
Если вы используете Hibernate в течение длительного времени, есть большая вероятность, что вы столкнулись с MultipleBagFetchException:
org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bagsВ этой статье мы рассмотрим причины, по которым Hibernate выбрасывает MultipleBagFetchException, а также лучший способ решения этой проблемы.
Данная статья является переводом и адаптацией англоязычных статей. Я тщательно перевожу статью на русский, актуализирую устаревшие моменты, а также проверяю или пишу примеры кода, которые вы можете запустить самостоятельно.
— — — — —
* The best way to fix the Hibernate MultipleBagFetchException
* Spring Data JPA MultipleBagFetchException
Используемые версии
Java 17
Hibernate 6.1.0.Final
H2 Database 2.1.214
Доменная модель
В нашем приложении определены три сущности: Post, PostComment и Tag, которые связаны следующим образом:
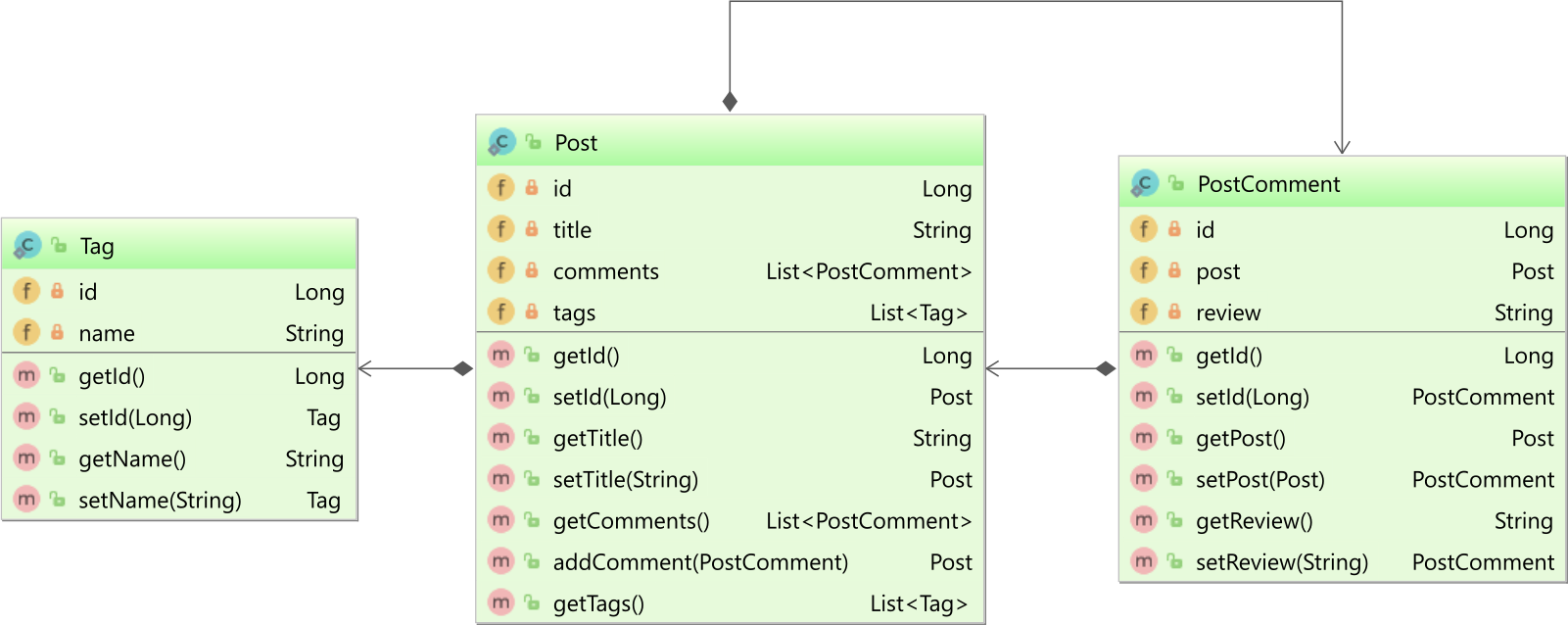
Нас в основном интересует то, что сущность Post определяет двунаправленную связь @OneToMany с дочерней сущностью PostComment, а также однонаправленную связь @ManyToMany с сущностью Tag.
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<PostComment> comments = new ArrayList<>();
@ManyToMany(
cascade = {
CascadeType.PERSIST,
CascadeType.MERGE
}
)
@JoinTable(
name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private List<Tag> tags = new ArrayList<>();Причина, по которой для связи @ManyToMany установлены только PERSIST и MERGE, заключается в том, что Tag не является дочерней сущностью.
Поскольку жизненный цикл Tag не связан с сущностью Post, каскадная операция REMOVE или включение механизма orphanRemoval было бы ошибкой.
Исправление для Hibernate
Для начала рассмотрим причины появления исключения в Hibernate, а также вариант исправления, который вредит производительности приложения, но который часто упоминают на различных форумах. Далее мы рассмотрим вариант, как исправить эту проблему в Spring JPA.
Если мы хотим получить объекты Post со значениями идентификатора от 1 до 50, а также все связанные с ними объекты PostComment и Tag, мы напишем запрос, подобный следующему:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
left join fetch p.comments
left join fetch p.tags
where p.id between :minId and :maxId
""", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 50L)
.getResultList();Однако при выполнении приведенного выше запроса сущности Hibernate выбрасывает ошибку MultipleBagFetchException при компиляции запроса JPQL:
org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags: [
dev.struchkov.example.hibernate.nbfe.problem.domain.Post.comments,
dev.struchkov.example.hibernate.nbfe.problem.domain.Post.tags
]Таким образом, Hibernate не выполняет SQL-запрос. Причина, по которой Hibernate выбрасывает исключение, заключается в том, что могут возникать дубликаты.
Как НЕ "исправить" проблему
Если вы погуглите MultipleBagFetchException, вы увидите множество неправильных ответов, например, этот ответ на StackOverflow, который, что удивительно, имеет более 300 голосов.

Так просто, но так неправильно!
Использование Set вместо List
Итак, давайте изменим тип коллекции связи с List на Set:
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private Set<PostComment> comments = new HashSet<>();
@ManyToMany(
cascade = {
CascadeType.PERSIST,
CascadeType.MERGE
}
)
@JoinTable(
name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private Set<Tag> tags = new HashSet<>();При повторном выполнении предыдущего запроса, исключение не возникнет. Однако вот SQL-запрос, который Hibernate выполнил:
select p1_0.id,
c1_0.post_id,
c1_0.id,
c1_0.review,
t1_0.post_id,
t1_1.id,
t1_1.name,
p1_0.title
from Post p1_0
left join PostComment c1_0
on p1_0.id = c1_0.post_id
left join (post_tag t1_0 join Tag t1_1 on t1_1.id = t1_0.tag_id)
on p1_0.id = t1_0.post_id
where p1_0.id between 1 and 50;Итак, что же не так в этом SQL-запросе?
Таблицы post и post_comment связаны через столбец внешнего ключа post_id, поэтому объединение дает набор результатов, содержащий все строки таблицы post со значениями первичного ключа от 1 до 50 вместе со связанными с ними строками таблицы post_comment.
Таблицы post и tag также связаны через столбцы post_id и tag_id в связующей таблице post_tag, поэтому эти два объединения дают набор результатов, содержащий все строки таблицы post со значениями от 1 до 50, а также связанные с ними строки таблицы tag.
Теперь, чтобы объединить эти два набора результатов, база данных может использовать только декартово произведение, поэтому конечный набор результатов содержит 50 строк post, умноженных на соответствующие строки таблицы post_comment и tag.
Представим, что у нас 50 постов, по 10_000 комментариев для каждого, также каждый пост имеет 10 тегов. Конечный набор результатов будет содержать 10_000_000 записей (50 x 10000 x 20), как показано в следующем тестовом примере:
List<Post> posts = entityManager.createQuery("""
select p
from Post p
left join fetch p.comments
left join fetch p.tags
where p.id between :minId and :maxId
""", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 50L)
.getResultList();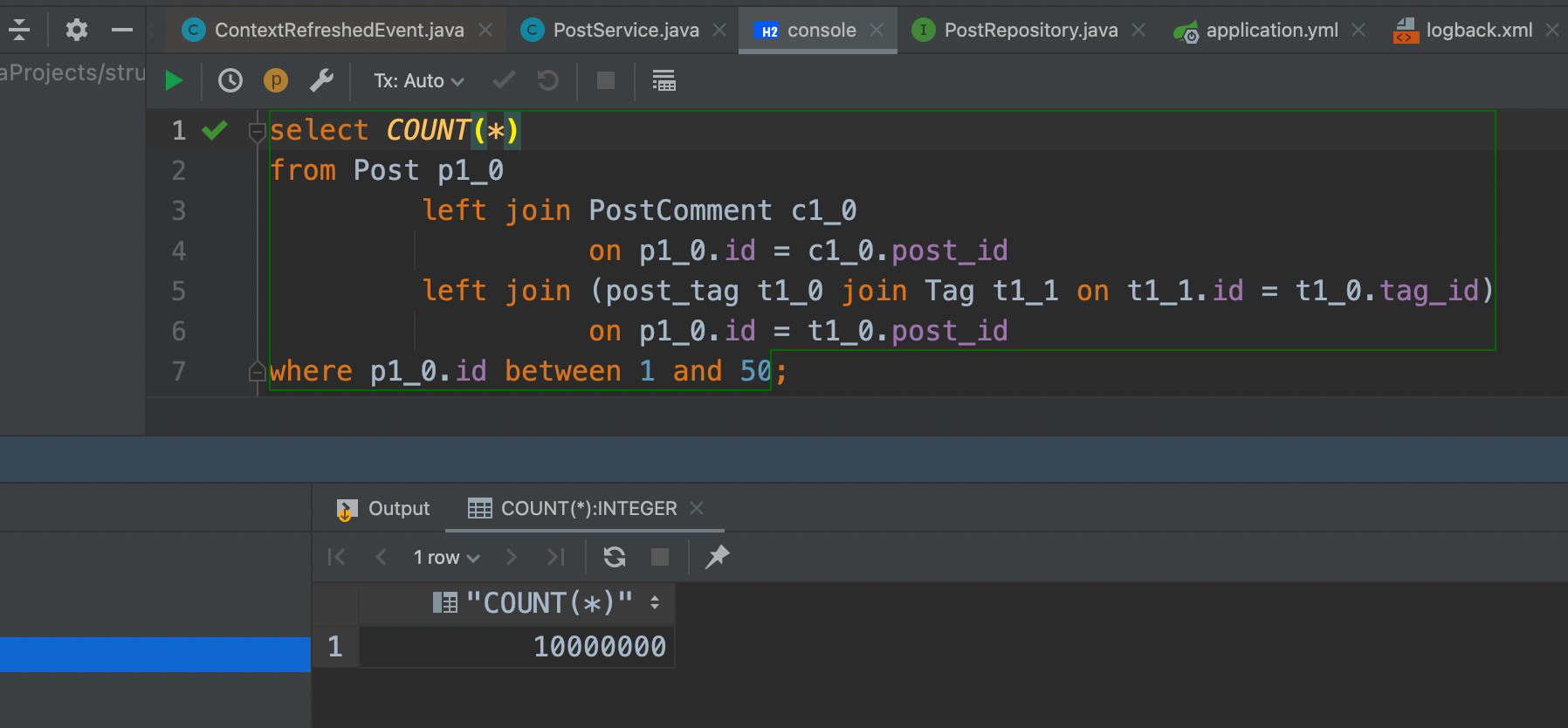
Этот вариант сработает правильно, но мы заплатим за это производительностью. Сделаем импровизированный бенчмарк: перед и после выполнения этого кода получим текщее время системы в миллисекундах, а далее вычтем из большего меньшее и так получим потраченное время на выполнение. Да это не самый удачный способ замера, но даже он подойдет.
Результат бенчмарка: 24192 миллисекунд. Запомните это значение, сравним его с правильным решением.
Исправляем MultipleBagFetchException
Чтобы избежать декартова произведения, за один раз можно получить не более одной связи. Таким образом, вместо выполнения одного JPQL-запроса, который извлекает две связи сразу, мы можем выполнить два JPQL-запроса:
List<Post> posts = entityManager.createQuery("""
select distinct p
from Post p
left join fetch p.comments
where p.id between :minId and :maxId""", Post.class)
.setParameter("minId", 1L)
.setParameter("maxId", 50L)
.getResultList();
posts = entityManager.createQuery("""
select distinct p
from Post p
left join fetch p.tags t
where p in :posts""", Post.class)
.setParameter("posts", posts)
.setHint(QueryHints.PASS_DISTINCT_THROUGH, false)
.getResultList();Первый запрос JPQL определяет основные критерии фильтрации и извлекает объекты Post вместе с соответствующими записями PostComment.
Теперь нам нужно получить сущности Post вместе с Tag. Благодаря Persistence Context, Hibernate установит коллекцию tags для ранее полученных сущностей Post.
Здесь применяем тот же бенчмарк, и получаем 3300 миллисекунд, что примерно в 7 раз быстрее.
Решение для Spring Jpa
Вряд ли вы где-нибудь увидите работу с чистым Hibernate, скорее всего это будет Spring JPA. Давайте посмотрим, как и для него решить эту проблему.
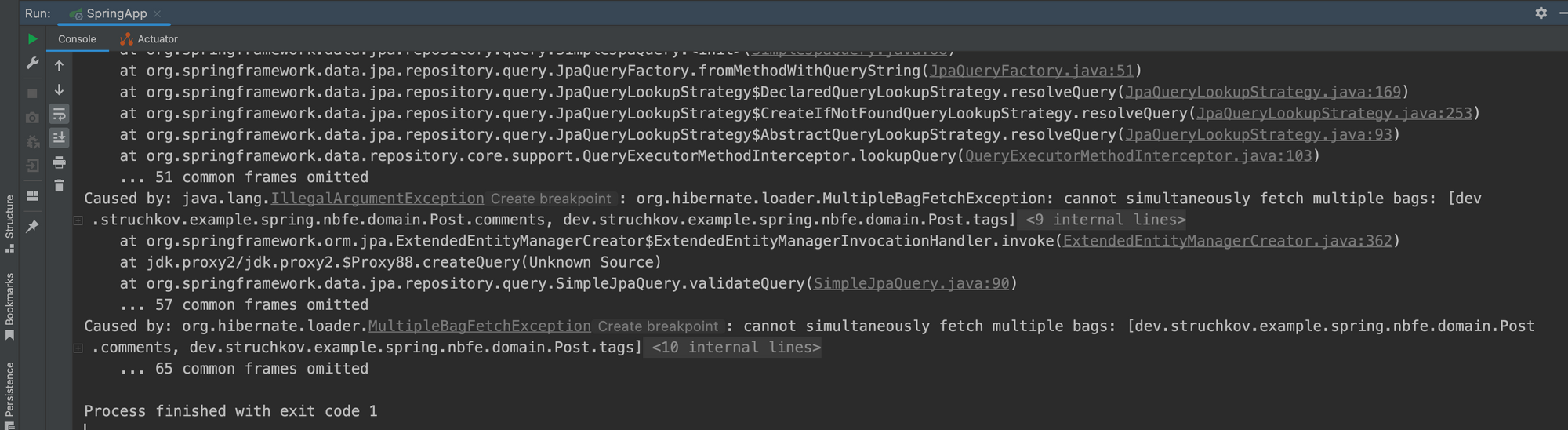
Для начала создаем проблему:
public interface PostRepository extends JpaRepository<Post, Long> {
@Query("""
select distinct p
from Post p
left join fetch p.comments
left join fetch p.tags
where p.id between :minId and :maxId
""")
List<Post> findAllWithCommentsAndTags(
@Param("minId") long minId,
@Param("maxId") long maxId
);
}Ваше приложение Spring даже не запустится, выбросив исключение MultipleBagFetchException при попытке создать JPA TypedQuery из связанной аннотации @Query.
Таким образом, хотя мы не можем получить обе коллекции с помощью одного запроса JPA, мы точно также можем использовать два запроса для получения всех необходимых нам данных.
public interface PostRepository extends JpaRepository<Post, Long> {
@Query("""
select distinct p
from Post p
left join fetch p.comments
where p.id between :minId and :maxId
""")
List<Post> findAllWithComments(
@Param("minId") long minId,
@Param("maxId") long maxId
);
@Query("""
select distinct p
from Post p
left join fetch p.tags
where p.id between :minId and :maxId
""")
List<Post> findAllWithTags(
@Param("minId") long minId,
@Param("maxId") long maxId
);
}Запрос findAllWithComments() будет собирать нужные сущности Post вместе со связью PostComment, а запрос findAllWithTags() будет собирать сущности Post вместе со связью Tag.
Выполнение двух запросов позволит нам избежать декартова произведения, но необходимо объединить результаты так, чтобы вернуть одну коллекцию записей Post, содержащую инициализированные коллекции комментариев и тегов.
И именно здесь нам снова поможет кэш первого уровня Hibernate. Создадим PostService и определим метод findAllWithCommentsAndTagsmethod(), который реализуется следующим образом:
@Service
@RequiredArgsConstructor
public class PostService {
private final PostRepository postRepository;
@Transactional(readOnly = true)
public List<Post> findAllWithCommentsAndTags(long minId, long maxId) {
final List<Post> posts = postRepository.findAllWithComments(
minId,
maxId
);
return !posts.isEmpty() ?
postRepository.findAllWithTags(
minId,
maxId
) :
posts;
}
}Из-за аннотации @Transactional метод будет выполняться в транзакционном контексте, что означает, что оба вызова метода PostRepository будут происходить в контексте одного и того же Persistence Context.
По этой причине методы репозитория вернут два объекта List, содержащие одинаковые ссылки на объекты Post, поскольку вы можете иметь не более одной ссылки на объект, управляемой данным Persistence Context.
В то время как первый метод будет извлекать объекты Post и хранить их в Persistence Context, второй метод, просто объединит существующие объекты со ссылками, извлеченными из БД, которые теперь содержат инициализированные коллекции тегов.
Таким образом, и комментарии, и коллекции тегов будут извлечены до возврата списка объектов Post обратно вызывающему метод сервису.
Заключение
Существует так много решений в блогах, видео, книгах и ответов на форумах, предлагающих неправильное решение проблемы MultipleBagFetchException Hibernate. Все эти ресурсы говорят вам, что использование Set вместо List является правильным способом избежать этого исключения.
Однако исключение MultipleBagFetchException говорит вам о том, что может быть получено декартово произведение, а это в большинстве случаев нежелательно при выборке сущностей, поскольку может привести к ужасным проблемам с производительностью.
Выполняя выборку не более одной коллекции на запрос, вы не только предотвратите эту проблему, но и избежите декартова произведения SQL, которое может возникнуть при выполнении одного SQL-запроса, объединяющего несколько несвязанных ассоциаций "один-ко-многим".
Знание того, как бороться с исключением MultipleBagFetchException, очень важно при использовании Spring Data JPA, поскольку в конечном итоге вы столкнетесь с этой проблемой.
