
В современном мире разработки, где требования к производительности и отзывчивости системы становятся все более строгими, реактивное программирование выделяется как ключевой подход.
Что же такое реактивное программирование, и почему оно становится всё более популярным? В чём недостаток императивного подхода? И, что самое важное, как реактивные потоки помогают нам создавать более производительные и эффективные системы?
Реактивная система
Так как реактивный подход помогает создавать реактивные системы, неплохо сначала разобраться, что это за системы такие.
Представим себе систему управления таксопарка. Владелец таксопарка идёт в ногу со временем и решил заказать разработку системы для управления заказами. Система включает в себя множество подсистем: работа с заказами, управлением автопарком и так далее.
Перед разработкой владелец подсчитал среднее количество заказов в день, аналитики по этим данным рассчитали необходимое количество железа, заложили в эти данные избыток в 50% на будущий рост и закупили сервера. Система была написана и введена в эксплуатацию.
Всё было хорошо, пока в городе не объявили проведение чемпионата мира по футболу. Толпы туристов, многие из которых решили воспользоваться удобным способом заказа такси. В какой-то момент нагрузка превзошла все самые смелые ожидания и система полностью развалилась. В итоге таксопарк потерял клиентов и прибыль, а его рейтинг в AppStore обвалился.
Кажется, что было бы неплохо, чтобы система как-то динамически реагировала на изменения, будь то резко выросшая нагрузка или недоступность внешних служб.
В этом примере стоит задуматься об увеличении эластичности. Пропускная способность вашей системы должна автоматически увеличиваться при увеличении нагрузки, и автоматически уменьшаться со снижением нагрузки.
Это одно из свойств, которыми должна обладать реактивная система. Поговорим обо всех характеристиках.
Отзывчивость
Система способна быстро обрабатывать запросы пользователей даже при высокой нагрузке. Это требует соблюдения нескольких ключевых принципов проектирования.
Неблокирующий ввод/вывод: Использование неблокирующего ввода-вывода, позволит минимизировать время, которое потоки тратят на ожидание завершения операций ввода-вывода. Более эффективное использование потоков снижает вероятность "голодания" потоков и увеличивает производительность сервиса.
Про неблокирующий ввод/вывод я расскажу ниже более подробно.
Балансировка нагрузки гарантирует, что ни один экземпляр не будет перегружен трафиком. Таким образом увеличивая пропускную способность и производительность системы.
Существуют различные алгоритмы распределения запросов, но их цель одна: распределить запросы равномерно на существующие и работоспособные экземпляры системы.
Кэширование: система должна использовать методы кэширования для сокращения времени, затрачиваемого на обработку запросов, и повышения общей производительности системы.
Допустим, у вас есть сервис справочников, который содержит значения для различных списков: статусы заказа, названия категорий товаров. Нет смысла каждый раз обращаться в сервис справочной информации, если данные там меняются нечасто. Кэширование этой информации позволит снизить затраты на межсервисное взаимодействие, а также позволит сервису продолжить работу, даже если сервис справочников будет недоступен.
Для больших систем отличным решением будет использование CDN для кэширования статического контента и снижения сетевых задержек.
Устойчивость
Система должна продолжать работать во время сбоев и автоматически восстанавливаться после ошибок, а не полностью выходить из строя.
Существует несколько ключевых стратегий, которые могут помочь обеспечить устойчивость:
Отказоустойчивость: Реактивная система должна быть спроектирована таким образом, чтобы выдерживать сбои на всех уровнях, включая аппаратные, сетевые и программные сбои. Это может быть достигнуто благодаря избыточности, репликации и механизмов автоматического распределения нагрузки с отказавших экземпляров сервисов на здоровые экземпляры.
Автоматическое восстановление: Реактивная система должна уметь автоматически обнаруживать и диагностировать ошибки, а также предпринимать корректирующие действия для восстановления после сбоев без вмешательства разработчиков.
Вынужденная деградация (Graceful degradation): Система должна продолжать работать, даже если некоторые её компоненты или функции недоступны или работают неправильно.
Вместо того чтобы полностью разрушиться, система плавно деградирует, отключая несущественные функции, снижая функциональность или предоставляя запасные варианты. Это позволяет системе продолжать работать, хотя и с ограниченными возможностями, пока проблема не будет устранена.
Предохранители (Circuit breakers): Модель проектирования, которая может помочь предотвратить каскадные отказы в системе. Работает путём мониторинга количества отказов, происходящих в сервисе за определённый период времени, и автоматически отключает предохранитель, если количество отказов превышает заданный порог.
Можно реализовать различные предохранители. Например, если сервис не отвечает на запрос, начать возвращать дефолтное значение или кэшированное значение. Все зависит от ваших сценариев.
Контроль потока данных (Backpressure): Механизм, позволяющий получателю управлять скоростью получения данных от отправителя. Иными словами, это метод контроля потока информации между отправителем и получателем.
Включив эти стратегии в конструкцию реактивной системы, можно достичь высокого уровня устойчивости и гарантировать, что система способна быстро восстанавливаться после ошибок и продолжать бесперебойную работу.
Эластичность
Реактивная система должна иметь возможность масштабирования для обработки растущих рабочих нагрузок без снижения производительности и доступности.
Существует несколько методов, которые могут быть использованы для достижения эластичности в реактивной системе:
Горизонтальное масштабирование: Предполагает добавление дополнительных экземпляров сервиса для распределения рабочей нагрузки на несколько машин или узлов.
Этот подход может использоваться для обработки растущего трафика или запросов пользователей и может быть достигнут при использовании технологий контейнеризации, таких как Docker, и инструментов оркестрации, таких как Kubernetes.
Вертикальное масштабирование: Предполагает добавление дополнительных ресурсов (процессор, память или дисковое пространство) к существующему сервису для увеличения его мощности.
Этот подход может быть использован для обработки возросших объёмов данных или требований к обработке, и может быть реализован с помощью облачных инфраструктурных сервисов, таких как Amazon EC2 или Microsoft Azure.
Автомасштабирование: Предполагает использование автоматизированных инструментов или алгоритмов для динамической корректировки количества экземпляров или ресурсов, выделяемых сервису, на основе показателей, собираемых в реальном времени, таких как использование процессора, памяти или сетевого трафика.
Динамическая корректировка может увеличить количество экземпляров сервиса при увеличении количества запросов, а также уменьшить количество экземпляров при уменьшении нагрузки. Увеличение позволяет обработать непредсказуемый рост нагрузки, а уменьшение позволяет эффективнее потреблять доступные ресурсы и не платить накладные расхода за не используемые.
Достижение эластичности в реактивной системе требует сочетания архитектурного проектирования, управления инфраструктурой и инструментов автоматического масштабирования для обеспечения того, чтобы система могла адаптироваться к изменяющимся рабочим нагрузкам и поддерживать свою производительность и доступность в течение долгого времени.
Управление сообщениями
Message Driven — шаблон проектирования, используемый в реактивных системах для обеспечения асинхронной связи между различными компонентами. Этот паттерн позволяет сервисам отправлять и получать сообщения без блокировки, ожидания или удержания ресурсов, что помогает минимизировать потребление ресурсов и максимизировать пропускную способность.
Для обеспечения коммуникации на основе сообщений реактивные системы обычно используют брокер сообщений или очередь сообщений, которая выступает в качестве посредника между различными сервисами. Когда сервис посылает сообщение другому сервису, он помещает его в очередь сообщений, а принимающий компонент может получить сообщение асинхронно, когда он будет готов обработать его.
Такой подход позволяет сервисам работать независимо друг от друга, без необходимости знать о состоянии или доступности других сервисов. Он также позволяет сервисам обрабатывать большие объёмы сообщений или событий, не перегружаясь и не блокируясь входящим трафиком.
Реактивное программирование
Манифест реактивных систем гласит: "Большие системы состоят из подсистем, имеющих те же свойства и, следовательно, зависят от их реактивных характеристик. Это означает, что принципы Реактивных Систем применяются на всех уровнях." Таким образом, каждый отдельный сервис должен также следовать принципам реактивной системы.
Реактивное программирование — это парадигма программирования, ориентированная на работу с потоками данных и распространение изменений в этих потоках. Какие-то данные поступают в систему, и как реакция на них, система выполняет какие-то действия. Вот отсюда и название — «реактивное».
Хотя реактивное программирование часто используется для создания реактивных систем, технически возможно достичь определённой степени реактивности системы, используя другие методы программирования, такие как многопоточность, асинхронное программирование и событийно-ориентированные архитектуры. Эти методы могут помочь улучшить отзывчивость и масштабируемость системы, но они могут не обеспечить тот уровень устойчивости и отказоустойчивости, который призваны обеспечить реактивные системы.
Проблемы императивного программирования
Разберёмся в недостатках императивного подхода. Зачем понадобилось выдумывать какое-то реактивное программирование, почему сложно написать реактивную систему на существующих технологиях?
Реализуем небольшой пример, который состоит из двух сервисов.
@Service
@RequiredArgsConstructor
public class PassengerServiceImpl implements PassengerService {
private final RideService rideService;
@Override
public void requestRide(Location pickupLocation, Location dropoffLocation) {
RideRequest rideRequest = new RideRequest(pickupLocation, dropoffLocation);
Ride ride = rideService.processRideRequest(rideRequest);
// other logic
}
}PassengerServiceImpl представляет API для запроса поездки, ориентированный на пассажира. Метод requestRide() принимает в качестве параметров место посадки и высадки пассажира и инициирует процесс запроса поездки.
@Service
@RequiredArgsConstructor
public class RideServiceImpl implements RideService {
private final DriverService driverService;
@Override
public Ride processRideRequest(RideRequest rideRequest) {
Driver driver = driverService.findAvailableDriver(rideRequest.getPickupLocation());
// other logic
Ride ride = new ...
return ride;
}
}RideServiceImpl представляет внутреннюю службу, которая обрабатывает запросы на поездки. Метод processRideRequest() принимает объект RideRequest в качестве параметра и инициирует процесс поиска водителя и назначения поездки.
Представим, что DriverService при вызове метода findAvailableDriver() обращается к базе данных или посылает сетевой запрос в другой сервис. Что будет, если БД будет выполнять запрос 30 секунд или другой сервис ответит спустя 5 минут?
Одна из основных проблем императивного подхода это ожидание потоков выполнения какой-либо задачи, то есть блокировка. Например, для выполнения запроса к БД из пула потоков берётся поток, далее он ожидает , пока БД выполнит запрос и вернёт результат. Если вычисление результата займёт 5 минут, то поток всё это время будет недоступен для других операций.
Это может привести к снижению производительности сервиса, особенно если многие потоки будут блокироваться в ожидании завершения долго выполняющихся запросов к базе данных. В какой-то момент у вас просто могут закончиться потоки в пуле, и обработка новых запросов просто остановится.
Такая же проблема может возникнуть, когда выполняется запрос к внешнему сервису. Например, вы посылаете запрос используя RestTemplate. Если внешний ресурс будет отвечать 5 минут, то всё это время поток будет находится в ожидании ответа, то есть простаивать.
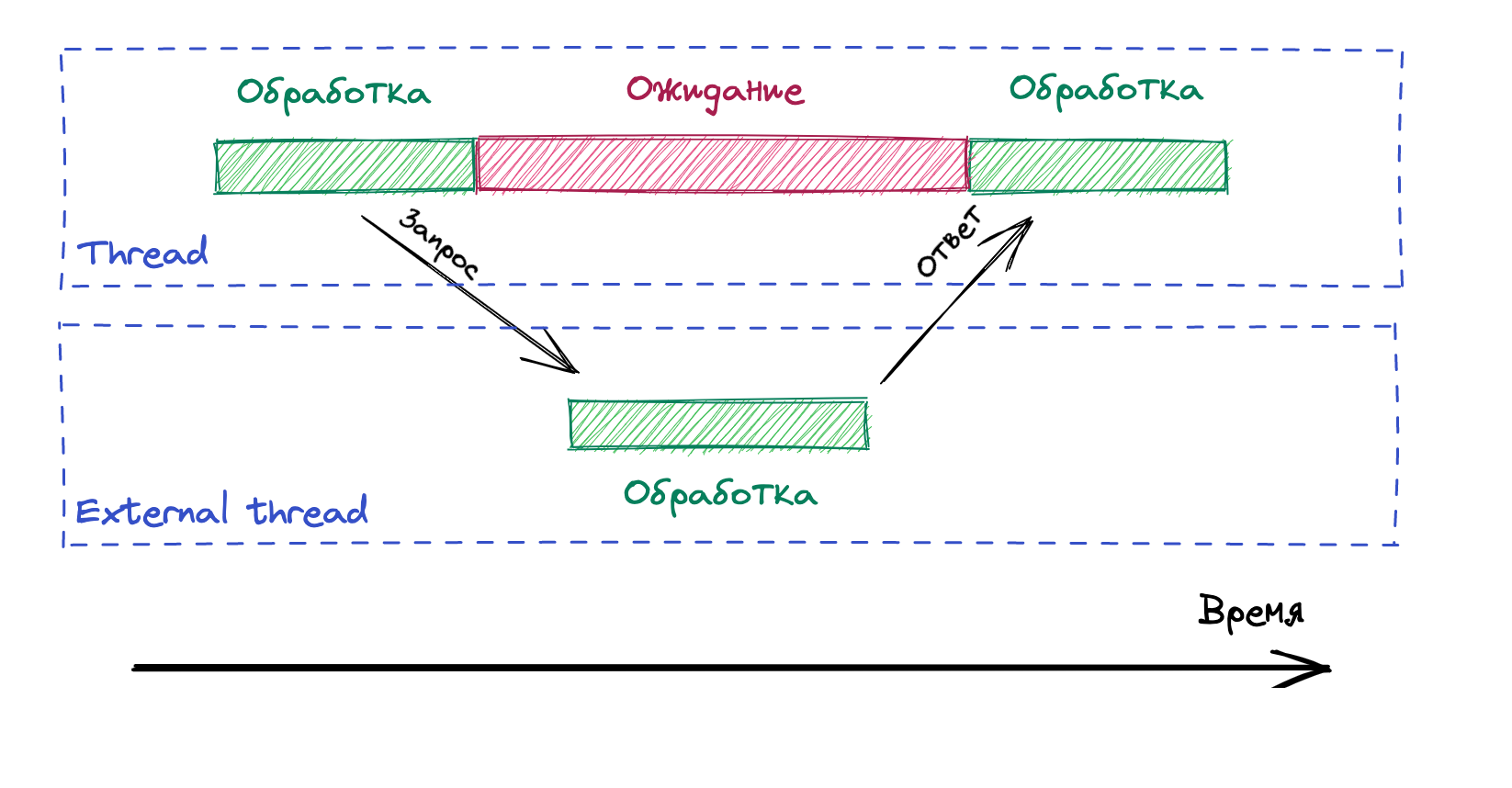
Почему простаивание потока — это проблема?
Каждый поток нуждается в памяти для хранения своего стека вызовов и других связанных с ним структур данных. Когда поток простаивает, он продолжает потреблять ресурсы для поддержания своего состояния.
Кроме того, процессорное время, которое выделяется неработающим потокам, могло бы быть использовано для других задач. Если большое количество потоков простаивает, это может привести к увеличению загрузки процессора и снижению производительности, так как операционная система будет тратить больше времени на переключение между потоками.
Попробуем решить проблему блокировки потоков доступными способами. Добавим ExecutorService в RideService и будем возвращать не Ride, а Future<Ride>.
public inteface RideService {
public Future<Ride> processRideRequest(RideRequest rideRequest);
}@Service
public class PassengerServiceImpl implements PassengerService {
private final RideService rideService;
@Override
public void requestRide(Location pickupLocation, Location dropoffLocation) {
RideRequest rideRequest = new RideRequest(pickupLocation, dropoffLocation);
Future<Ride> future = rideService.processRideRequest(rideRequest);
// other logic
Ride ride = future.get();
// other logic
}
}Теперь мы выполняем асинхронный вызов к RideService и получаем объект Future. Далее мы можем продолжить выполнять другие операции, пока выполняется обработка Future.
Мы можем выполнить какую-то другую логику, но в какой-то момент необходимо вызывать метод Future.get(), который потенциально также является блокирующим, если Future ещё не закончил работу, то мы заблокируем поток.
Эта реализация позволила нам сократить время блокировки потока, однако полностью эта проблема не решена, мы всё ещё с большой вероятностью будем получать блокировку потока.
Более высокоуровневым решением может быть использование CompletionStage и его реализации CompletableFuture. CompletionStage позволяет писать код в функциональном стиле, который выполняется асинхронно.
public inteface RideService {
public CompletionStage<Ride> processRideRequest(RideRequest rideRequest);
}@Service
public class PassengerServiceImpl implements PassengerService {
private final RideService rideService;
public PassengerServiceImpl(RideService rideService) {
this.rideService = rideService;
}
@Override
public void requestRide(Location pickupLocation, Location dropoffLocation) {
RideRequest rideRequest = new RideRequest(pickupLocation, dropoffLocation);
rideService.processRideRequest(rideRequest)
.thenApply(a -> { ... })
.thenCombine(b -> { ... })
.thenAccept(c -> { ... })
}
}Однако, реализации с использованием Future, CompletionStage и им подобных требуют от разработчика глубокого понимания многопоточного программирования: доступ к общей памяти, синхронизация, обработка ошибок и так далее.
Но и это ещё не всё. Дизайн многопоточности в Java не предполагает, что мы будем создавать поток на каждый чих. Создание потока дорогостоящая операция. Да, пул потоков частично решает эту проблему, но есть ещё одна проблема: несколько потоков могут использовать один процессор для выполнения задач одновременно. При такой ситуации, процессорное время распределяется между несколькими потоками, что вызывает необходимость переключения контекста. Для возобновления выполнения потока позже, необходимо сохранять и загружать регистры, карты памяти и выполнить другие операции с высоким объёмом вычислений. Из-за этого снижается эффект от использования большого количества потоков при небольшом количестве процессоров.
Паттерн Наблюдатель (Observer Pattern)
Вспомним паттерн "Наблюдатель". Он поможет нам лучше понять концепцию реактивных потоков.
В этом паттерне есть два ключевых участника: Издатель и Подписчик (Наблюдатель). Издатель обновляет состояние и оповещает всех своих подписчиков об этих изменениях. Подписчики, в свою очередь, реагируют на эти уведомления.
Ключевые характеристики
- Декаплинг: Субъекты и наблюдатели функционируют независимо друг от друга. Это означает, что они не должны знать друг о друге. Субъекты просто отправляют уведомления, а наблюдатели просто реагируют на них.
- Динамичность: Подписчики могут подписываться и отписываться от субъектов в любое время.
- Многопоточность: Паттерн Наблюдатель позволяет обрабатывать события асинхронно и в различных потоках исполнения.
В контексте реактивного программирования паттерн Наблюдатель становится основой для создания реактивных потоков, обеспечивающих эффективную обработку данных и событий. Это также служит фундаментом для различных библиотек и фреймворков, таких как RxJava и Project Reactor.
Реактивные потоки (стримы)
Спецификация Reactive Streams впервые была опубликована в 2015 году. Она была разработана для стандартизации модели асинхронного потокового программирования с контролем потока данных в JVM и была принята в качестве основы для обработки асинхронного потока в JDK 9.
В отличие от обычных Java Stream не было предоставлено стандартных реализаций реактивных стримов, поэтому в последующие годы в Java-сообществе появилось несколько библиотек и фреймворков, которые реализуют и расширяют спецификацию Reactive Streams, таких как: RxJava, Vert.x, ProjectReactor, Akka Streams.
Базовая схема работы стримов
Продолжая историю с паттерном Наблюдатель, теперь у нас есть интерфейсы Publisher, представляет источник данных, и Subscriber — наблюдатель, который подписывается на поток и получает уведомления об изменении состояния потока. Есть ещё один важный интерфейс, который является «посредником» между первыми двумя - это Subscription.
Давайте взглянем, как выглядят данные интерфейсы:
package org.reactivestreams;
public interface Publisher<T> {
public void subscribe(Subscriber<? super T> s);
}package org.reactivestreams;
public interface Subscriber<T> {
public void onSubscribe(Subscription s);
public void onNext(T t);
public void onError(Throwable t);
public void onComplete();
}package org.reactivestreams;
public interface Subscription {
public void request(long n);
public void cancel();
}Все начинается с подписки Subscriber на Publisher посредством вызова метода Publisher.subscribe(). Publisher использует переданный объект Subscriber, вызывая метод onSubscribe(), передавая в Subscriber объект Subscription. Через этот объект Subscriber будет взаимодействовать с Publisher.
Теперь Subscriber, используя полученный Subscription, будет запрашивать значения у Publisher. Это важный момент, не Publisher инициализирует отправку данных подписчикам когда хочет, это подписчики запрашивают необходимое количество данных у Publisher. Таким образом реализуется контроль потока данных (Backpressure).
Метод onNext(T t) вызывается, когда Subcriber запрашивает значения у Publisher, используя метод Subscription.request(). Он передаёт данные по одному, но не больше, чем было запрошено подписчиком.
Метод onError() вызывается, когда ошибка происходит на стороне Publisher, оповещая таким образом о проблеме Subscriber, передавая объект исключения.
Метод onComplete() оповещает подписчиков, что у Publisher не осталось элементов для передачи. Данный метод, как и onError() вызывается лишь один раз.
Пример реактивного потока
Представим, что у нас есть набор чисел, и мы хотим получить квадрат каждого числа. При этом числа для расчёта могут поступать из разных систем или из бд, или из БД редиса и других систем.
В императивном стиле программирования мы бы обработали эти данные следующим образом:
List<Integer> numbers = externalServices.getNumbers();
for (int number : numbers) {
int square = number * number;
System.out.println(square);
}Код обрабатывает данные в определённом порядке и от начала до конца. Мы должны дождаться пока метод getNumbers() отправит нам все данные для расчёта.
Давайте рассмотрим тот же пример с использованием Project Reactor:
Flux<Integer> numbers = externalServices.getNumber(); // Flux это реализация Publisher
numbers
.map(number -> number * number)
.subscribe(
data -> System.out.println("Получены данные: " + data),
error -> System.out.println("Произошла ошибка: " + error),
() -> System.out.println("Поток данных завершен")
);Этот код напоминает Stream API. Только вместо Stream<T> используется Flux — это тип данных из Project Reactor, который представляет собой поток данных.
Мы используем метод map, чтобы преобразовать каждое число в его квадрат, и затем подписываемся на поток, чтобы вывести результат. Подписка очень важна, без неё ничего не произойдёт. Только в отличие от Stream API на Flux можно подписаться несколько раз.
В данном примере мы будем обрабатывать данные асинхронно по мере их поступления. Одна система ответила быстрее другой, сразу обработали эту часть данных.
Ограничения и недостатки
Не бывает идеального решения и реактивные потоки не исключение.
Чтобы получить преимущество реактивных потоков, весь стек должен быть реактивным: доступ к БД, операции чтения/записи файлов и так далее. Всё должно работать в реактивной парадигме, иначе вы получите блокировки, которые ухудшат производительность всей системы.
Например, стандартный JDBC не является реактивным. Если использовать его в реактивном сервисе, то придётся ждать ответ, когда мы отправляем запрос в базу данных. Соответственно, вся реактивность тут же ломается.
Весь технологический стек должен быть реактивным
Сложность: Реактивное программирование может быть сложным для понимания, особенно для новичков. Это связано с необходимостью работы с асинхронностью, обработкой ошибок и механизмами подобными backpressure.
Отладка и тестирование: Отладка и тестирование реактивных систем сложная задача, так как асинхронная природа реактивного кода делает отслеживание исполнения программы менее прямолинейным и понятным.
Требования к проектированию: Реактивные системы требуют продуманного проектирования, чтобы обеспечить их эффективность. Без правильного проектирования система может столкнуться с проблемами производительности или недостаточной отзывчивости.
Event Loop
Рассуждая на тему реактивного программирования, нельзя пройти мимо такого понятия, как Event Loop.
Это реактивная асинхронная модель программирования для серверов. Она позволяет достичь более высокого уровня параллелизма при меньшем количестве потоков.
По сути, Event Loop - это реализация шаблона Reactor. Является неблокирующим потоком ввода-вывода, который работает непрерывно. Его основная задача — проверка новых событий. И как только событие пришло перенаправлять его тому, кто в данный момент может его обработать. Иногда их может быть несколько для увеличения производительности.
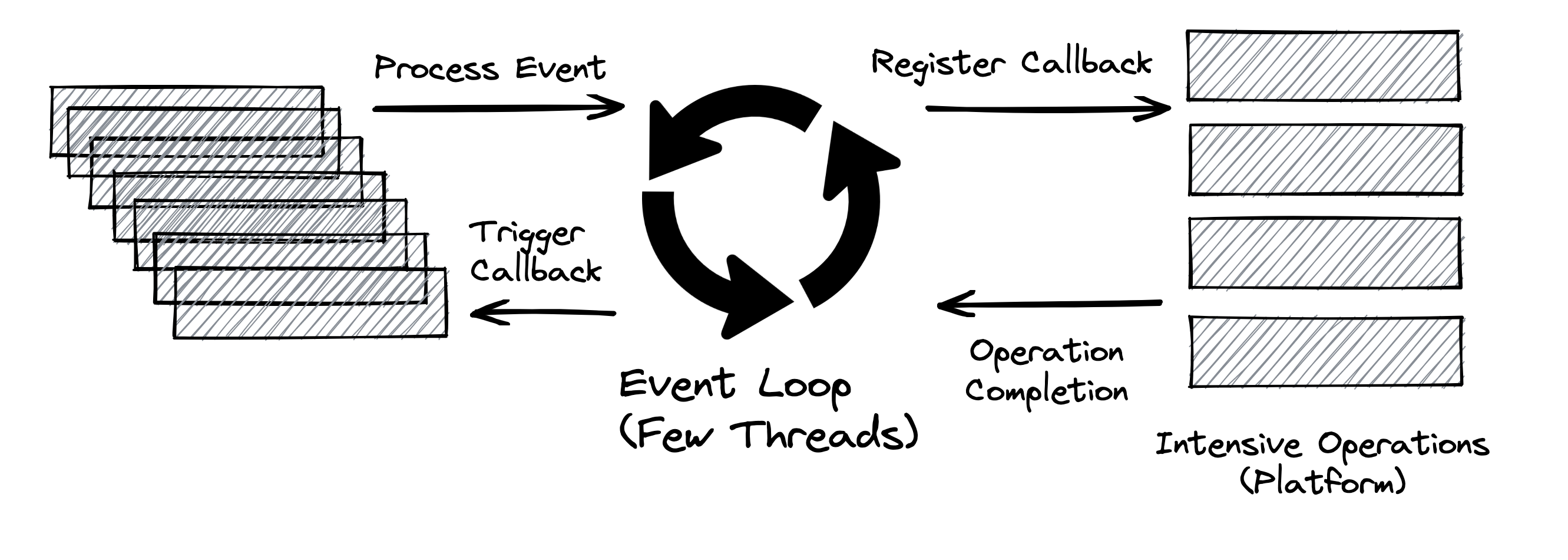
Выше приведён абстрактный дизайн цикла событий, который представляет идеи реактивного асинхронного программирования:
- Цикл событий выполняется непрерывно в одном потоке, хотя у нас может быть столько циклов событий, сколько доступно ядер.
- Цикл событий последовательно обрабатывает события из очереди событий и возвращается сразу после регистрации обратного вызова в платформе.
- Платформа может инициировать завершение операции, такой как вызов базы данных или вызов внешней службы.
- Цикл событий может запускать обратный вызов при уведомлении о завершении операции и отправлять результат обратно исходному вызывающему.
В своей работе механизм Event Loop использует Netty - клиент-серверная среда ввода-вывода для разработки сетевых приложений Java. Также этот механизм использует Vert.x – это полифункциональная библиотека для построения реактивных приложений на JVM.
Реактивные фреймворки в Java
Теперь немного поговорим про имплементации реактивной спецификации, коих уже появилось достаточное количество.
Spring WebFlux (Project Reactor)
Project Reactor – это библиотека для реактивного программирования на Java, которая полностью поддерживает Reactive Streams. Она предлагает два основных типа данных – Flux и Mono.
Flux представляет поток ноль или более элементов, а Mono представляет один или ноль элементов. Оба типа предоставляют обширный набор операторов для трансформации и комбинирования этих потоков.
Spring WebFlux – это веб-фреймворк, который является частью экосистемы Spring и использует Project Reactor для обработки реактивных потоков. В отличие от Spring MVC, который предназначен для синхронного веб-программирования и блокирования I/O, Spring WebFlux предназначен для асинхронного и неблокирующего веб-программирования.
Вместо Tomcat используется неблокирующий Netty. Сервлеты тоже ушли в прошлое.

Quarkus (Vert.x)
Не спрингом единым. Активно использую его в работе и в пет-проектах.
Реактивное программирование в Quarkus основано на библиотеке SmallRye Mutiny. Mutiny предлагает два основных типа: Uni и Multi, которые представляют собой типы реактивных потоков, обеспечивающих обработку одного или множества элементов соответственно.
Множество знакомых коллег, которым довелось поработать и со Spring WebFlux и с Quarkus, отмечают, что реактивный Quarkus API более приятный для работы.
Quarkus также оптимизирован для работы в контейнеризированных средах и облачных приложениях, что, в сочетании с его реактивной моделью программирования, делает его отличным выбором для создания современных микросервисов.
Кроме того, Quarkus предоставляет возможность компиляции приложений в нативный код при помощи GraalVM, что позволяет уменьшить время запуска и использование памяти, что является ещё одним преимуществом при использовании в облачных средах.
Project Loom
Некоторые разработчики предрекают скорую смерть таким проектам, как Project Reactor, ведь уже близится релиз Project Loom. Давайте порассуждаем на эту тему.
Цель Project Loom добавить в Java так называемые виртуальные потоки или нити (fibers). Одной из ключевых особенностей виртуальных потоков является их "непрерывность". Виртуальный поток может быть приостановлен, а его ресурсы могут быть возвращены в пул потоков, что позволяет использовать поток операционной системы для другой работы. Когда придёт ответ от внешнего сервиса, виртуальный поток может быть возобновлен и продолжить свою работу.
Хотя такие реактивные библиотеки предоставляют мощные абстракции для управления асинхронным и неблокирующим кодом, они всё ещё полагаются на традиционную модель потоков Java, которая может быть сложной и трудной для понимания. С Project Loom разработчики получат более простой способ написания неблокирующего кода, без необходимости использования сложных абстракций или пулов потоков.
Однако, на данный момент Project Loom находится в разработке, а вот реактивные фреймворки уже есть и успешно используются.
Вот аргументы, почему существующие фреймворки останутся в строю:
- Project Loom находится в разработке, и его окончательная форма и влияние на экосистему Java не полностью понятны.
- Ничто не мешает реактивным фреймворкам использовать под капотом новые виртуальные потоки. Предоставляя мощные абстракции и API для работы.
- Когда требуется тип обработки в стиле событий (Event-Driven Architecture), то их API очень удобен, странно от него отказываться.
Рекомендую посмотреть следующие доклады на тему Project Loom:
- Иван Углянский — Thread Wars: проект Loom наносит ответный удар
- Олег Докука, Андрей Родионов — Project Loom — друг или враг Reactive?
Заключение
Мы разобрались, что такое реактивные системы, и какими свойствами система должна обладать, чтобы называться реактивной. Разработка реактивной системы - сложный процесс и очевидно, что не каждой системе необходимо быть реактивной.
Однако, системы написанные с применением реактивных подходов и реактивного стека позволяют выдерживать большую нагрузку, чем системы, написанные на стандартном императивном стеке, а также быть более эффективными с точки зрения потребления ресурсов системы и дальнейшего её масштабирования.
Создать реактивную систему проще всего с помощью реактивных фремворков, которые позволяют не блокировать потоки и обрабатывать данные по мере их поступления.
Дополнительные материалы
- Зачем нам Reactive и как его готовить. Команда разработки делится своим опытом перевода сервисов на реактивный стек. Они используют Spring WebFlux.
