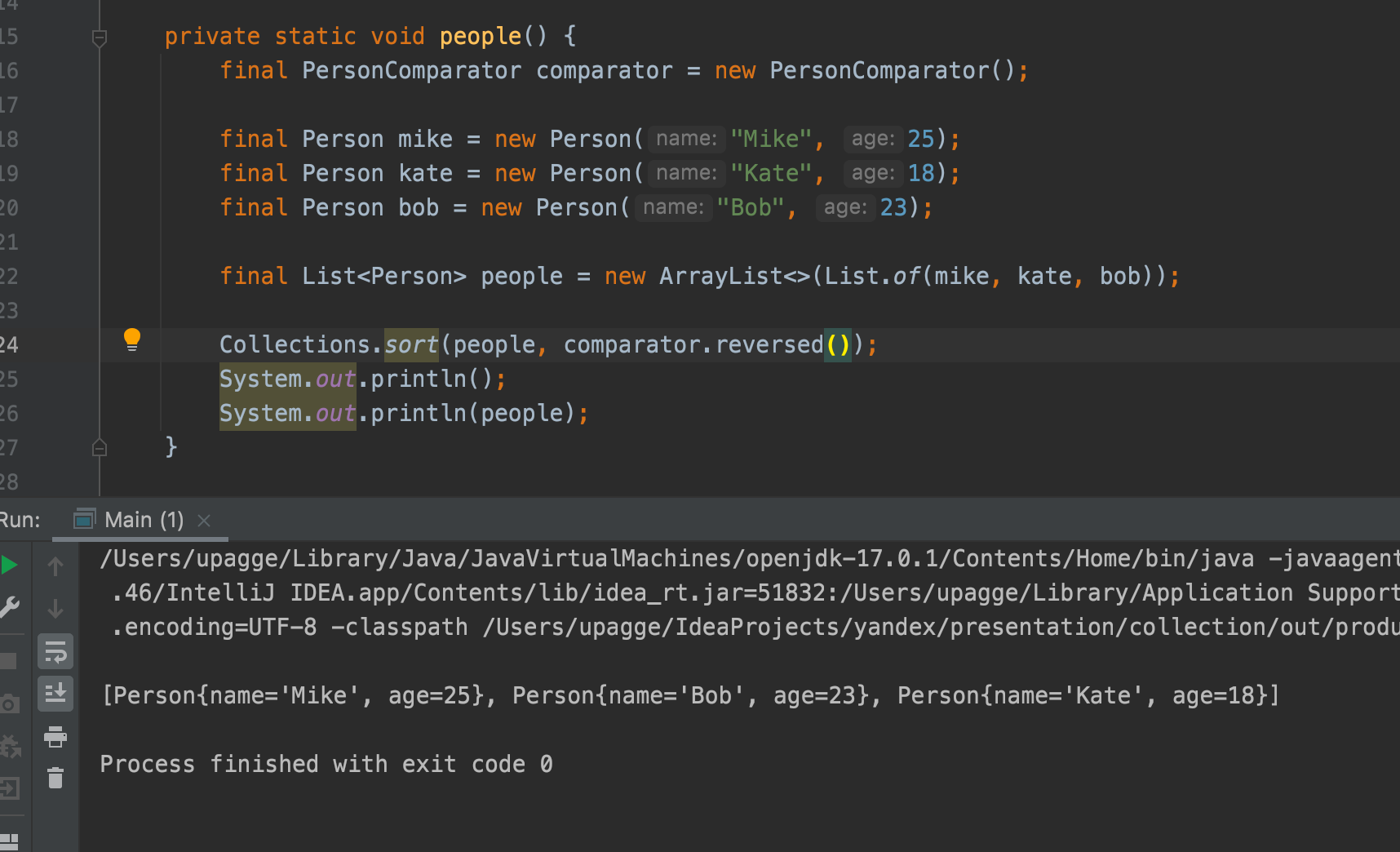
Collections.sort() или передать его в конструктор TreeSet для определения порядка элементов множества.Интерфейс Comparable<T>
Если вы хотите сделать сортировку “встроенной” в ваш класс, можно реализовать интерфейс Comparable у самого класса, который нужно сортировать. В этом случае объекты этого класса будут иметь естественный порядок сортировки, и для сортировки их не потребуется отдельный компаратор.
@Override
public int compareTo(Person o) {
return this.age - o.getAge();
}В этом примере метод compareTo() реализует ту же логику, что и компаратор, но встроен в сам класс.
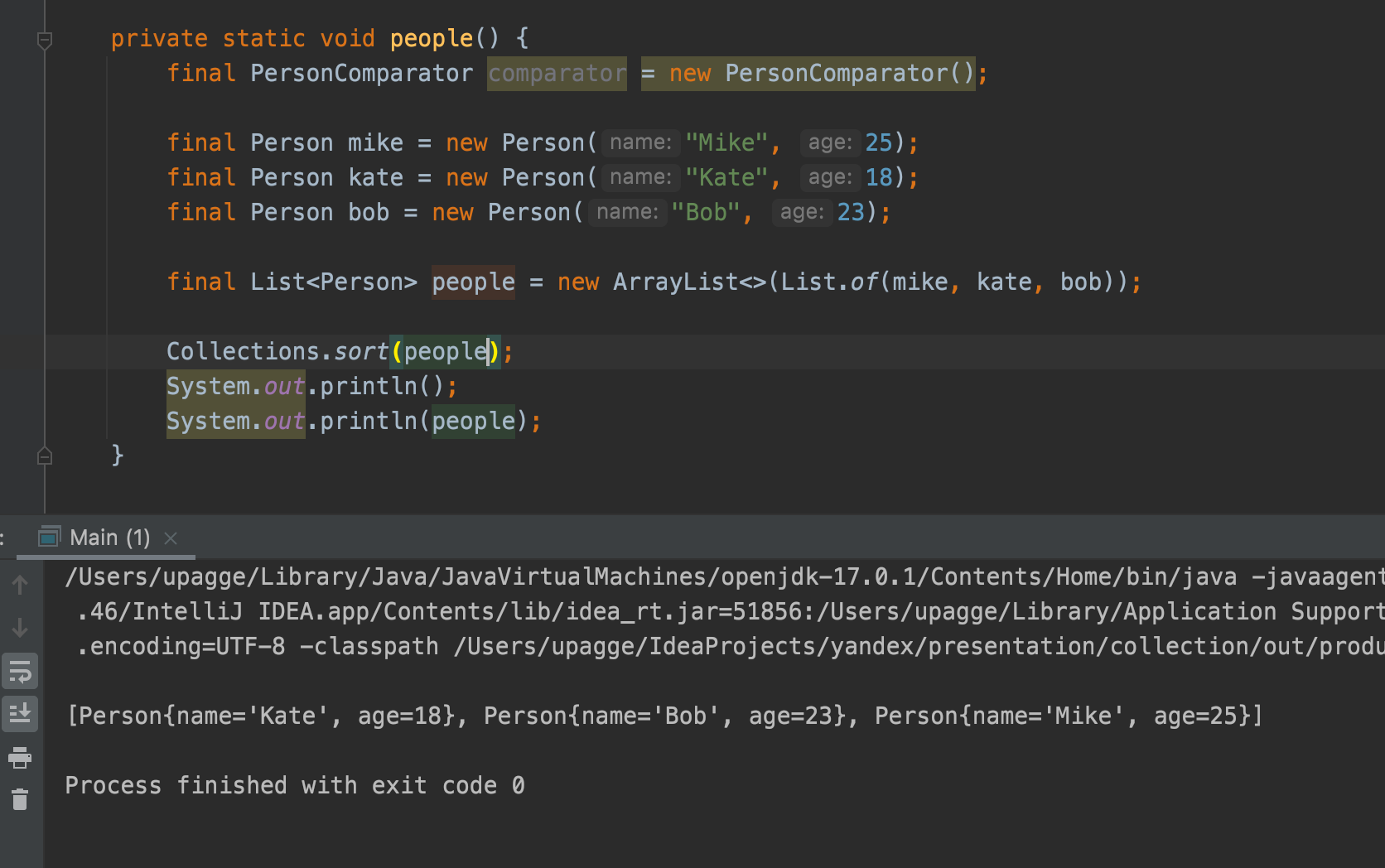
Для обратного порядка можно также использовать метод Collections.reverseOrder():
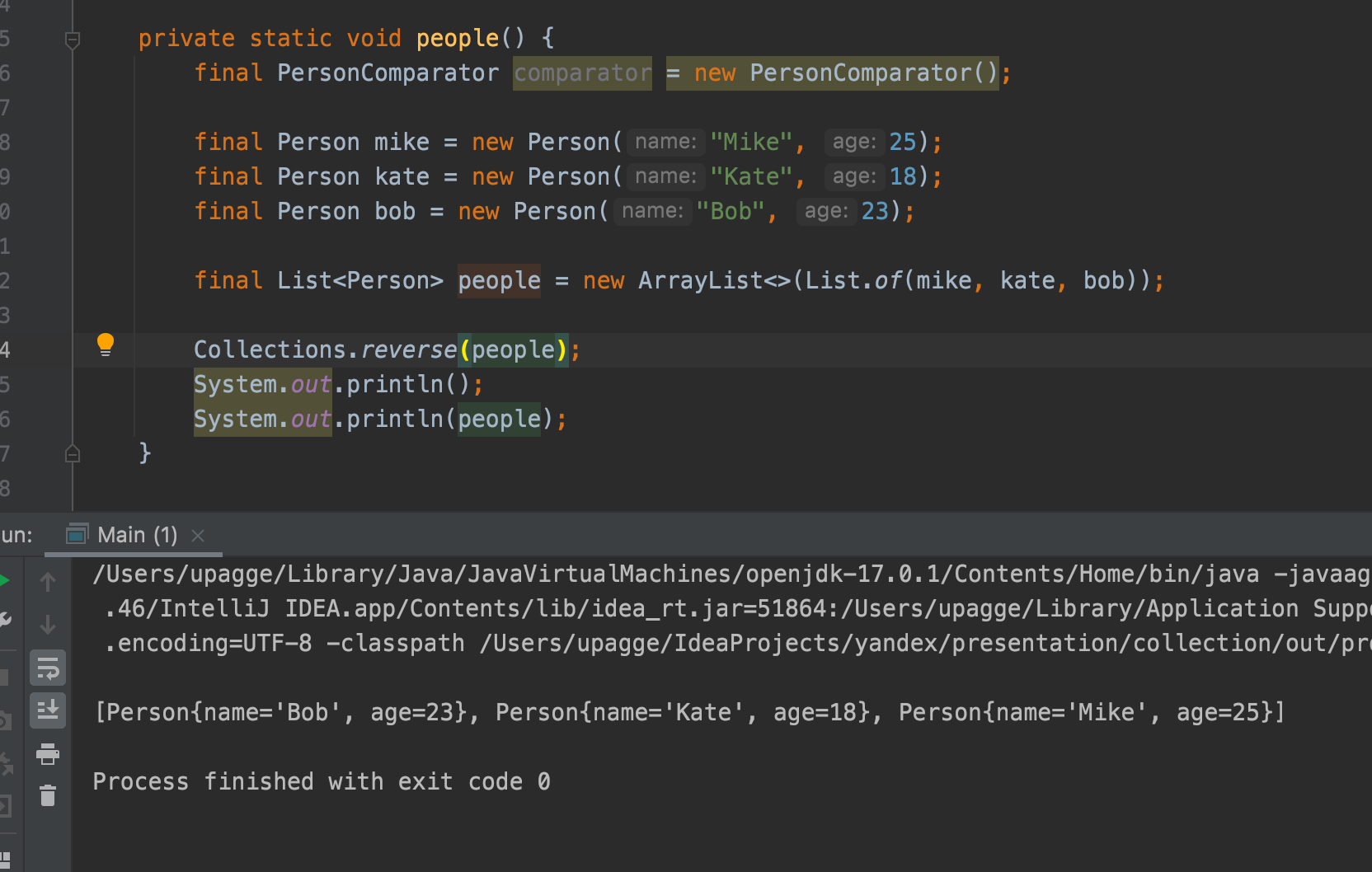
Многопоточность и коллекции
Потокобезопасность — это важная тема в многопоточном программировании, касающаяся способности кода корректно выполняться при одновременном доступе к ресурсам несколькими потоками.
Потокобезопасная коллекция гарантирует целостность данных и корректность операций, даже если к ней одновременно обращаются несколько потоков.
Большинство классов из Java Collection Framework не являются потокобезопасными. Это включает: ArrayList, LinkedList, HashSet, LinkedHashSet, HashMap и LinkedHashMap. Эти коллекции не синхронизированы, и если к ним обращаются одновременно несколько потоков, возможны некорректные изменения данных.
Потокобезопасные коллекции
В Java существуют специальные потокобезопасные коллекции, которые могут безопасно использоваться в многопоточной среде.
Vector и Hashtable — это старые коллекции, предшественники ArrayList и HashMap соответственно. Они обеспечивают потокобезопасность за счёт синхронизации всех своих методов. Однако, из-за постоянной синхронизации использование этих коллекций может приводить к снижению производительности, особенно при высоких нагрузках.
Для повышения производительности в многопоточной среде, Java предоставляет более современные потокобезопасные коллекции, доступные в пакете java.util.concurrent.
К ним относятся:
CopyOnWriteArrayList— потокобезопасная альтернативаArrayList, где операции изменения создают копию списка, что исключает проблемы, связанные с итерацией.ConcurrentHashMap— потокобезопасная версияHashMap, оптимизированная для работы в многопоточных средах без блокировок всех операций.ConcurrentLinkedQueue— неблокирующая очередь, основанная на связанных узлах.
Эти коллекции предлагают значительно лучшую производительность по сравнению с Vector и Hashtable, так как они минимизируют блокировки, используя более эффективные подходы к синхронизации.
Синхронизированные обертки
Если вам нужно создать потокобезопасную коллекцию на основе не потокобезопасной коллекции, вы можете использовать синхронизированные обёртки из класса Collections. Например:
List<String> syncList = Collections.synchronizedList(new ArrayList<>());Это создаёт потокобезопасную версию ArrayList, которая синхронизирует доступ ко всем операциям списка.
Использование Stream API
Stream API предоставляет функциональные методы для удобной и эффективной обработки коллекций. Он позволяет писать более чистый, лаконичный код и особенно полезен при работе с большими объемами данных.
Более подробно о возможностях и примерах использования Stream API можно узнать в следующей статье 👇
 Struchkov Mark
Struchkov Mark
Лучшие практики
Работа с коллекциями в Java может быть простой, но соблюдение определённых практик помогает сделать ваш код более эффективным и надёжным.
Интерфейсы вместо конкретных реализаций
Предпочтительно использовать интерфейсы (List, Set, Map) вместо привязки к конкретной реализации коллекций. Это позволяет легко заменить одну реализацию на другую без необходимости изменения остального кода.
List<String> myList = new ArrayList<>(); // Вместо: ArrayList<String> myList = new ArrayList<>();
Методы equals() и hashCode()
При работе с пользовательскими объектами, особенно в коллекциях типа Set и Map, обязательно переопределяйте методы equals() и hashCode(). Это гарантирует правильное сравнение объектов и корректную работу коллекций, использующих хеширование.
Утилитарные классы Collections
Класс Collections предоставляет множество полезных методов для работы с коллекциями: сортировка, поиск, создание неизменяемых коллекций и другие операции. Используйте его для упрощения работы с коллекциями.
Collections.sort(myList); // Сортирует список myList
Использование java.util.Objects
Класс Objects предоставляет удобные утилиты для работы с объектами.
Например, метод requireNonNull() помогает избежать NullPointerException и позволяет задать более информативные сообщения об ошибке.
Objects.requireNonNull(myList, "Список не должен быть null");
Заключение
Java Collection Framework — это важный и мощный инструмент для каждого разработчика на Java. Он предлагает широкий набор структур данных, таких как списки, множества и карты, а также методы для выполнения распространённых операций: добавления, удаления и поиска элементов.
Понимание иерархии и принципов работы Java Collection Framework позволяет эффективно использовать его возможности. Важно тщательно выбирать конкретные реализации коллекций в зависимости от требований вашего проекта, а также следовать лучшим практикам для обеспечения производительности и надёжности кода.
Надеюсь, эта статья помогла вам глубже понять Java Collection Framework и его потенциал. Помните, что ключ к мастерству — это практика: чем больше вы работаете с фреймворком, тем лучше понимаете, как использовать его наиболее эффективно.
Хорошее знание Java Collection Framework — это залог успешного программирования на Java. Продолжайте учиться, экспериментировать и совершенствоваться!
