Мы всё активнее используем современные языки программирования, которые позволяют писать минимальное количество кода для решения задач. Рассмотрим Java: вам не нужно заботиться о выделении и освобождении памяти — все усилия могут быть направлены на решение бизнес-задач. Однако такое упрощение имеет свою цену.
В прошлой статье мы обсудили общее устройство памяти в компьютере. В этой статье мы сосредоточимся на том, как Java управляет памятью. В частности, рассмотрим работу стека и кучи в контексте Java и сравним их с общими принципами работы памяти. Также обсудим роль сборщика мусора в управлении памятью.
Устройство памяти в программировании
Переходим к анализу ключевых концепций программирования, связанных с управлением памятью. Сначала обсудим стек и кучу — два фундаментальных механизма, которые лежат в основе управления памятью. Затем рассмотрим их взаимодействие и особенности работы при выполнении функций и методов.
Стек и куча — это области памяти, которые программы используют для хранения данных во время выполнения, однако они предназначены для разных целей и работают по-разному.
Стек (Stack)
Стек — это область памяти, в которой функции хранят свои переменные и информацию, необходимую для выполнения.
Представьте стек как стопку подносов в ресторане: вы можете добавить поднос сверху (push) или взять верхний поднос (pop). Точно так же, когда вызывается функция, её локальные переменные и информация о вызове помещаются на вершину стека, а при завершении функции эти данные удаляются с вершины.
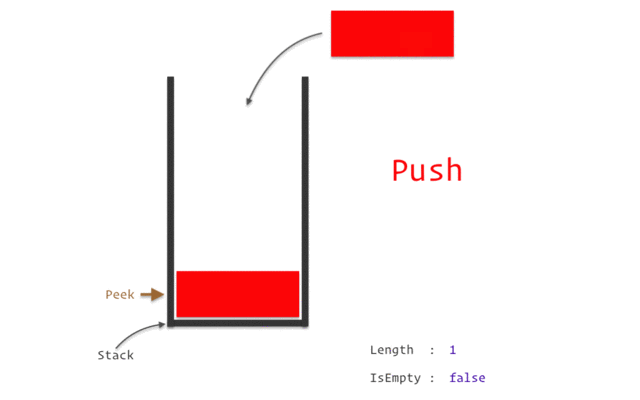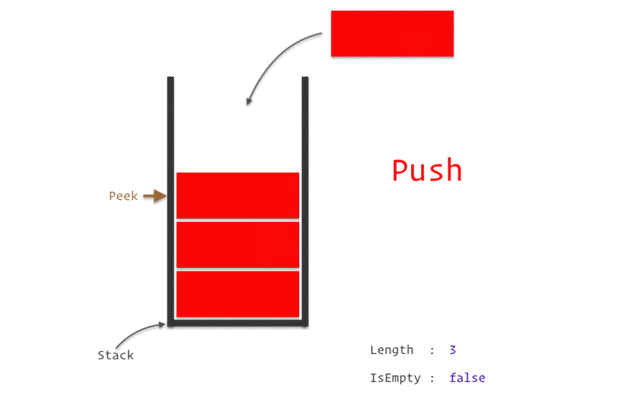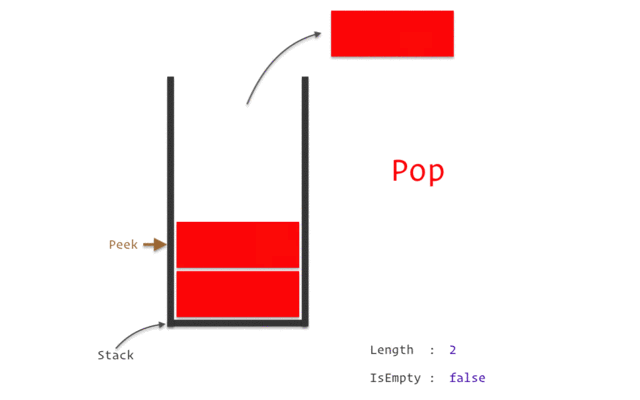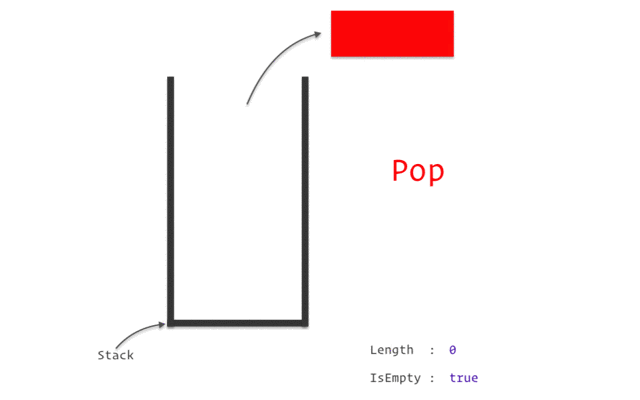
Стек обеспечивает быстрый доступ к данным и автоматическое управление памятью, но его размер ограничен. Если программа потребляет больше стековой памяти, чем доступно, это может привести к ошибке переполнения стека.
Куча (Heap)
Куча — это область памяти, где данные могут выделяться динамически во время выполнения программы. В отличие от стека, где данные удаляются автоматически после завершения функции, данные в куче остаются, пока не будут явно удалены.
Куча идеально подходит для хранения данных, которые должны существовать дольше времени выполнения функции, или для работы с большими объёмами данных. Однако работа с кучей требует тщательного управления: если объекты не удаляются, когда они больше не нужны, это может привести к утечке памяти, что, в свою очередь, может вызвать исчерпание доступной памяти.
Для наглядности представим стек и кучу. Серые объекты потеряли свою связь со стеком, и их нужно удалить, чтобы освободить память для новых объектов.
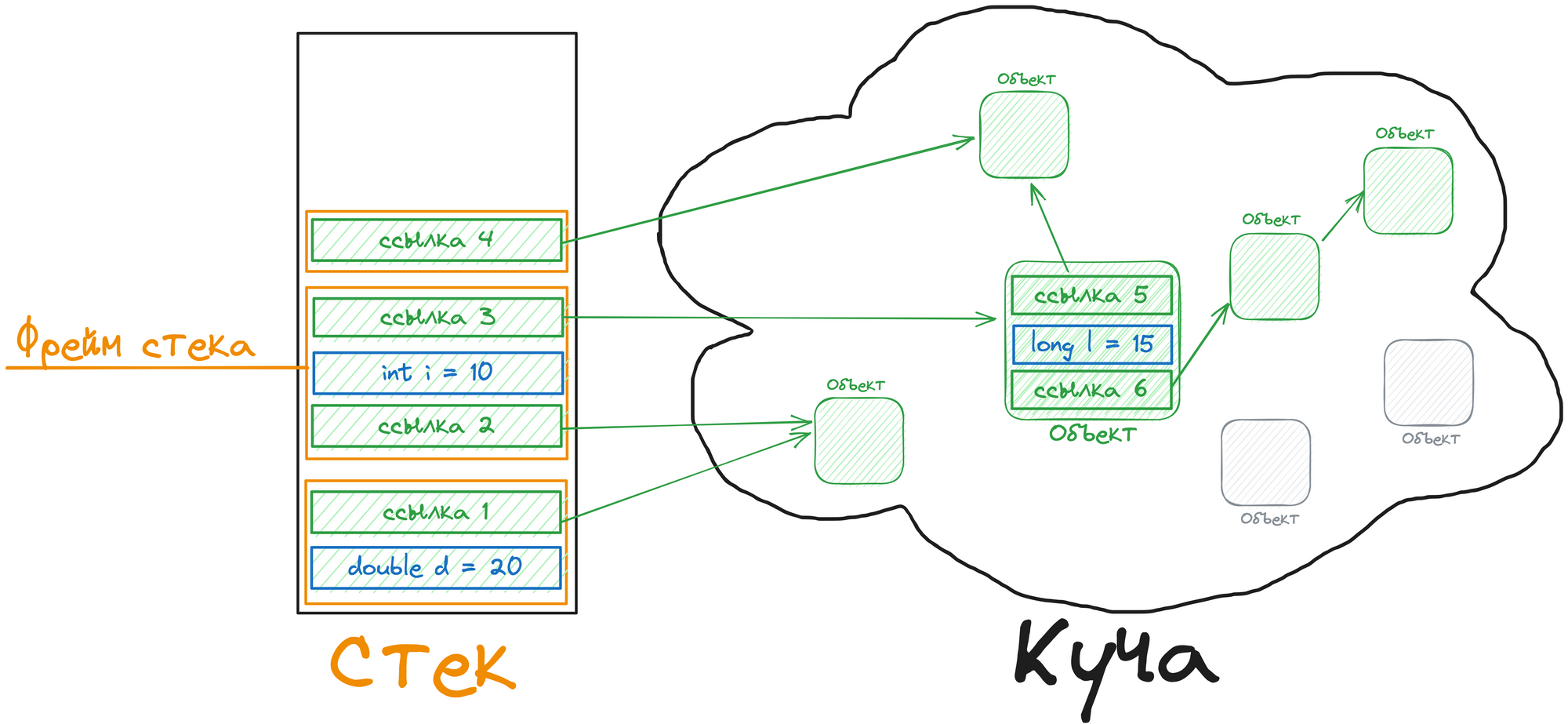
Стек
Когда вызывается функция, для неё выделяется блок памяти на вершине стека. Этот блок, известный как “фрейм стека”, содержит пространство для всех локальных переменных функции, а также информацию, такую как адрес возврата — место в коде, куда программа должна вернуться после завершения функции.
Когда одна функция вызывает другую, для новой функции выделяется собственный фрейм стека, и она становится текущей активной функцией. По завершении работы функции её фрейм стека удаляется, и управление передаётся обратно вызывающей функции.
Так выглядят фреймы стека в режиме дебага в Idea
Особенности работы
- LIFO (Last-In, First-Out): Стек работает по принципу “последним пришёл — первым ушёл”. Это означает, что последняя вызванная функция будет первой, которая завершит работу и вернёт управление.
- Автоматическое управление памятью: Когда функция завершает выполнение, её локальные переменные автоматически удаляются. Это упрощает управление памятью, так как нет необходимости в явном освобождении памяти.
- Ограниченный размер: Размер стека обычно ограничен. Если программа попытается использовать больше памяти, чем доступно в стеке, это приведёт к ошибке переполнения стека.
- Быстрый доступ: Доступ к данным в стеке обычно быстрее, чем к данным в куче, поскольку стек локализован в памяти, и данные из него могут загружаться в кэш процессора для ускоренного доступа.
Куча
Куча — это область памяти, используемая для динамического распределения во время выполнения программы. В отличие от стека, данные в куче могут существовать дольше, чем отдельные вызовы функций, а объёмы памяти, выделяемой в куче, обычно гораздо больше, чем в стеке.
Динамическое управление памятью подразумевает процесс выделения и освобождения памяти в куче во время работы программы. Когда программе требуется память для хранения данных, она может запросить у операционной системы блок памяти в куче, достаточно большой для этих данных.
Однако важно помнить, что, в отличие от стека, память в куче не освобождается автоматически. Когда данные больше не нужны, программа должна явно указать операционной системе, что эту память можно освободить для использования другими процессами. Этот процесс называется “освобождение памяти”.
Если программа продолжает использовать память, не освобождая её, это может привести к “утечке памяти”, когда значительные объёмы памяти заняты данными, которые уже не нужны. Это может вызвать снижение производительности и, в конечном итоге, привести к ошибкам, когда вся доступная память будет исчерпана.
Особенности
- Динамическое распределение памяти: Куча позволяет программе запрашивать необходимый объём памяти динамически и использовать его до тех пор, пока программа не освободит его.
- Долговечность данных: Память в куче не освобождается автоматически, поэтому данные могут существовать до тех пор, пока не будут явно удалены, что позволяет им пережить вызовы функций.
- Управление памятью: Работа с кучей требует тщательного управления памятью. Утечки памяти могут стать проблемой, если память не освобождается своевременно.
- Медленный доступ: Доступ к данным в куче может быть медленнее по сравнению со стеком, из-за более сложного управления и отсутствия локализации данных.
Cтек и куча в Java
Основное отличие стека и кучи в Java от их общего представления связано с автоматическим управлением памятью. В Java не нужно явно освобождать память в куче, так как этим занимается сборщик мусора. Если на объект, на который ссылается локальная переменная, больше нет ссылок, он становится доступным для сборщика мусора.
Пространство стека ограничено и обычно меньше пространства кучи. Если приложение попытается использовать больше стековой памяти, чем доступно, это приведёт к ошибке StackOverflowError.
Куча в Java — это область памяти, где создаются все объекты. Когда вы создаёте объект с помощью оператора new, он размещается в куче.
Сборщик мусора
Сборщик мусора (Garbage Collector, GC) — это процесс в виртуальной машине Java (JVM), который автоматически освобождает память, выделенную для объектов, которые больше не используются. Этот процесс происходит следующим образом:
- Маркировка: Сборщик мусора начинает “маркировать” все объекты в куче, которые больше не доступны из корней приложения. “Корни” обычно включают в себя стек вызова и глобальные ссылки. Если на объект в куче не существует активной ссылки из этих “корней”, он считается недоступным.
- Удаление: После того как недоступные объекты были помечены, сборщик мусора освобождает память, которую они занимали.
Несмотря на автоматизацию управления памятью, неэффективное использование ресурсов может по-прежнему привести к проблемам. Например, если приложение постоянно создаёт новые объекты и сохраняет на них ссылки, это может привести к утечке памяти, когда куча постепенно заполняется, и система больше не может выделить память для новых объектов. В таких случаях приложение может завершиться с ошибкой OutOfMemoryError.
Пример с кодом
Рассмотрим процесс работы с памятью в Java на примере кода:
public class Main {
public static void main(String[] args) {
Person person1 = new Person("John");
Person person2 = new Person("Jane");
System.out.println("Name of person1: " + person1.getName());
System.out.println("Name of person2: " + person2.getName());
swapNames(person1, person2);
System.out.println("After swapping:");
System.out.println("Name of person1: " + person1.getName());
System.out.println("Name of person2: " + person2.getName());
}
public static void swapNames(Person p1, Person p2) {
String temp = p1.getName();
p1.setName(p2.getName());
p2.setName(temp);
}
}В этом примере мы создаём два объекта Person в методе main(). Эти объекты создаются в куче, а ссылки на них (person1 и person2) хранятся в стеке.
Когда вызывается метод swapNames(), происходит следующее:
Создание ссылок в стеке: Ссылки p1 и p2 создаются в стеке как копии ссылок person1 и person2. Они указывают на те же объекты Person, что и оригинальные ссылки. Это возможно благодаря тому, что в Java передача объектов в методы осуществляется по значению ссылок, что позволяет методам изменять состояние объектов, на которые эти ссылки указывают.
Работа с временной переменной: Внутри метода swapNames() создаётся переменная temp для временного хранения имени объекта Person, на который указывает p1. Так как строка — это объект, она хранится в куче, а ссылка на неё — в переменной temp, которая размещена в стеке.
Замена имен: Мы меняем имя объекта, на который указывает p1, на имя объекта p2, а затем меняем имя объекта p2 на значение из переменной temp. Это изменение затрагивает сами объекты, находящиеся в куче.
Жизненный цикл локальных переменных: Память для локальных переменных, включая temp, выделяется при входе в метод. Для метода создаётся новый фрейм стека, содержащий место для всех локальных переменных и параметров. Этот фрейм имеет фиксированный размер, и все локальные переменные “резервируют” своё место при вызове метода, независимо от того, когда именно они инициализируются в теле метода. В нашем случае память для переменной temp выделяется сразу при вызове метода swapNames(), хотя присвоение значения происходит позже, при выполнении строки String temp = p1.getName();.
Завершение работы метода: После завершения работы метода swapNames() локальная переменная temp исчезает, так как она хранилась в стеке, и её жизненный цикл ограничен временем выполнения метода. Однако объекты Person продолжают существовать в куче, пока на них есть ссылки, и они не будут удалены сборщиком мусора.
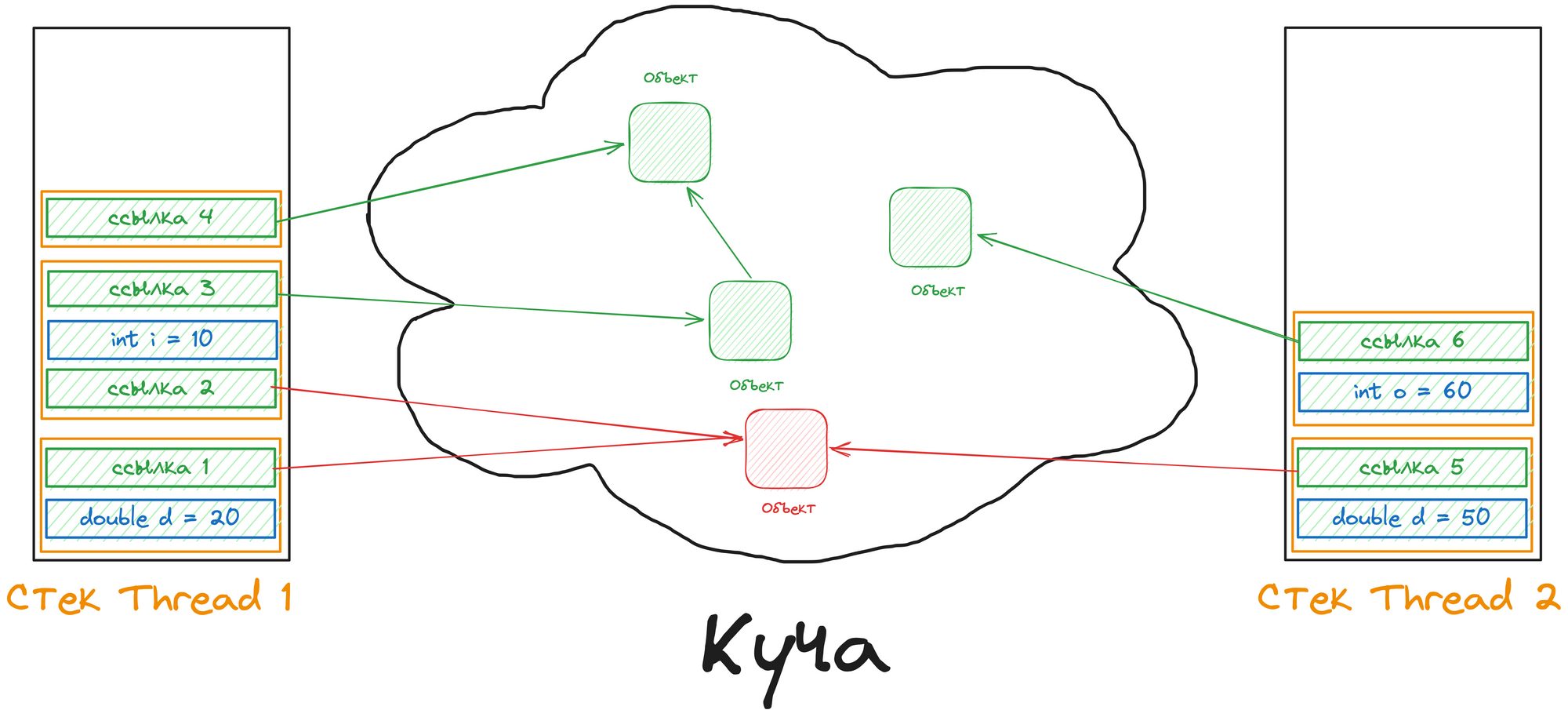
Влияние многопоточности в Java на память
Когда создаётся новый поток, для него выделяется отдельный фрейм стека. Это означает, что каждый поток имеет свой собственный стек вызовов, где хранятся его локальные переменные и ссылки на объекты в куче. Эти стеки изолированы друг от друга, что исключает возможность взаимодействия потоков с локальными переменными друг друга.
Даже если два потока выполняют один и тот же код, они создают свои собственные локальные переменные в отдельных стеках. Таким образом, каждый поток имеет свою версию каждой локальной переменной.
В то же время все потоки совместно используют одну общую кучу, что означает, что объекты, созданные любым потоком, доступны для всех потоков. Это делает особенно важным управление доступом к объектам в куче, чтобы избежать проблем с согласованностью данных и условий гонки.
Для управления доступом нескольких потоков к общим ресурсам используется синхронизация. Она может быть реализована с помощью ключевого слова synchronized или через специальные классы, такие как ReentrantLock или Semaphore.
Сборщик мусора в Java также работает в многопоточной среде и способен обрабатывать объекты из всех потоков. Однако стоит уделять внимание долгоживущим объектам и ресурсам, которые могут блокировать работу сборщика мусора, ухудшая производительность системы.

Заключение
В программировании стек и куча выполняют разные, но одинаково важные функции. Стек используется для хранения информации о вызовах функций и их локальных переменных, а куча — для динамического выделения памяти.
В Java управление памятью становится особенно интересным благодаря автоматической сборке мусора, которая освобождает неиспользуемую память, и разделению на области Heap Space и Stack Space. Эти механизмы делают Java удобной для разработки, однако требуют внимательного подхода к управлению памятью, чтобы избежать проблем с производительностью.
Таким образом, управление памятью — это сложная, но важная часть работы с программным обеспечением. Понимание основ этих процессов помогает разработчикам создавать более эффективные и надёжные приложения.
