Цель пагинации — избежать одномоментной выборки больших объёмов данных. Нет смысла выгружать пользователю все посты, которые есть у вас в блоге. Куда логичнее разделить их все на секции — страницы. Пагинация — это возможность получать данные порциями.
Spring, Quarkus и другие фреймворки для пагинации по базе данных генерируют SQL запросы. Делают ли они это эффективно? Рассмотрим проблемы пагинации с точки зрения SQL.
Разберёмся в стандартном подходе к пагинации с использованием OFFSET. А после рассмотрим Seek Method, который также называют Keyset Pagination. И разберёмся, почему его следует использовать при навигации по больши́м наборам результатов, а про OFFSET сто́ит забыть 🙅♂️
Проект с примерами: https://github.com/Example-uPagge/spring-pagination
В этом проекте есть и sql запросы, которые будут упомянаться, и генерация 10000 записей.
Пагинация OFFSET
Рассмотрим, как работает стандартная OFFSET пагинация в SQL. Этот вид использует Spring, когда вы вызываете метод JpaRepository#findAll(Pageable) и аналогичные методы. Quarkus тоже использует этот способ пагинации.
Запрос, ограничивающий количество записей, мы будем называть TOP-N. Он позволит получить первые N элементов. Для такого запроса используют директиву FETCH FIRST N ROWS ONLY в PostgreSQL.
SELECT id
FROM post
ORDER BY created_on DESC
FETCH FIRST 50 ROWS ONLYА запрос, который пропускает первые M записей и получает следующие N записей назовем NEXT-N. Он выглядит следующим образом:
SELECT id
FROM post
ORDER BY created_on DESC
OFFSET 150 ROWS
FETCH NEXT 50 ROWS ONLYМы пропускаем 150 записей и получаем следующие 50. В этом случае 50 это размер нашей страницы, а 150 это количество элементов на прошлых страницах. Получается, мы находимся на четвёртой странице.
Посмотрим документацию Postgres, что там пишут про OFFSET:
The rows skipped by anOFFSETclause still have to be computed inside the server; therefore a largeOFFSETmight be inefficient.
Строки, пропущенные предложениемOFFSET, все равно должны быть вычислены сервером; поэтому большойOFFSETможет быть неэффективным.
Предложение OFFSET принимает только один-единственный параметр: количество строк, которые нужно отбросить. Больше никакого контекста. Единственное, что может сделать база данных с этим числом, это сначала получить множество строк, а потом отбросить лишние. Другими словами, большие смещения создают большую нагрузку на базу данных — неважно, SQL или NoSQL.
Но на этом проблемы этим не ограничиваются. Подумайте, что произойдёт, если между выборкой двух страниц будет вставлена новая запись?
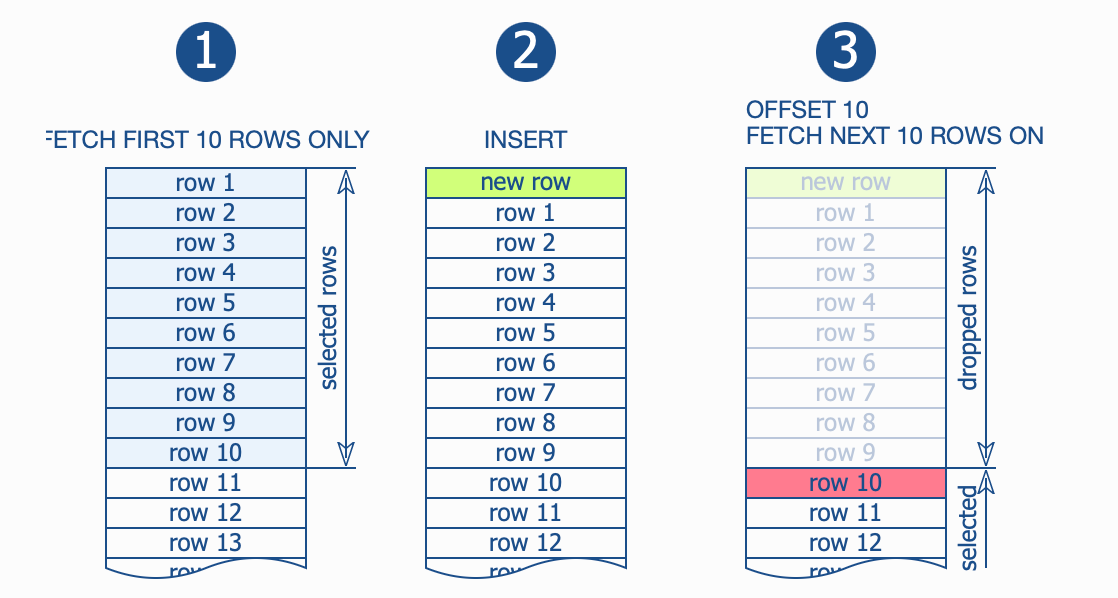
При использовании смещения для пропуска ранее найденных записей, вы получите дубликаты в случае, если между получением двух страниц были вставлены новые строки. Возможны и другие аномалии, это лишь наиболее распространённая.
Индекс в OFFSET Pagination
Выполним наши запросы пагинации и проанализируем результаты. Сначала получим первые 50 элементов.
SELECT id
FROM post
ORDER BY create_on DESC
FETCH FIRST 50 ROWS ONLY;
Limit (cost=516.19..516.32 rows=50 width=33)
(actual time=3.372..3.380 rows=50 loops=1)
-> Sort (cost=516.19..541.19 rows=10000 width=33)
(actual time=3.370..3.374 rows=50 loops=1)
Sort Key: create_on
Sort Method: top-N heapsort Memory: 28kB
-> Seq Scan on post
(cost=0.00..184.00 rows=10000 width=33)
(actual time=0.014..1.577 rows=10000 loops=1)
Planning Time: 0.083 ms
Execution Time: 3.409 msСамая дорогая операция в данном запросе — это сортировка. На нее ушло 3.37 ms, тогда как весь запрос выполнялся 3.4 ms.
Запросим последнюю страницу:
SELECT id
FROM post
ORDER BY create_on DESC
OFFSET 9950 ROWS
FETCH NEXT 50 ROWS ONLY
Limit (cost=873.26..873.39 rows=50 width=33)
(actual time=6.375..6.386 rows=50 loops=1)
-> Sort (cost=848.39..873.39 rows=10000 width=33)
(actual time=5.027..5.882 rows=10000 loops=1)
Sort Key: create_on
Sort Method: quicksort Memory: 1166kB
-> Seq Scan on post
(cost=0.00..184.00 rows=10000 width=33)
(actual time=0.013..1.936 rows=10000 loops=1)
Planning Time: 0.080 ms
Execution Time: 6.414 msМетод сортировки изменился с top-N heapsort на quicksort, а его скорость работы упала.
Метод сортировки top-N heapsort
Экспериментальным путём я выяснил, что PostgreSQL до OFFSET 4950 используется тип сортировки top-N heapsort. Начиная с OFFSET 4950 методом сортировки становится quicksort.
Говоря про скорость, то top-N heapsort быстрее в начале таблицы, и чем больший OFFSET вы выполняете, тем медленнее он работает. На OFFSET 4950, а это примерно половина таблицы, он становится равен методу quicksort.
И здесь мы вспоминаем про индексы. Индекс по полю сортировки действительно увеличит скорость пагинации. Создадим индекс для столбца create_on:
CREATE INDEX idx_post_created_on ON post (create_on DESC)Теперь при выполнении запроса TOP-N база данных не использует сортировку. Она сканирует индекс idx_post_created_on и сканируется только 50 записей:
SELECT *
FROM post
ORDER BY create_on
FETCH FIRST 50 ROWS ONLY;
Limit (cost=0.29..2.07 rows=50 width=33)
(actual time=0.023..0.036 rows=50 loops=1)
-> Index Scan Backward using idx_post_created_on on post
(cost=0.29..357.29 rows=10000 width=33)
(actual time=0.022..0.030 rows=50 loops=1)
Planning Time: 0.106 ms
Execution Time: 0.053 msЗапрос выполнился за 0.053 ms, что в 64 раза быстрее, чем без индекса.
Получим набор значений для второй страницы:
SELECT id
FROM post
ORDER BY created_on DESC
OFFSET 50 ROWS
FETCH NEXT 50 ROWS ONLY
Limit (cost=2.07..3.85 rows=50 width=33)
(actual time=0.031..0.043 rows=50 loops=1)
-> Index Scan Backward using idx_post_created_on on post
(cost=0.29..357.29 rows=10000 width=33)
(actual time=0.019..0.036 rows=100 loops=1)
Planning Time: 0.086 ms
Execution Time: 0.059 msДля второй страницы видим, что idx_post_created_on просканировал 100 записей, потому что ему нужно пропустить первые 50 строк, содержащихся на первой странице, чтобы загрузить следующие 50 записей, которые должны быть возвращены этим запросом:
Чем дальше мы удаляемся от первой страницы, тем больше записей нужно просканировать индексом idx_post_created_on, чтобы пропустить записи, указанные в предложении OFFSET:
SELECT *
FROM post
ORDER BY create_on
OFFSET 9950 ROWS FETCH NEXT 50 ROWS ONLY;
Limit (cost=355.50..357.29 rows=50 width=33)
(actual time=4.347..4.361 rows=50 loops=1)
-> Index Scan Backward using idx_post_created_on on post
(cost=0.29..357.29 rows=10000 width=33)
(actual time=0.021..3.123 rows=10000 loops=1)
Planning Time: 0.092 ms
Execution Time: 4.388 msСканирование всего индекса idx_post_created_on занимает больше времени, чем сканирование одной страницы.
Keyset Pagination
Теперь представьте себе мир без этих проблем. Жить без OFFSET просто: достаточно использовать предложение WHERE. Оно выбирает данные, которые вы ещё не видели.
Для этого используем тот факт, что работаем с упорядоченным множеством — у нас ведь есть ORDER BY, не так ли? Когда есть определенный порядок сортировки, мы можем использовать простой фильтр, чтобы выбрать только данные, которые следуют за той записью, которую мы видели последней. Это ключевая идея Keyset Pagination.
Запрос TOP-N выглядит следующим образом:
SELECT id, created_on
FROM post
ORDER BY created_on DESC, id DESC
FETCH FIRST 50 ROWS ONLYОбратите внимание, что в предложение ORDER BY включен id, поскольку значения created_on не уникальные.
Для запроса NEXT-N используем данные столбцов created_on и id последней записи в выборке. Например, это может выглядеть так:
SELECT id, create_on
FROM post
WHERE
(create_on, id) < ('2022-10-30 00:11:43.224314', '8766d496-44c7-4e48-af29-b19178692cd9')
ORDER BY create_on DESC
FETCH FIRST 50 ROWS ONLYВыражение значения строки ('2022-10-30 00:11:43.224314', '8766d496-44c7-4e48-af29-b19178692cd9') эквивалентно:
created_on < '2022-10-30 00:11:43.224314' OR
(
(created_on = '2022-10-30 00:11:43.224314') AND
(id < '8766d496-44c7-4e48-af29-b19178692cd9')
)Индекс в Keyset Pagination
Поскольку метод Seek использует столбцы created_on и id в предложении ORDER BY, мы создадим индекс idx_post_created_on на обоих столбцах:
CREATE INDEX idx_post_create_on ON post (created_on DESC, id DESC)Теперь, выполняя запрос TOP-N Keyset Pagination, мы видим, что он использует индекс idx_post_created_on:
SELECT *
FROM post
ORDER BY create_on DESC, id DESC
FETCH FIRST 50 ROWS ONLY;
Limit (cost=0.29..3.05 rows=50 width=33)
(actual time=0.024..0.039 rows=50 loops=1)
-> Index Scan using idx_post_created_on on post
(cost=0.29..554.22 rows=10000 width=33)
(actual time=0.023..0.033 rows=50 loops=1)
Planning Time: 0.116 ms
Execution Time: 0.058 msЗапрос NEXT-N Keyset Pagination также использует индекс idx_post_created_on и, в отличие от OFFSET Pagination, на этот раз сканируется только 50 строк:
SELECT *
FROM post
WHERE (create_on, id) < ('2022-11-05 21:12:33.750149', '9000a54b-3843-4eca-b87f-75a1fa442f6a')
ORDER BY create_on DESC
FETCH FIRST 50 ROWS ONLY
Limit (cost=0.29..3.19 rows=50 width=33)
(actual time=0.011..0.024 rows=50 loops=1)
-> Index Scan using idx_post_created_on on post
(cost=0.29..578.35 rows=9950 width=33)
(actual time=0.010..0.018 rows=50 loops=1)
"Index Cond: (
ROW(create_on, id) <
ROW('2022-11-05 21:12:33.750149'::timestamp without time zone, '9000a54b-3843-4eca-b87f-75a1fa442f6a'::uuid)
)"
Planning Time: 0.131 ms
Execution Time: 0.043 msТо есть загрузка последней страницы будет такой же быстрой, как и первой, поскольку Keyset Pagination не сканируется весь индекс, чтобы пропустить записи:
SELECT *
FROM post
WHERE (create_on, id) < ('2022-10-30 00:11:43.224314', '8766d496-44c7-4e48-af29-b19178692cd9')
ORDER BY create_on DESC
FETCH FIRST 50 ROWS ONLY
Limit (cost=0.29..73.89 rows=49 width=33)
(actual time=0.010..0.026 rows=49 loops=1)
-> Index Scan using idx_post_created_on on post
(cost=0.29..73.89 rows=49 width=33)
(actual time=0.009..0.020 rows=49 loops=1)
"Index Cond: (
ROW(create_on, id) <
ROW('2022-10-30 00:11:43.224314'::timestamp without time zone, '8766d496-44c7-4e48-af29-b19178692cd9'::uuid)
)"
Planning Time: 0.244 ms
Execution Time: 0.048 msЕдинственный минус этого подхода, — он не позволяет перейти к определённой странице. Пользователям будет доступна только бесконечная загрузка.
Но как часто пользователю вашей системы нужна 163-я страница результатов? А как часто вы доходите хотя бы до 3 страницы в поисковых запросах? Вспомните популярные соцсети, давно ли вы там видели кнопки пагинации?
Если задуматься, то нумерованная пагинация это бред. Вы ожидаете, что пользователь пройдётся по всем страницам в поисках нужной записи? Куда важнее дать пользователю возможность сортировки и нормальный поиск. И если первые N результатов ему не подойдут, то он воспользуется бесконечной подгрузкой с использованием Keyset Pagination. И если не найдёт нужный результат, то попробует использовать другие параметры поиска и сортировки.
Резюмирую
Пагинация с использованием OFFSET имеет множество проблем. Например, получение одних и тех же записей на разных страницах при вставке, и это не говоря про медленную скорость работы.
На скриншоте ниже график сравнения времени отклика с использованием Offset и Seek. Seek работает с одинаковой скоростью для любой страницы, в то время как Offset отвечает всё дольше и дольше.
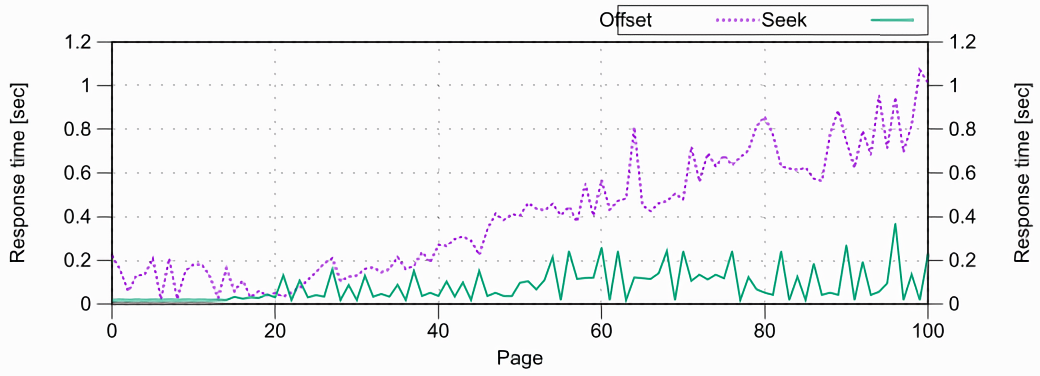
Проблема производительности не так страшна при использовании индексов, и если пользователь не уйдёт дальше первых 5 страниц. Но при задачах, которые проходится по всем записям с помощью пагинации, лучше выберете Keyset Pagination.
У Keyset Pagination 2 недостатка: он используется только с бесконечной загрузкой на фронте, и фреймворки из коробки не поддерживают этот способ, так что вам придётся его реализовать самостоятельно.
