
В предыдущих статьях мы разобрались с постраничной пагинацией в SpringBoot, а также узнали, почемупагинация с использованием OFFSET и LIMIT не всегда удачное решение, и возможно стоит подумать про KeySetPagination. А теперь пришло время поговорить про постраничную пагинацию в Quarkus.
Напомню, что цель пагинации — избежать выборки больших объёмов данных. Нет смысла отдавать 100 элементов, если пользователь посмотрит всего 10. Также для постраничной пагинации фронту необходима метаинформация о страницах: номер текущей страницы, количество всех страниц и так далее.
Проблема у Quarkus в том, что там нет аналогов класса Page<T>, который мы использовали в SpringBoot. Но интерфейсы PanacheRepositoryBase и PanacheRepository очень похожи на JpaRepository. Посмотрим, какие методы они нам предоставляют.
Вы быстро найдёте метод findAll() и его перегрузки.

Но findAll() не возвращает результат. Вместо этого он возвращает билдер запроса — PanacheQuery. И у этого билдера есть метод page(int, int), который добавит в SQL запрос операторы OFFSET и LIMIT.
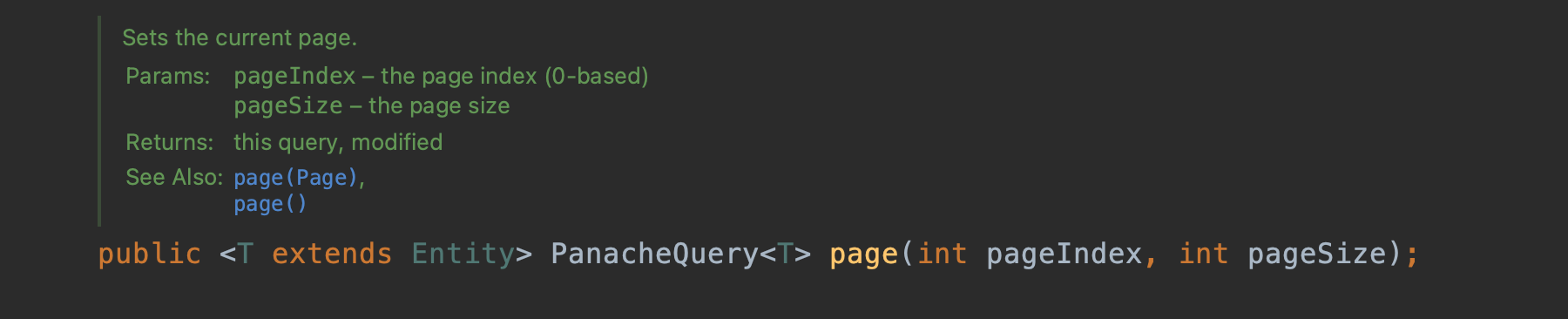
Кажется, мы довольно близки. Но это всё ещё не результирующий объект, а PanacheQuery. Продолжаем собирать свой запрос. Какие ещё методы имеются у PanacheQuery:
list()— вернёт текущую страницу в форматеList;count()— вернёт количество элементов;pageCount()— вернёт общее количество страниц;hasNextPage()— вернёт true, если существует следующая страница;hasPreviousPage()вернёт true, если существует предыдущая страница.
Все эти методы выглядят полезными для решения нашей задачи. Но прежде чем мы продолжим, давайте создадим свой класс Page<T> по образу и подобию Spring-а.
@Getter
@Setter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Page<T> {
private Integer totalPages;
private Long totalElements;
private Integer pageSize;
private Integer pageCount;
private boolean nextPage;
private boolean prevPage;
private List<T> content;
}Собрав все наши наработки, получим вот такое решение:
@Path("/api/post")
@RequiredArgsConstructor
public class PostController {
private final PostRepository repository;
@GET
@Produces(MediaType.APPLICATION_JSON)
public Uni<Page<Post>> getAll(
@QueryParam("offset") Integer offset,
@QueryParam("limit") Integer limit
) {
final PanacheQuery<Post> pageQuery = repository.findAll().page(offset, limit);
return Uni.combine().all().unis(
pageQuery.list(),
pageQuery.count(),
pageQuery.pageCount(),
pageQuery.hasNextPage(),
Uni.createFrom().item(pageQuery.hasPreviousPage())
).asTuple().onItem().transform(
t -> {
final List<Post> content = t.getItem1();
final Long totalElements = t.getItem2();
final Integer totalPages = t.getItem3();
final Boolean hasNextPage = t.getItem4();
final Boolean hasPrevPage = t.getItem5();
return Page.<Post>builder()
.content(content)
.totalElements(totalElements)
.totalPages(totalPages)
.pageCount(offset)
.pageSize(limit)
.nextPage(hasNextPage)
.prevPage(hasPrevPage)
.build();
}
);
}
}В 15 строке мы получаем PanacheQuery. Нам необходимо собрать результаты работы каждого метода запроса с помощью Uni.combine().all(), так как каждый метод возвращает Uni. Кроме hasPreviousPage(), его наоборот приходится упаковывать в Uni.
Запустим приложение и проверим работу пагинации:
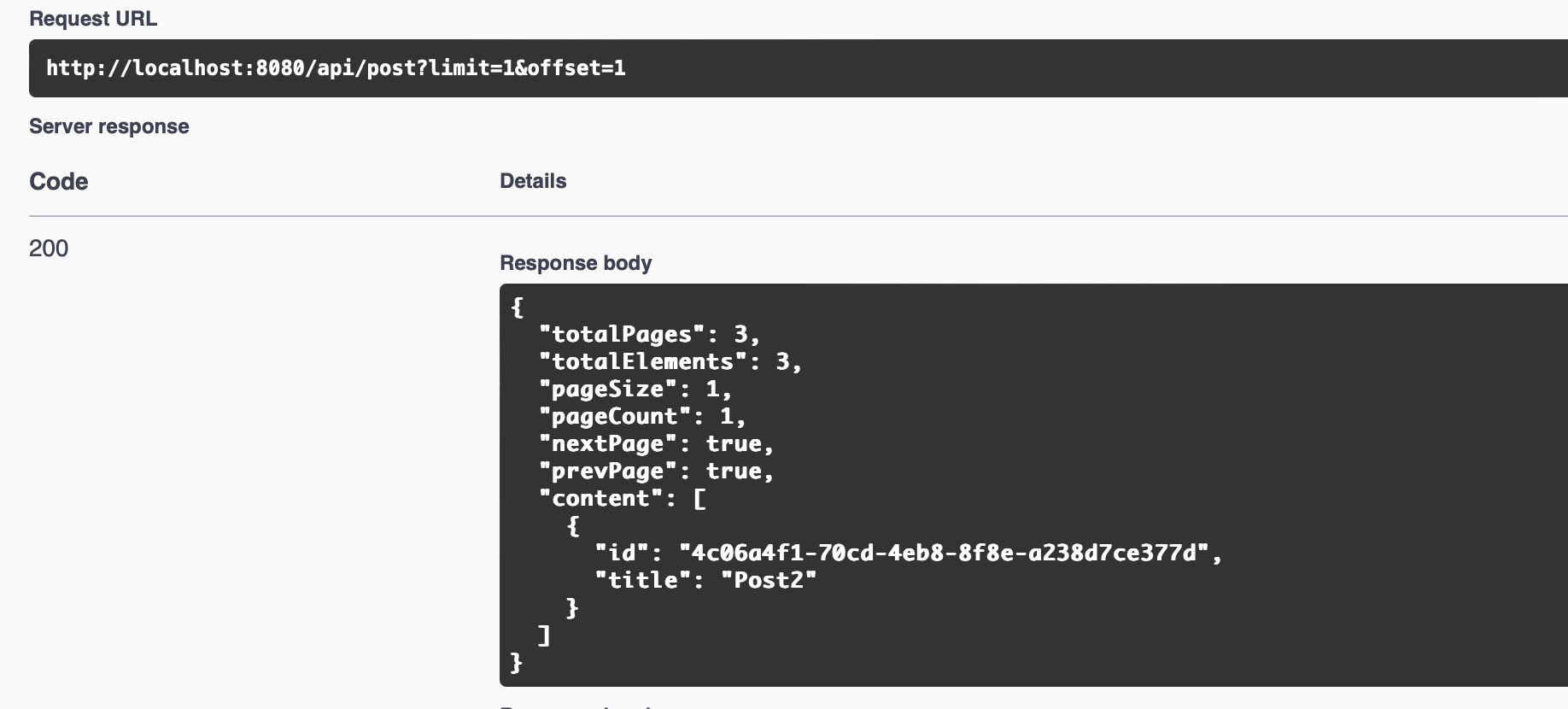
Отлично, всё работает. Но теперь изучите реализацию внимательнее. Ничего не настораживает? Включим логирование sql запросов, которые генерирует Hibernate, и посмотрим, что там происходит:
Hibernate:
select
post0_.id as id1_0_,
post0_.title as title2_0_
from
post post0_ limit $1 offset $2
Hibernate:
select
count(*) as col_0_0_
from
post post0_
Hibernate:
select
count(*) as col_0_0_
from
post post0_
Hibernate:
select
count(*) as col_0_0_
from
post post0_Первые 2 запроса такие же, как и у Spring. Но есть ещё 2 лишних запроса на количество элементов. Если мы зайдём в реализацию методов count(), pageCount(), hasNextPage(), то увидим, что каждый из этих методов вызывает SELECT count(*).
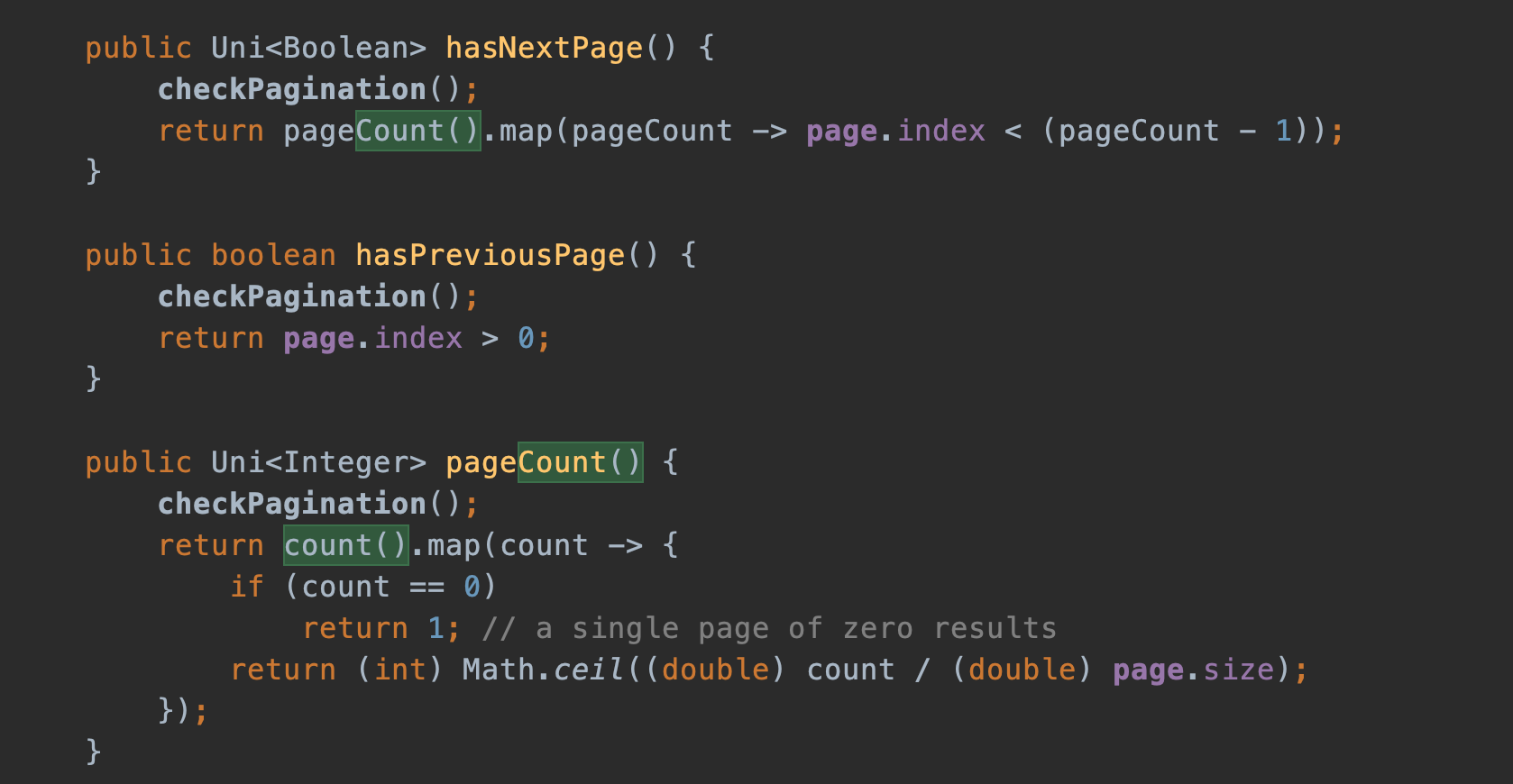
Могли бы иhasPreviousPage()упаковать вUni-_-
Поэтому и получаем 3 одинаковых запроса. По факту нам достаточно сделать вызов только двух методов: list(), count(). Всю остальную метаинформацию можно рассчитать самостоятельно.
@GET
@Path("true")
@ReactiveTransactional
@Produces(MediaType.APPLICATION_JSON)
public Uni<Page<Post>> getAllTrue(
@QueryParam("offset") Integer offset,
@QueryParam("limit") Integer limit
) {
final PanacheQuery<Post> pageQuery = repository.findAll().page(offset, limit);
return Uni.combine().all().unis(
pageQuery.list(),
pageQuery.count()
).asTuple().onItem().transform(
t -> {
final List<Post> posts = t.getItem1();
final Long totalElements = t.getItem2();
final int totalPages = (int) Math.ceil((double) totalElements / limit);
final int currentPageSize = posts.size();
final int currentCountShowElements = limit * (offset + 1) - (limit + currentPageSize);
final boolean hasPrevPage = offset > 0 && totalElements > 0;
final boolean hasNextPage = currentCountShowElements < totalElements;
return Page.<Post>builder()
.content(posts)
.prevPage(hasPrevPage)
.nextPage(hasNextPage)
.totalPages(totalPages)
.totalElements(totalElements)
.pageCount(offset)
.pageSize(currentPageSize)
.build();
}
);
}Теперь мы вызываем только 2 метода у PanacheQuery, то есть будет только 2 запроса к БД. Остальные данные мы рассчитываем:
- 17 строка. Общее количество страниц. Получаем путём деления количества всех элементов на размер страницы и округления результата в бо́льшую сторону. Допустим, у нас 21 элемент, а страницы по 2 элемента, результат от деления будет 10,5. Это значит, что у нас 11 страниц.
- 19 строка. Получаем количество элементов на текущей странице.
- 20 строка. Получаем количество элементов, которые находятся на предыдущих страницах, не включая текущую.
- 22 строка. Определяем, есть ли предыдущие страницы. Можно использовать вызов
pageQuery.hasPreviousPage(), но его реализация не предусматривает, что элементов в БД совсем нет. - 23 строка. Определяет наличие следующих страниц.
- 31 строка. Берём текущий номер страницы из переданных данных.
- 32 строка. Количество элементов на текущей странице определяем по размеру коллекции.
Вместо 4 запросов к БД, мы выполним 2, а результат получили такой же. Нравиться.
Резюмирую
В Quarkus есть механизмы для пагинации, но необходимо учитывать особенности работы методов.
При работе с Hibernate всегда смотрите, какой SQL у него получается сгенерировать по итогу. Результат генерации может удивить.
