
Версия Java 8 действительно принесла значительные улучшения, особенно в области работы с коллекциями, благодаря таким нововведениям, как Stream API. Это нововведение позволяет обрабатывать данные в функциональном стиле, что упрощает и делает код более выразительным и компактным.
Зачем нужен Stream API?
До появления Stream API, работа с коллекциями в Java часто осуществлялась через циклы и условные операторы для фильтрации, преобразования и агрегации данных. Этот подход был громоздким, трудно читаемым и часто подвержен ошибкам. Рассмотрим пример:
public void printSpecies(List<SeaCreature> seaCreatures) {
Set<Species> speciesSet = new HashSet<>();
for (SeaCreature sc : seaCreatures) {
if (sc.getWeight() >= 10)
speciesSet.add(sc.getSpecies());
}
List<Species> sortedSpecies = new ArrayList<>(speciesSet);
Collections.sort(sortedSpecies, new Comparator<Species>() {
public int compare (Species a, Species b) {
return Integer.compare(a.getPopulation(), b.getPopulation());
}
});
for (Species s : sortedSpecies)
System.out.println(s.getName());
}Этот код выглядит перегруженным, хотя выполняет достаточно простые операции: фильтрация, сортировка и вывод. С введением Stream API подобные задачи решаются гораздо проще и элегантнее. Перепишем пример с использованием Stream API:
public void printSpecies(List<SeaCreature> seaCreatures) {
seaCreatures.stream()
.filter(sc -> sc.getWeight() >= 10)
.map(SeaCreature::getSpecies)
.distinct()
.sorted(Comparator.comparing(Species::getPopulation))
.map(Species::getName)
.forEach(System.out::println);
}Stream API обеспечивает функциональный стиль работы с данными, предлагая более компактный, выразительный и читаемый код, а также облегчая параллельное выполнение операций.
Основы Stream API
Stream API — это мощный инструмент для обработки данных, который идеально подходит для ряда задач, но не является универсальным решением. Его применение оправдано, если ваша задача вписывается в следующий шаблон:
- Источник данных — это коллекция или другая структура, содержащая элементы.
- Выполнение преобразований — это фильтрация, сортировка, маппинг и другие операции над элементами.
- Сохранение результата — это помещение преобразованных данных в новую структуру (например, список, множество и т.д.).
Существует забавное “условное заболевание” под названием “стримоз головного мозга”. Оно возникает у разработчиков, которые только что освоили Stream API и испытывают сильное желание использовать его повсюду, даже когда это нецелесообразно. Симптомы включают чрезмерное усложнение кода и применение Stream API в тех ситуациях, где более простые методы были бы эффективнее.
Пример из реального мира
Stream API можно представить как конвейер на рыболовецком судне:
- Источник данных — это река, полная различных морских существ. Она символизирует исходные данные, которые мы собираемся обрабатывать
- Filter — это как рыбаки, которые отбирают только нужные виды рыбы из всего улова, исключая ненужные виды. В коде это фильтрация элементов с помощью метода
filter(). - Map — подобен процессу упаковки рыбы в контейнеры. Этот шаг трансформирует элементы (рыбу) в другой вид данных — “упаковки”. В Stream API это делается с помощью метода
map(). - Collect — это этап, когда все упаковки складываются в грузовик для дальнейшей транспортировки. В Stream API это финальная операция
collect(), которая собирает все результаты в конечную структуру данных.
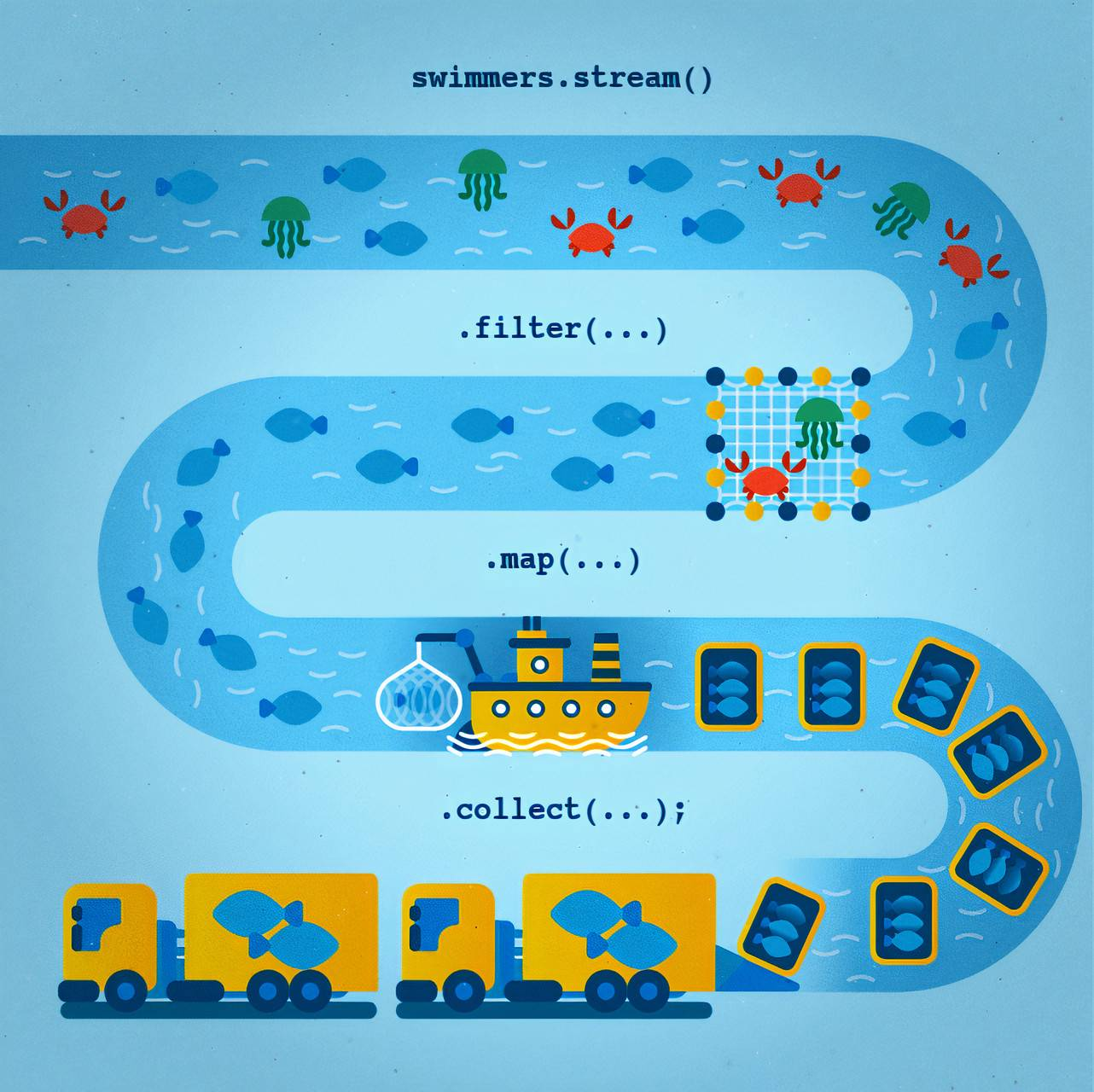
Таким образом, Stream API создает “поток”, где каждый элемент проходит через определенные этапы, как на конвейере, что делает процесс эффективным и последовательным.
Компоненты Stream API
Основные компоненты Stream API работают вместе для организации эффективного и декларативного процесса обработки.

- Источник (Source) - это место, откуда поступают данные для обработки. Источником может быть коллекция, массив, строка, файл, генератор или другой источник данных.
- Операции (Operations) — преобразования и/или манипуляции над данными в потоке, которые делятся на промежуточные и терминальные.
- Поток (Stream) - последовательность элементов, которая подлежит обработке. Он может обрабатываться как в однопоточном, так и в многопоточном режиме.
- Пайплайн (Pipeline) - цепочка промежуточных операций, которая применяется к данным, образуя последовательность преобразований.
- Терминал (Terminal) - завершающая операция, после которой поток закрывается, а данные выводятся или преобразуются в конечную структуру.
Источники даных для потоков
Stream API поддерживает множество типов источников данных. Поток может быть создан из коллекций, массивов, строк, файлов и других структур. Например:
List<String> list = Arrays.asList("one", "two", "three");
Stream<String> streamFromList = list.stream();
String[] array = {"one", "two", "three"};
Stream<String> streamFromArray = Arrays.stream(array);Таким образом, два разных источника данных (список и массив) могут быть преобразованы в потоки.
Операции над потоком
Операции Stream API можно разделить на два типа: промежуточные и терминальные.
Промежуточные операции
Промежуточные операции описываются декларативно, часто с помощью лямбда-выражений. Они возвращают новый поток, что позволяет строить “цепочки” операций (pipeline). Промежуточные операции не выполняются немедленно — они откладываются до тех пор, пока не будет вызвана терминальная операция. Например:
List<String> list = Arrays.asList("one", "two", "three", "two");
Stream<String> distinctStream = list.stream().distinct();Здесь distinct() — это промежуточная операция, которая удаляет дубликаты из потока. Промежуточные операции следуют принципу Fluent API, позволяя строить цепочки преобразований данных.
Терминальные операции
Терминальные операции завершают обработку потока и возвращают результат. Они могут включать такие действия, как подсчет, сбор в коллекцию, поиск или перебор элементов:
List<String> list = Arrays.asList("one", "two", "three");
long count = list.stream().count();В этом примере count() — терминальная операция, которая возвращает количество элементов в потоке. После вызова терминальной операции поток больше нельзя использовать повторно — это приведет к ошибке:
Stream<String> stream = Stream.of("один", "два", "три");
stream.forEach(System.out::println); // Это терминальная операция.
// Попытка использовать стрим снова вызовет ошибку.
// Например, следующий код вызовет ошибку IllegalStateException.
stream.forEach(System.out::println);Как работает Stream?
Stream API в Java обрабатывает данные с помощью цепочек промежуточных и терминальных операций, но важная особенность заключается в том, что каждый элемент потока проходит через весь пайплайн поэтапно. Операции не применяются к коллекции целиком, а работают над каждым элементом поочередно.
Рассмотрим следующий код:
public static void main(String[] args) {
final List<String> list = List.of("one", "two", "three");
list.stream()
.filter(s -> {
System.out.println("filter: " + s);
return s.length() <= 3;
})
.map(s1 -> {
System.out.println("map: " + s1);
return s1.toUpperCase();
})
.forEach(x -> {
System.out.println("forEach: " + x);
});
}В этом примере последовательно применяются три операции:
filter()— фильтрует строки, длина которых меньше или равна 3 символам.map()— преобразует оставшиеся строки в верхний регистр.forEach()— выводит каждый элемент на консоль.
На первый взгляд может показаться, что весь список сначала отфильтруется, затем преобразуется, а после этого будет выведен на консоль. Однако, благодаря ленивой обработке, это происходит не так. Вместо того, чтобы обрабатывать все элементы на каждом этапе, Stream API последовательно пропускает каждый элемент через весь пайплайн операций.
filter: one
map: one
forEach: ONE
filter: two
map: two
forEach: TWO
filter: threeЭтот вывод показывает, что:
- Первый элемент “one” проходит через метод
filter(), затем преобразуется в верхний регистр черезmap(), после чего выводится на консоль. - Второй элемент “two” обрабатывается аналогичным образом: фильтрация, преобразование, вывод.
- Третий элемент “three” не проходит фильтр, так как его длина больше 3, и его дальнейшая обработка прекращается после вызова
filter().
Сначала первый элемент проходит через пайплайн, затем второй, а третий не проходит проверку в filter(), поэтому его обработка прекращается на этом этапе. Это важно для эффективности и надлежащего функционирования потоков в Java! Почему?
Этот поэтапный подход делает параллелизм более простым и безопасным. Поскольку каждый элемент обрабатывается независимо, легко перейти от последовательного к параллельному потоку.
Stateless и Stateful операции
Операции в Stream API делятся на два типа: stateless (без состояния) и stateful (с состоянием), в зависимости от того, как они обрабатывают элементы потока.
Операции без состояния, такие как map() и filter(), обрабатывают каждый элемент потока независимо от других. Они не требуют информации о предыдущих или последующих элементах для своей работы, что делает их идеально подходящими для параллельной обработки. Например, в методе filter() каждый элемент проверяется по заданному условию отдельно, и его результат не зависит от других элементов.
Операции с состоянием, такие как sorted(), distinct() или limit(), требуют информации о других элементах потока. Эти операции не могут начать возвращать результаты, пока не обработают часть или весь поток. Например, sorted() должна сначала собрать все элементы, чтобы их отсортировать, а затем уже передать их на последующие этапы.
Если в пайплайне используются только операции без состояния, то поток может быть обработан “в один проход”, что делает выполнение быстрым и эффективным. Однако при добавлении операций с состоянием поток делится на секции, и каждая секция должна завершить свою обработку перед началом следующей.
Добавим операцию сортировки в наш пример и посмотрим, как это изменит выполнение:
public static void main(String[] args) {
final List<String> list = List.of("one", "two", "three");
list.stream()
.filter(s -> {
System.out.println("filter: " + s);
return s.length() <= 3;
})
.map(s1 -> {
System.out.println("map: " + s1);
return s1.toUpperCase();
})
.sorted()
.forEach(x -> {
System.out.println("forEach: " + x);
});
}filter: one
map: one
filter: two
map: two
filter: three
forEach: ONE
forEach: TWOВ отличие от предыдущего примера, добавление sorted() меняет порядок выполнения:
- Для каждого элемента сначала выполняется
filter, затемmap. sorted()необходимо увидеть все элементы, чтобы выполнить сортировку.- Порядок вывода в
forEach()соответствует результату сортировки.
Таким образом, операция sorted() создает “точку синхронизации”, когда необходимо сначала обработать все элементы до завершения пайплайна. Это может быть полезно в некоторых случаях, но может и замедлить обработку, особенно для больших наборов данных.
Spliterator
В основе всех коллекций в Java лежит интерфейс Iterator, который позволяет последовательно перебирать элементы. Однако для работы с потоками данных в Stream API используется более мощный механизм — Spliterator, своего рода “итератор на стероидах”. Его ключевая особенность — возможность разделять данные для независимой обработки разными потоками.
Методы Spliterator
Spliterator описывает 4 основных метода:
long estimateSize()Возвращает приблизительное количество оставшихся элементов в коллекции.tryAdvance(Consumer)Позволяет обработать следующий элемент коллекции, применяя к нему функциюConsumer. Если элемент существует, возвращаетtrue, в противном случае —false.int characteristics()Возвращает набор битовых флагов, описывающих характеристики текущегоSpliterator. Эти флаги помогают оптимизировать работу с потоком, учитывая особенности данных, такие как порядок элементов или уникальность.Spliterator<T> trySplit()Этот метод пытается разделить текущийSpliteratorна две части. Он возвращает новыйSpliterator, который будет обрабатывать одну часть данных, а исходныйSpliteratorуменьшает свой размер, обрабатывая оставшуюся часть. Если разделение невозможно, возвращаетсяnull.
Характеристики Spliterator
Spliterator обладает набором характеристик, которые описывают данные, с которыми он работает. Эти характеристики помогают Stream API более эффективно планировать и выполнять операции, особенно при параллельной обработке. Вот основные из них:
ORDERED: Элементы имеют определённый порядок, который должен сохраняться.DISTINCT: Все элементы уникальны, что определяется с помощью методаequals().SORTED: Элементы уже отсортированы.SIZED: Размер источника данных известен заранее.NONNULL: Все элементы гарантированно не равныnull.IMMUTABLE: Элементы не могут быть изменены во время обработки.CONCURRENT: Данные могут изменяться другими потоками без влияния на работуSpliterator.SUBSIZED: Все дочерниеSpliteratorбудут знать точный размер данных, которые им остались для обработки.
Эти характеристики помогают в оптимизации потоков. Например, если данные уже отсортированы (SORTED), их не нужно сортировать повторно. Или если коллекция содержит уникальные элементы (DISTINCT), можно избежать дополнительных проверок на уникальность.
Каждая операция в потоке может изменить эти характеристики. Например, операция map() обычно сбрасывает флаги SORTED и DISTINCT, так как преобразование элементов может нарушить их сортировку или уникальность. Однако флаг SIZED останется, поскольку операция map() не изменяет количество элементов в потоке.
Параллельное выполнение
Java Stream API предоставляет возможность параллельной обработки данных, что может значительно повысить производительность на многоядерных процессорах. Однако важно помнить, что параллельное выполнение может добавить сложность и накладные расходы, такие как управление потоками и синхронизация данных. Поэтому использование параллельных потоков должно быть тщательно обосновано и применяться только в случаях, когда ожидается реальная выгода от параллелизации.
Для запуска потоков в параллельном режиме можно использовать методы parallelStream() или parallel(). По умолчанию потоки выполняются последовательно, но с явным вызовом одного из этих методов поток переключается в параллельный режим.
Для разделения коллекций на части, которые обрабатываются параллельно, Java использует Spliterator и его метод trySplit(). Этот метод разделяет данные на подзадачи, которые затем могут быть распределены между несколькими потоками. Каждая часть обрабатывается независимо, и результаты объединяются после завершения работы всех потоков.
С точки зрения выполнения, параллельная обработка потоков похожа на последовательную. Разница заключается в том, что вместо одного набора операций используется несколько их копий — каждая копия выполняется на своем сегменте данных. Например, операции фильтрации, преобразования и агрегации применяются параллельно к каждому фрагменту данных, и по завершении результаты собираются в единый итог.
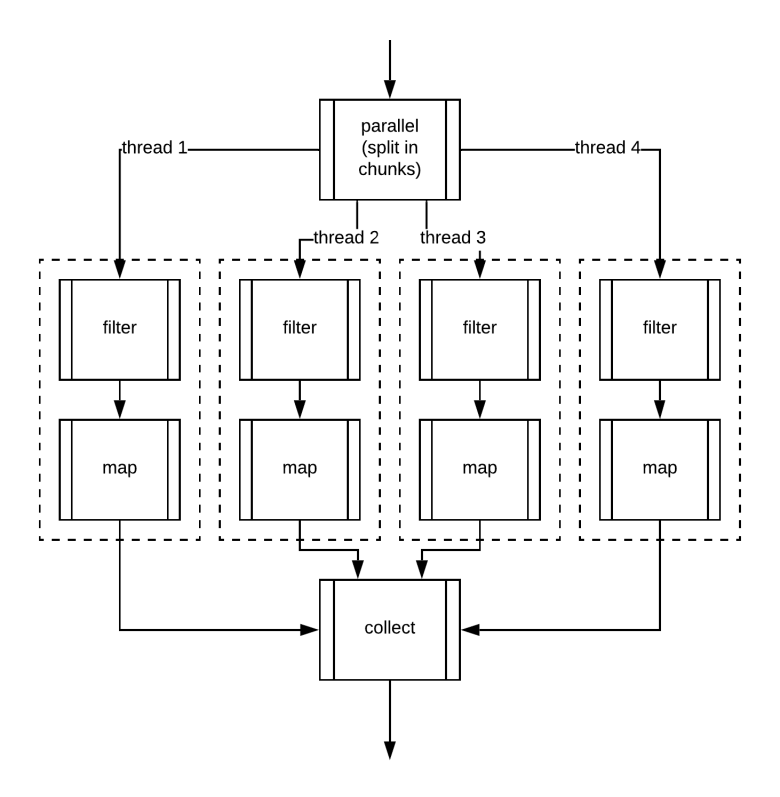
Место расположение .parallel() в Pipline
Может возникнуть вопрос: важно ли, на каком этапе пайплайна вызывается метод parallel()?

Ответ — нет, расположение метода в цепочке не влияет на поведение потока. Вызов parallel() лишь устанавливает характеристику CONCURRENT, что переводит поток в параллельный режим. Аналогично, вызов метода sequential() отменяет эту характеристику и возвращает поток в последовательный режим.
Java использует ForkJoinPool для распределения задач параллельных потоков. Это общий пул потоков, где задачи разбиваются на более мелкие фрагменты и распределяются между потоками. Такой же подход применяется и в CompletableFuture. При необходимости можно указать свой пул потоков, если текущий пул перегружен или необходимо изменить его поведение.
Что же такое Stream?
В основе Stream API лежит концепция потоков, которые представляют собой последовательность операций, выполняемых над данными. Потоки позволяют обрабатывать коллекции данных на более высоком уровне абстракции, предоставляя удобные и эффективные средства для манипуляции с данными.
Основные свойства потоков:
- Декларативность: Потоки в Java позволяют описывать что нужно сделать с данными, а не как это должно быть реализовано. Вместо явного использования циклов и условий, разработчик может задать набор операций, которые Java выполнит под капотом. Такой подход повышает читаемость и простоту кода, поскольку скрывает сложные детали реализации.
- Ленивость: Операции в потоке не выполняются сразу — они “откладываются” до тех пор, пока не будет вызвана терминальная операция. Это позволяет Java оптимизировать выполнение операций, обрабатывая данные по мере необходимости и избегая лишней работы.
- Одноразовость: Потоки можно использовать только один раз. Как только была вызвана терминальная операция, поток считается исчерпанным и больше не может быть использован. Если необходимо выполнить другую операцию над теми же данными, нужно создать новый поток.
- Параллельность: Потоки по умолчанию выполняются последовательно, но их можно легко распараллелить, используя метод
parallelStream()илиparallel(). Это позволяет значительно ускорить обработку больших наборов данных на многоядерных системах. Параллельные потоки автоматически разделяют данные на части и распределяют задачи между несколькими потоками, обеспечивая более эффективное использование ресурсов процессора.
Методы Stream
Теперь, когда мы разобрались с основными принципами работы потоков, давайте рассмотрим, как можно создать поток и работать с ним, используя различные методы Stream API.
Создание Stream
Существует несколько способов создать поток в Java. Например, можно получить поток из коллекции с помощью метода stream() или создать его из массива с помощью метода Arrays.stream(). Как только поток создан, над ним можно выполнять различные операции, которые предоставляет Stream API.
Из коллекции
Поток можно создать из любой коллекции, такой как список или множество, используя метод stream().
Collection<Integer> list = new ArrayList<>();
Stream<Integer> stream = list.stream();Из массива
Для создания потока из массива можно воспользоваться методом Arrays.stream().
int[] numbers = {1, 2, 3};
Stream<Integer> stream = Arrays.stream(numbers).boxed();int, поток можно дополнительно преобразовать в объектный тип с помощью метода boxed().Из строки
Для создания потока символов строки используется метод chars(), который возвращает поток типа IntStream.
String str = "Hello";
IntStream stream = str.chars();Из файла
Поток можно создать из строк файла с помощью метода Files.lines(). Этот метод считывает файл построчно и возвращает поток строк.
Path path = Paths.get("file.txt");
Stream stream = Files.lines(path);Многие методы, такие как Files.lines(), Files.find(), Pattern.splitAsStream(), и другие, используют Iterator для получения данных, которые затем преобразуются в Spliterator для параллельной обработки. Однако Iterator не содержит информации о размере данных, что может негативно сказаться на эффективности параллельной обработки. Без точной информации о размере, Spliterator не может эффективно разбивать данные на части, что может привести к снижению производительности параллельных операций.
Генерирование
Поток можно также создать с помощью метода Stream.generate(), который использует интерфейс Supplier. При каждом вызове Supplier возвращает новое значение. Это удобно для генерации бесконечных потоков данных.
Stream stream = Stream.generate(() -> new Random().nextInt());Билдер
Для более гибкого создания потока можно использовать Stream.Builder. Он позволяет поэтапно добавлять элементы в поток, а затем создать поток с помощью метода build().
Stream.Builder builder = Stream.builder();
builder.add(1);
builder.add(2);
builder.add(3);
Stream stream = builder.build();
Промежуточные методы
После того как мы разобрались с созданием потоков, давайте рассмотрим промежуточные методы Stream API, которые позволяют обрабатывать элементы в потоке и формировать новые потоки для дальнейших операций.
filter(Predicate)
Метод filter() используется для создания нового потока, который содержит только те элементы, которые удовлетворяют определённому условию. Этот метод принимает функциональный интерфейс Predicate, который задаёт условие для фильтрации.
Пример: Фильтрация списка чисел, оставляя только чётные числа.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Stream<Integer> evenNumbersStream = numbers.stream()
.filter(n -> n % 2 == 0);
evenNumbersStream.forEach(System.out::println); // prints 2, 4, 6, 8, 10Характеристики:
- Stateless: Операция без состояния, так как каждый элемент проверяется независимо от других.
ORDERED: Обычно сохраняется порядок элементов.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Сохраняются, если были в исходномSpliterator.SIZED,SUBSIZED: Теряются, так как количество элементов после фильтрации заранее неизвестно.
map(Function)
Метод map() преобразует каждый элемент потока с помощью функции, переданной в виде лямбда-выражения или ссылки на метод. В результате создаётся новый поток, содержащий преобразованные элементы, без изменения исходного потока.
Пример: Преобразование строк в их длины.
List<String> words = Arrays.asList("apple", "banana", "orange", "peach");
Stream<Integer> lengthsStream = words.stream()
.map(String::length);
lengthsStream.forEach(System.out::println); // prints 5, 6, 6, 5Характеристики:
- Stateless: Операция без состояния, поскольку каждый элемент преобразуется независимо.
ORDERED: Порядок сохраняется.DISTINCT,SORTED: Могут быть потеряны, так как преобразованные данные могут нарушить уникальность и порядок.SIZED,SUBSIZED: Обычно сохраняются.NONNULL: Может быть потеряно, если преобразованное значение допускаетnull.IMMUTABLE,CONCURRENT: Сохраняются.
flatMap()
Метод flatMap() используется для преобразования каждого элемента потока в поток и “разворачивания” всех потоков в один общий поток. Это особенно полезно для работы с вложенными структурами данных, такими как списки списков.
Пример: Преобразование списка списков в один плоский поток.
List<List<Integer>> listOfLists = Arrays.asList(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9)
);
Stream<Integer> flattenedStream = listOfLists.stream()
.flatMap(Collection::stream);
flattenedStream.forEach(System.out::println); // prints 1, 2, 3, 4, 5, 6, 7, 8, 9Характеристики:
- Stateless: Операция без состояния, так как каждый элемент разворачивается независимо.
ORDERED: Обычно сохраняется.DISTINCT,SORTED: Теряются, так как объединённые потоки могут нарушить уникальность и порядок.SIZED,SUBSIZED: Теряются, поскольку количество элементов после разворачивания заранее неизвестно.NONNULL: Может быть потеряно, если один из вложенных потоков содержитnull.IMMUTABLE,CONCURRENT: Сохраняются.
Метод map() преобразует каждый элемент потока в новый элемент. В отличие от него, метод flatMap() преобразует каждый элемент в поток и затем "разворачивает" все эти потоки в один плоский поток. Это делает flatMap() полезным для работы с вложенными структурами данных, такими как списки списков.
distinct()
Метод distinct() возвращает новый поток, содержащий только уникальные элементы исходного потока. Уникальность элементов определяется на основе их естественного порядка (метод equals()), если это объекты, или с использованием переданного компаратора. Эта операция полезна, когда необходимо устранить дубликаты из набора данных.
Пример: Удаление дубликатов из потока чисел.
List<Integer> numbers = Arrays.asList(1, 2, 3, 2, 1, 4, 5, 3, 5);
List<Integer> uniqueNumbers = numbers.stream()
.distinct()
.collect(Collectors.toList());
System.out.println(uniqueNumbers); // prints [1, 2, 3, 4, 5]Характеристики:
- Stateful: Требует знания всех элементов потока для определения уникальности.
ORDERED: Порядок сохраняется, если исходный поток был упорядочен.DISTINCT: Всегда устанавливается после выполнения операции.SORTED: Сохраняется, если исходный поток был отсортирован.SIZED,SUBSIZED: Теряются, так как количество уникальных элементов заранее неизвестно.NONNULL,IMMUTABLE,CONCURRENT: Сохраняются, если эти характеристики были в исходном потоке.
limit(n)
Метод limit(n) возвращает новый поток, содержащий не более n элементов исходного потока. Если исходный поток содержит меньше элементов, поток будет содержать все доступные элементы. Этот метод полезен для ограничения размера выборки.
Пример: Ограничение потока до первых пяти элементов.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> limitedNumbers = numbers.stream()
.limit(5)
.collect(Collectors.toList());
System.out.println(limitedNumbers); // prints [1, 2, 3, 4, 5]Характеристики:
- Stateful: Операция требует, чтобы поток знал точное количество элементов для ограничения.
ORDERED: Порядок сохраняется, если исходный поток был упорядочен.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Сохраняются, если эти характеристики были в исходном потоке.SIZED,SUBSIZED: Могут быть сохранены, если исходный поток был известен и его размер превышает значение limit. Если размер был неизвестен, эти характеристики теряются.
skip(n)
Метод skip(n) возвращает новый поток, исключающий первые n элементов исходного потока. Если исходный поток содержит меньше n элементов, возвращённый поток будет пустым. Этот метод удобен, если нужно пропустить определённое количество элементов в начале потока.
Пример: Пропуск первых пяти элементов потока.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> skippedNumbers = numbers.stream()
.skip(5)
.collect(Collectors.toList());
System.out.println(skippedNumbers); // prints [6, 7, 8, 9, 10]Характеристики:
- Stateful: Операция требует отслеживания количества пропущенных элементов.
ORDERED: Порядок сохраняется, если исходный поток был упорядочен.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Сохраняются, если эти характеристики были в исходном потоке.SIZED,SUBSIZED: Могут быть потеряны, если количество пропускаемых элементов неизвестно или исходный поток не был размерным (SIZEDилиSUBSIZED). Если размер исходного потока известен и превышает значениеskip, эти характеристики сохраняются.
sorted()
Метод sorted() создает новый поток, содержащий элементы исходного потока, отсортированные в естественном порядке (для объектов, реализующих интерфейс Comparable), либо в порядке, заданном переданным компаратором. Эта операция полезна для сортировки элементов в потоке перед дальнейшими операциями, такими как фильтрация или агрегация.
Пример: Сортировка списка строк в алфавитном порядке.
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");
List<String> sortedNames = names.stream()
.sorted()
.collect(Collectors.toList());
System.out.println(sortedNames); // prints ["Alice", "Bob", "Charlie", "David"]Comparable, возникнет исключение ClassCastException. Чтобы избежать этого, можно передать свой компаратор в метод sorted():Характеристики:
- Stateful: Операция требует отслеживания всех элементов для выполнения сортировки.
ORDERED: Устанавливается после сортировки, так как элементы отсортированы.DISTINCT: Сохраняется, если был в исходномSpliterator.SORTED: Всегда устанавливается, так как поток упорядочен.SIZED,SUBSIZED: Сохраняются, если были в исходномSpliterator.NONNULL,IMMUTABLE,CONCURRENT: Сохраняются, если были в исходномSpliterator.
takeWhile(Predicate)
Метод takeWhile() создает новый поток, который включает элементы исходного потока до тех пор, пока они удовлетворяют указанному условию (Predicate). Как только условие становится ложным, поток завершается. Если первый элемент не соответствует предикату, возвращается пустой поток.
Пример: Возвращение чисел, меньших 5, из потока чисел.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> takenNumbers = numbers.stream()
.takeWhile(n -> n < 5)
.collect(Collectors.toList());
System.out.println(takenNumbers); // prints [1, 2, 3, 4]Характеристики:
- Stateful: Операция требует отслеживания элементов потока до тех пор, пока выполняется условие.
ORDERED: Сохраняется, если исходный поток был упорядочен.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Сохраняются, если были в исходномSpliterator.SIZED,SUBSIZED: Могут быть потеряны, так как количество элементов после выполненияtakeWhile()неизвестно.
dropWhile(Predicate)
Метод dropWhile() возвращает новый поток, исключающий все элементы исходного потока, которые удовлетворяют указанному условию (Predicate), до тех пор, пока не встретится элемент, не соответствующий условию. Как только первый элемент не удовлетворяет предикату, все последующие элементы включаются в новый поток, независимо от того, соответствуют ли они условию.
Пример: Исключение чисел, меньших 5, из потока. В данном примере все числа меньше 5 будут пропущены, а поток начнется с 5.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> droppedNumbers = numbers.stream()
.dropWhile(n -> n < 5)
.collect(Collectors.toList());
System.out.println(droppedNumbers); // prints [5, 6, 7, 8, 9, 10]Характеристики:
- Stateful: Операция требует отслеживания элементов до тех пор, пока они соответствуют условию.
ORDERED: Сохраняется, если исходный поток был упорядочен.DISTINCT,SORTED,NONNULL,IMMUTABLE,CONCURRENT: Сохраняются, если были в исходномSpliterator.SIZED,SUBSIZED: Могут быть потеряны, так как количество элементов после выполненияdropWhile()заранее неизвестно.
peek(Consumer)
Метод peek() позволяет добавить промежуточную операцию в поток, которая выполняет действия над каждым элементом, не изменяя сам поток. Это полезно для таких задач, как логирование, отладка или профилирование.
Пример: Логирование элементов потока.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream()
.peek(System.out::println)
.collect(Collectors.toList());В этом примере метод peek() выводит каждый элемент на консоль, но сам поток и его элементы остаются неизменными.
Характеристики:
- Stateless: Операция выполняется для каждого элемента независимо.
ORDERED,DISTINCT,SORTED,SIZED,SUBSIZED,NONNULL,IMMUTABLE,CONCURRENT: Все характеристики сохраняются, так как операция не изменяет элементы потока.
Метод peek() полезен для выполнения операций, не изменяющих элементы потока, таких как логирование и отладка. Однако его неправильное использование может привести к нежелательным результатам, особенно при параллельной обработке.
Поскольку peek() — это промежуточная операция, изменения элементов внутри нее могут вызвать непредсказуемое поведение. В общем случае, рекомендуется применять peek() только для вспомогательных задач, таких как отладка. Для изменения элементов лучше использовать map().
Терминальные методы
Терминальные методы в Stream API запускают обработку потока и завершают его. После их вызова поток больше не может быть использован. Рассмотрим основные терминальные методы, часто используемые в Java.
forEach(Consumer)
Метод forEach() применяет переданную функцию (объект интерфейса Consumer) к каждому элементу потока.
Не рекомендуется использовать в продакшене, так как он не возвращает результат, а работает только за счёт "побочных эффектов". Это делает его неудобным и потенциально проблемным при параллельном выполнении потоков, где могут возникнуть сложности с синхронизацией.
Пример плохого использования forEach():
public int getSum (Stream<Integer> s) {
int [] sum = new int [1];
s.forEach ( i -> sum [0] += i);
return sum [0];
}Пример побочного результата выполнения метода forEach. Никогда так не делайте.
Этот пример показывает побочный эффект: модификацию внешнего состояния (sum[0]). Если применить параллельное выполнение, возникнут проблемы синхронизации, так как несколько потоков могут одновременно изменять один и тот же элемент массива, что приведёт к некорректным результатам.
сollect(Collector)
Метод collect() — это один из самых полезных и часто используемых терминальных методов. Он применяется для преобразования элементов потока в определённую структуру данных (например, List, Set, Map), строку или агрегированное значение.
Stream<String> stream = Stream.of("Alice", "Bob", "Charlie");
List<String> list = stream.collect(Collectors.toList());
System.out.println(list); // выводит [Alice, Bob, Charlie]Метод collect() собирает элементы в список, но он может быть настроен для сбора данных в любые другие структуры, такие как множества или строки.
Этот метод принимает объект типа Collector, который определяет, как именно будут собраны элементы.
Класс Collector
Интерфейс Collector инкапсулирует процесс комбинирования элементов потока в одну итоговую структуру.

Класс Collectors содержит набор предопределённых статических методов для выполнения общих операций, таких как преобразование элементов в списки, множества и другие структуры данных.
Некоторые популярные методы класса Collectors:
toList(): Возвращает коллектор, который собирает элементы в список.toSet(): Собирает элементы в множество.joining(): Объединяет элементы потока в одну строку.counting(): Подсчитывает количество элементов в потоке.
Следующий пример показывает, как можно создать собственный коллектор, который накапливает элементы в список. В данном случае используется лямбда-выражение для определения поведения коллектора.
Stream<?> stream;
List<?> list = stream.collect(Collectors.toList());
//Коллектор выше аналогичен данному коду
list = stream.collect(
() -> new ArrayList<>(), // определяем структуру
(list, t) -> list.add(t), // определяем, как добавлять элементы
(l1, l2) -> l1.addAll(l2) // и как объединять две структуры в одну
);Optional<T> findFirst()
Метод findFirst() возвращает первый элемент потока в виде Optional<T>. Этот метод полезен, когда важно получить именно первый элемент (например, при упорядоченном потоке), обычно в сочетании с фильтрацией.
Пример: Извлечение первого элемента, удовлетворяющего условию.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> first = numbers.stream()
.filter(n -> n > 3)
.findFirst();
System.out.println(first.get()); // выводит 4Optional<T> findAny()
Метод findAny() возвращает любой элемент потока в виде Optional<T>. В однопоточных сценариях его поведение идентично findFirst(), но при параллельной обработке потока он может вернуть любой элемент, что может улучшить производительность за счёт отсутствия необходимости ожидания первого элемента в последовательности.
findAny() может быть полезен, когда порядок элементов не важен, а нужно просто получить результат как можно быстрее.
Дополнительная информация о Optional
Методы, такие как findFirst() и findAny(), возвращают объект типа Optional<T>, что помогает избегать возможного NullPointerException, обрабатывая ситуации, когда результат может отсутствовать. Использование Optional позволяет безопасно работать с отсутствующими значениями.
Подробнее о том, как работать с Optional, можно узнать в гайде по Optional в Java, который подробно объясняет, как снизить вероятность возникновения NullPointerException.
reduce()
Метод reduce() используется для объединения всех элементов потока в одно итоговое значение. Он отличается от метода collect() тем, что работает с бинарной ассоциативной функцией, которая принимает два значения и возвращает одно. reduce() особенно полезен для таких задач, как суммирование, нахождение максимального или минимального значения в потоке.
Пример: Суммирование чисел с помощью reduce().
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> sum = numbers.stream().reduce((a, b) -> a + b);
System.out.println(sum.get());Метод возвращает Optional<T>, так как поток может быть пустым, и это позволяет избежать ошибок при работе с отсутствующими элементами.
Для упрощения работы можно использовать версию reduce() с начальными значениями, что позволяет избежать работы с Optional.
int sum = numbers.stream().reduce(0, Integer::sum);
System.out.println(sum); // выводит 15anyMatch(Predicate)
Метод anyMatch() проверяет, соответствует ли хотя бы один элемент потока заданному условию (предикату). Если хотя бы один элемент удовлетворяет предикату, возвращается true, иначе — false.
Пример: Проверка, содержит ли поток чётные числа.
boolean hasEven = numbers.stream().anyMatch(n -> n % 2 == 0);
System.out.println(hasEven); // выводит trueallMatch(Predicate)
Метод allMatch() возвращает true, если все элементы потока удовлетворяют заданному предикату. Если хотя бы один элемент не соответствует предикату, метод возвращает false.
Пример: Проверка, являются ли все элементы потока положительными числами.
boolean allPositive = numbers.stream().allMatch(n -> n > 0);
System.out.println(allPositive); // выводит trueShort-circuiting
Операции “короткого замыкания” в Stream API позволяют прекращать обработку потока данных, как только найден первый подходящий результат, не обрабатывая оставшиеся элементы. Это существенно повышает производительность, особенно при работе с большими потоками, поскольку исключает необходимость обработки всех элементов.
Примерами операций короткого замыкания могут служить методы anyMatch(), allMatch(), noneMatch(), findFirst(), findAny().
Поведение операций короткого замыкания может меняться в зависимости от того, является поток последовательным или параллельным:
- В последовательных потоках методы, такие как
findFirst()илиfindAny(), возвращают первый элемент по порядку, так как обработка идёт последовательно. - В параллельных потоках метод
findAny()может вернуть любой элемент, потому что каждый поток обрабатывает свой сегмент данных независимо. Это позволяет завершить работу быстрее, не дожидаясь обработки всех элементов, как в последовательных потоках.
Продвинутые советы и использование
В этом разделе собраны продвинутые подходы и советы по работе со Stream API, которые помогут сделать код более гибким и безопасным.
Возвращать Stream<T> вместо коллекций
Одним из полезных подходов является возвращение потока Stream<T> вместо коллекции (List, Set и т.д.) в методах API. Это помогает защитить внутренние данные от модификации и предоставляет пользователю свободу выбора коллекции, в которую он хочет собрать данные.
public Stream<Worker> getWorkers() {
return workers.stream();
}Потребитель этого метода сможет сам выбрать, в какую структуру данных собрать поток:
List<Worker> workerList = service.getWorkers().collect(Collectors.toList());
Set<Worker> workerSet = service.getWorkers().collect(Collectors.toSet());Таким образом, вы обеспечиваете защиту данных и гибкость для пользователей вашего API.
Группировка элементов
Для сложной обработки данных часто требуется группировка элементов по какому-либо признаку. Для этого можно использовать метод collect() вместе с Collectors.groupingBy(). Этот метод позволяет группировать элементы по различным параметрам, а также производить дополнительные действия над сгруппированными данными.
Чтобы сгруппировать данные по какому-нибудь признаку, нам надо использовать метод collect() и метод Collectors.groupingBy().
Группировка по должности (в списки):
Map<String, List<Worker>> map1 = workers.stream()
.collect(Collectors.groupingBy(Worker::getPosition));Группировка по должности (во множества):
Map<String, Set<Worker>> map2 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition, Collectors.toSet()
)
);Подсчет количества рабочих на каждой должности:
Map<String, Long> map3 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition, Collectors.counting()
)
);Группировка по должности, интересуют только имена:
Map<String, Set<String>> map4 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition,
Collectors.mapping(
Worker::getName,
Collectors.toSet()
)
)
);Расчет средней зарплаты по должностям:
Map<String, Double> map5 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition,
Collectors.averagingInt(Worker::getSalary)
)
);Группировка по должности, где имена представлены в виде строки:
Map<String, String> map6 = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition,
Collectors.mapping(
Worker::getName,
Collectors.joining(", ", "{","}")
)
)
);Группировка по должности и возрасту:
Map<String, Map<Integer, List<Worker>>> collect = workers.stream()
.collect(
Collectors.groupingBy(
Worker::getPosition,
Collectors.groupingBy(Worker::getAge)
)
);Заключение
В целом, Stream API в Java — это мощный инструмент для обработки данных, который может кардинально изменить ваш подход к программированию. Он позволяет организовывать код в читаемые и компактные последовательности операций, что делает его идеальным для работы с большими объемами данных.
Вместе с тем, важно помнить, что он не подходит для всех задач. Если ваша задача не соответствует шаблону "источник-преобразование-сбор", возможно, стоит обратиться к другим инструментам Java.
В любом случае, понимание и умение использовать Stream API является важным навыком для каждого разработчика на Java, и безусловно, этот инструмент заслуживает времени, уделенного на его изучение.
